
Application of Neural Network Models and ANFIS for Water Level Forecasting of the Salve Faccha Dam in the Andean Zone in Northern Ecuador

Abstract
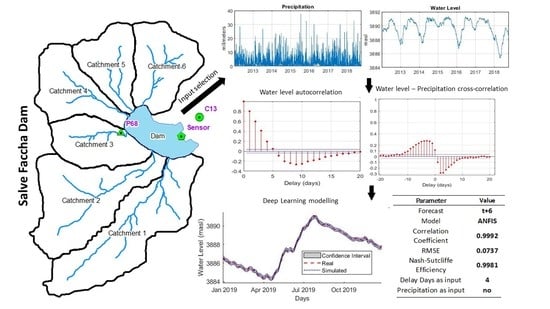
:
1. Introduction
2. Materials and Methods
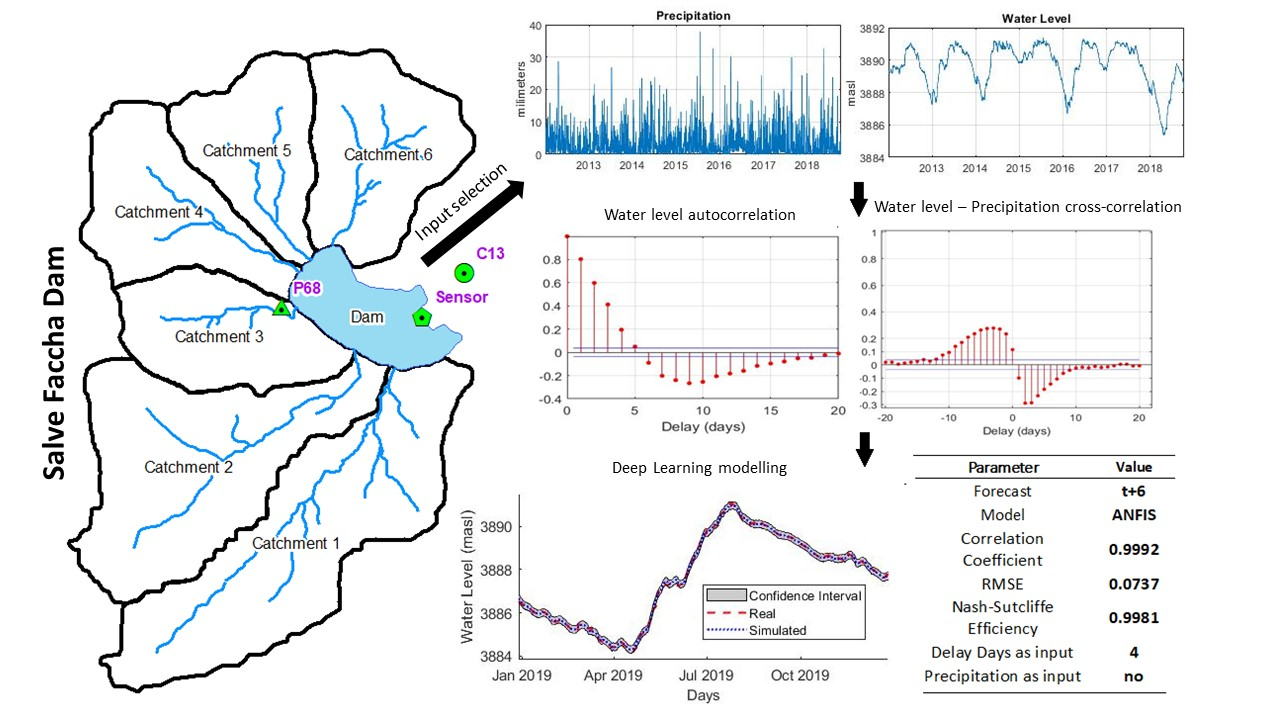
2.1. Area of Study
2.2. Generalities of Neural Networks and ANFIS
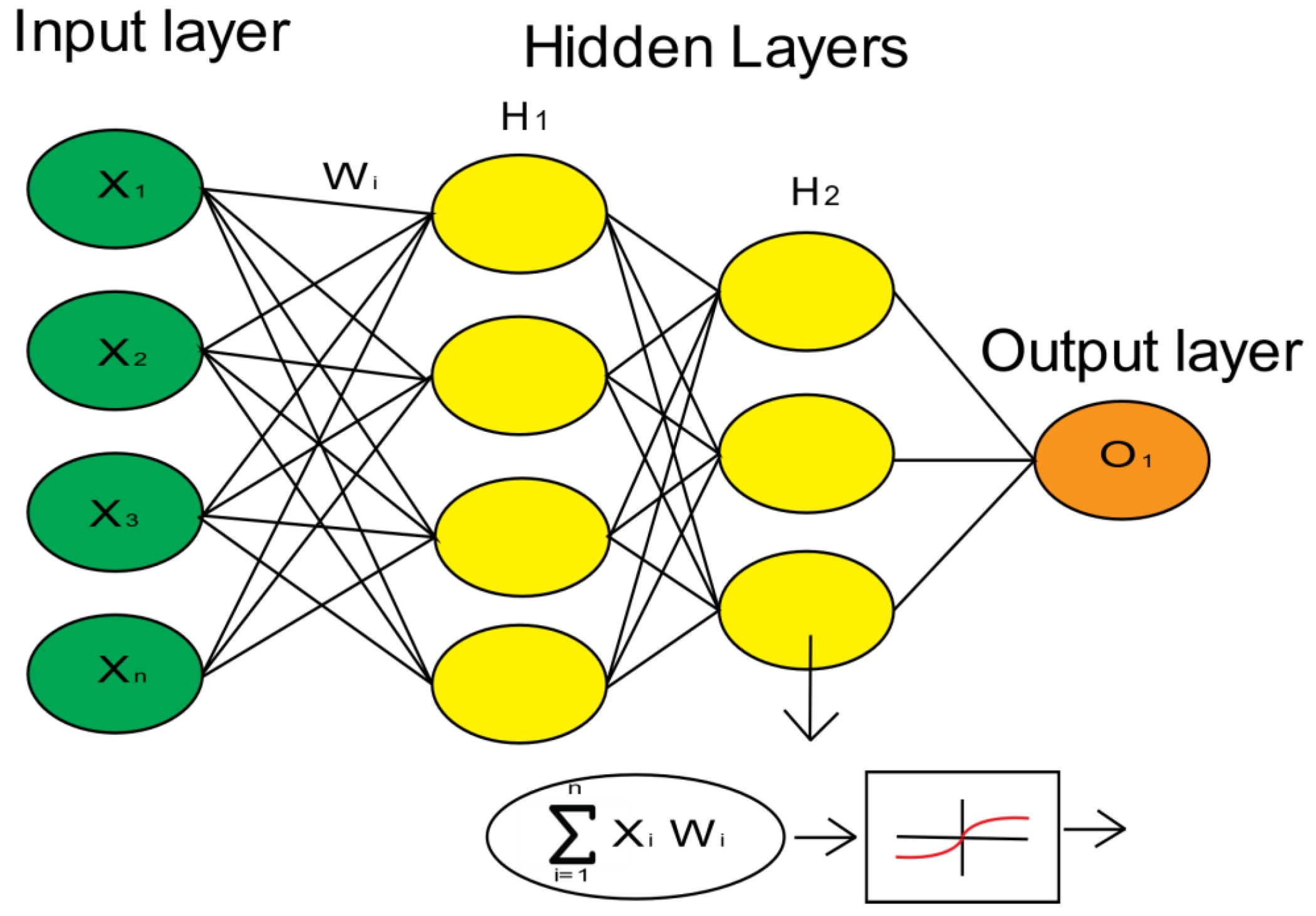
2.2.1. Neural Networks
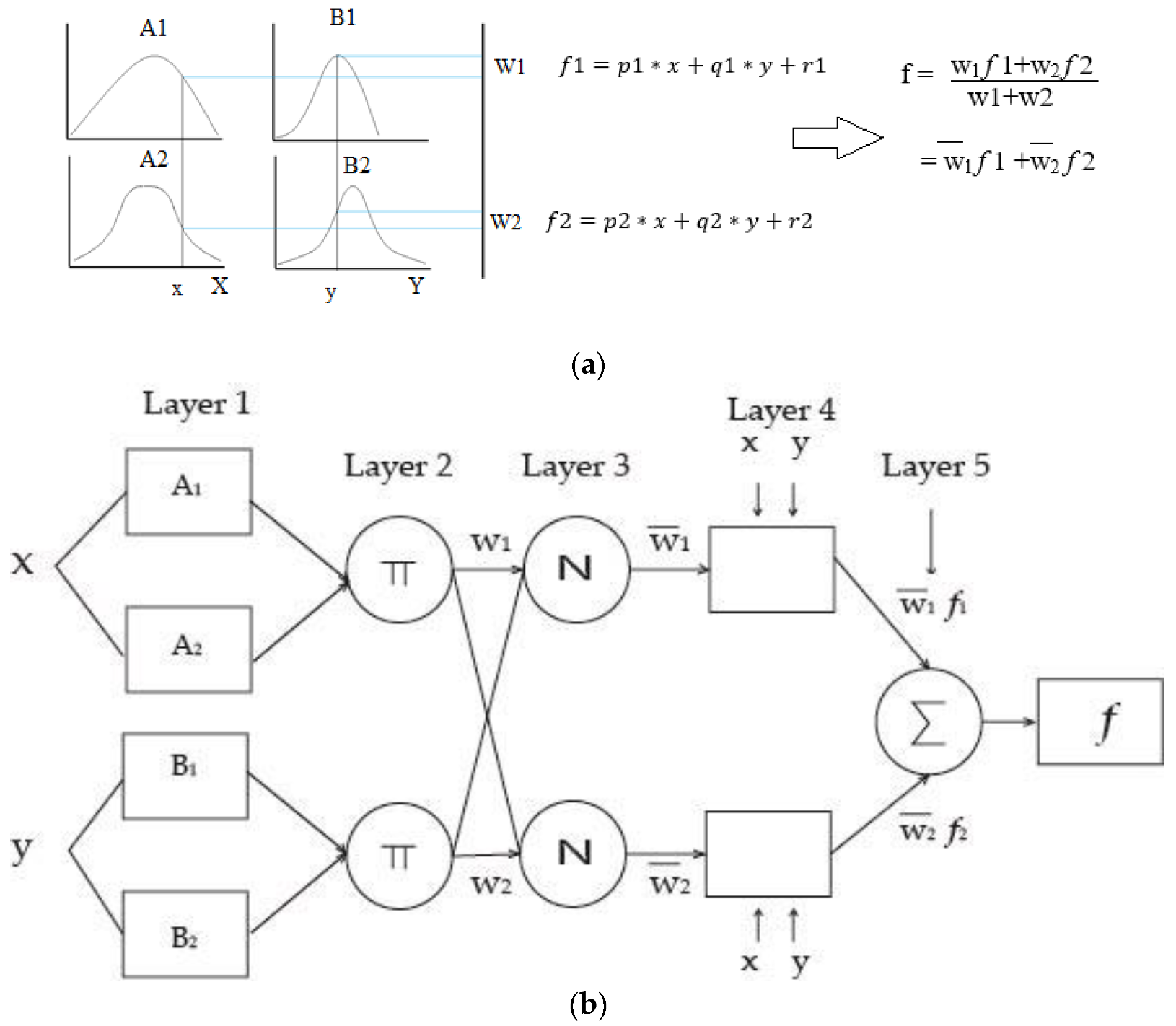
2.2.2. Functioning of ANFIS Model
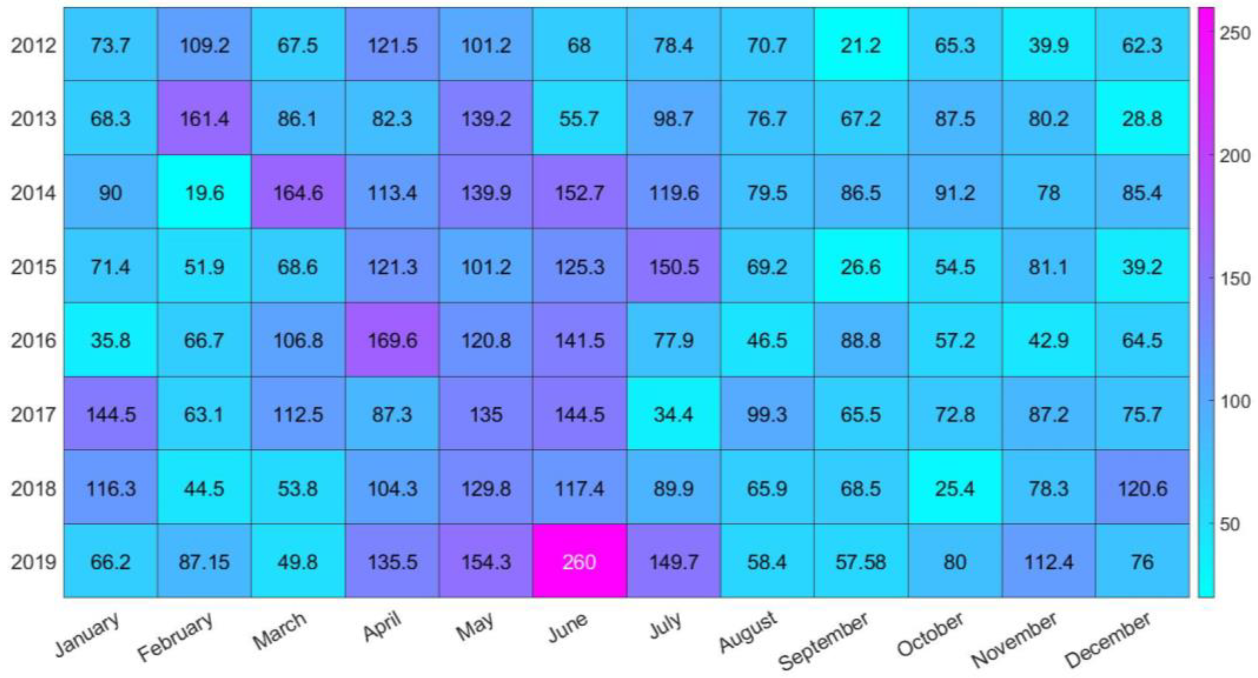
2.3. Data Pre-Processing
2.3.1. Quality Control of Data
2.3.2. Determination of Predictors and Delay as Input
2.3.3. Neural Network and ANFIS Models Configuration
2.3.4. Model Performance Criteria
2.4. Prediction Confidence Intervals Development
3. Results and Discussion
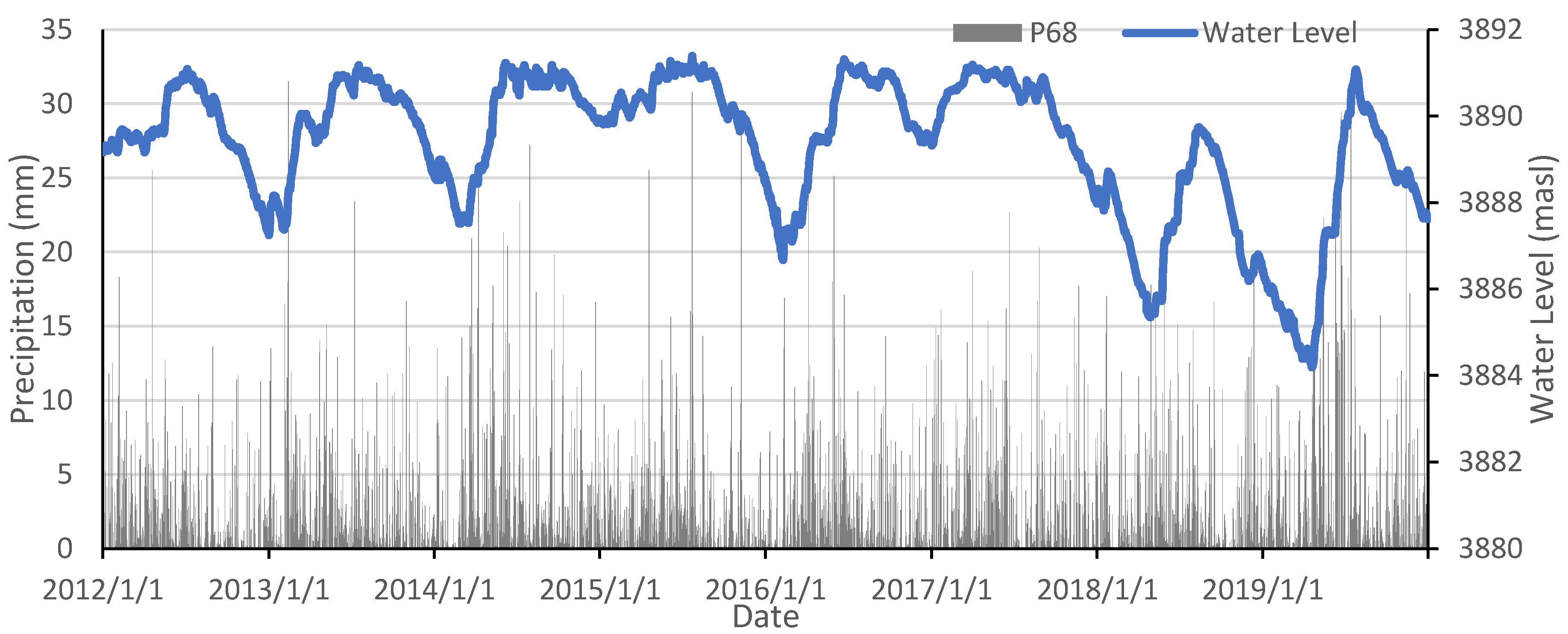
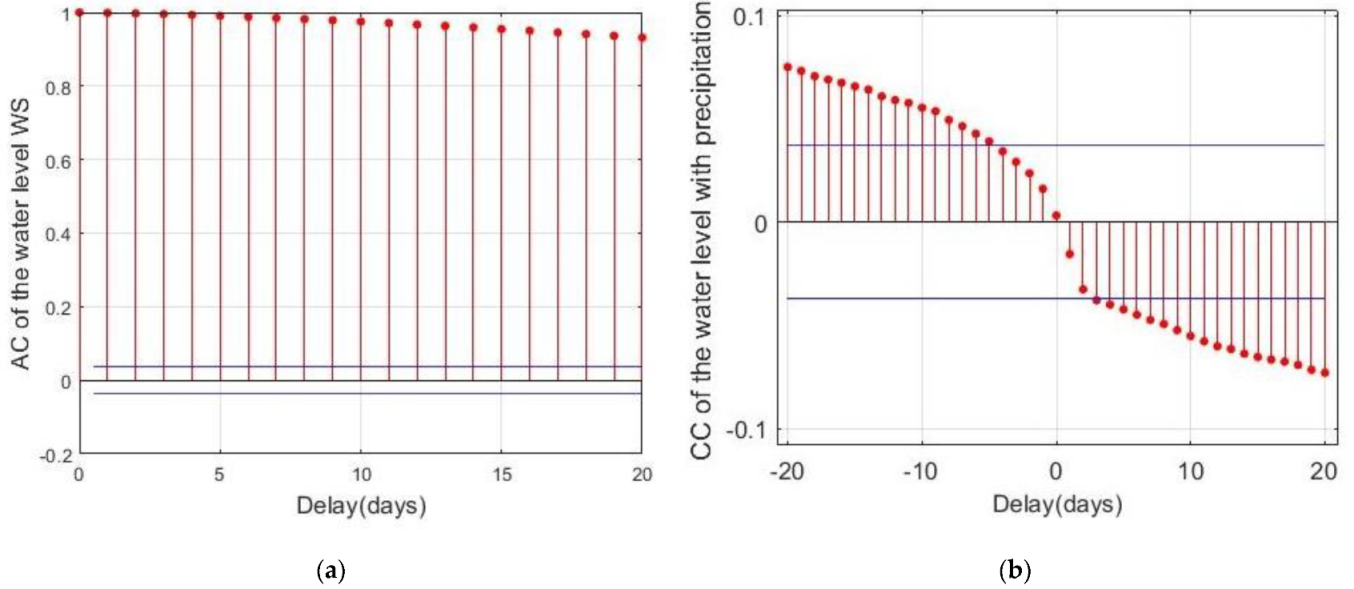
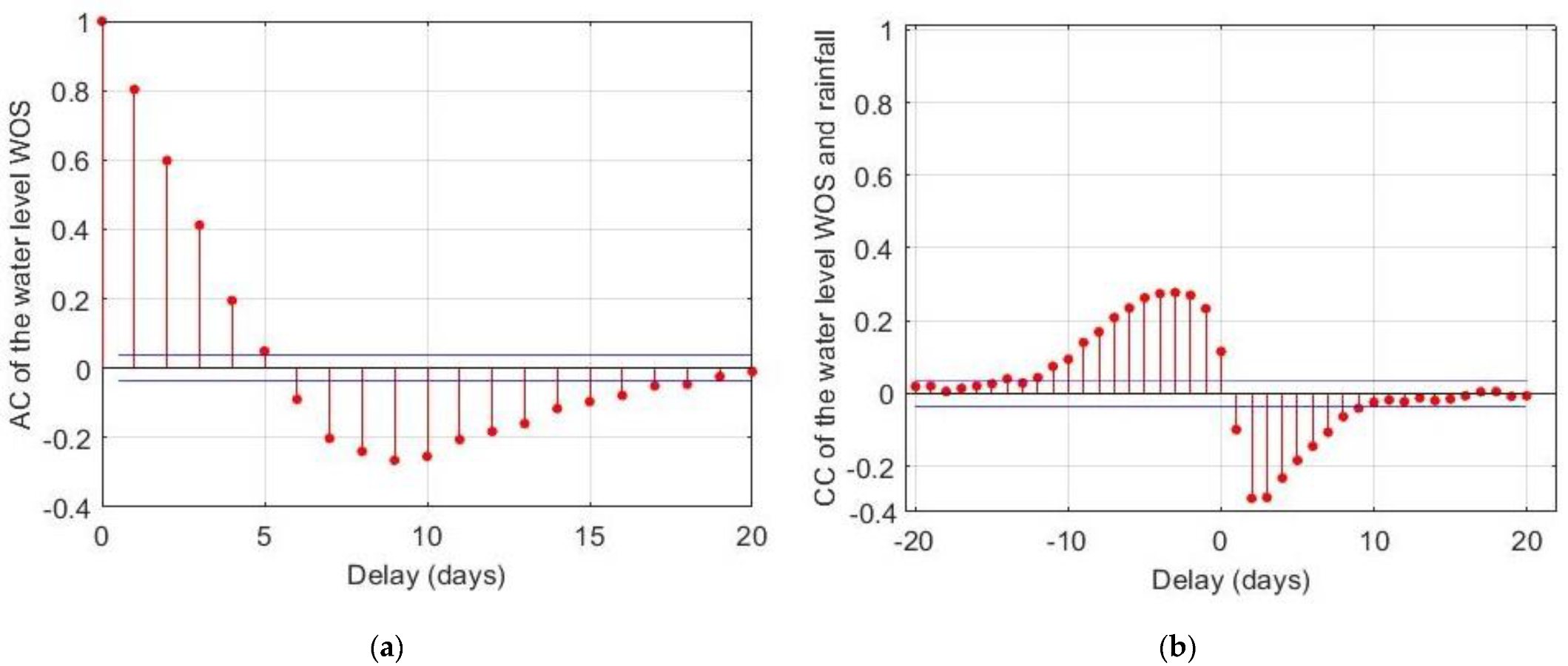
3.1. Selection of Predictors
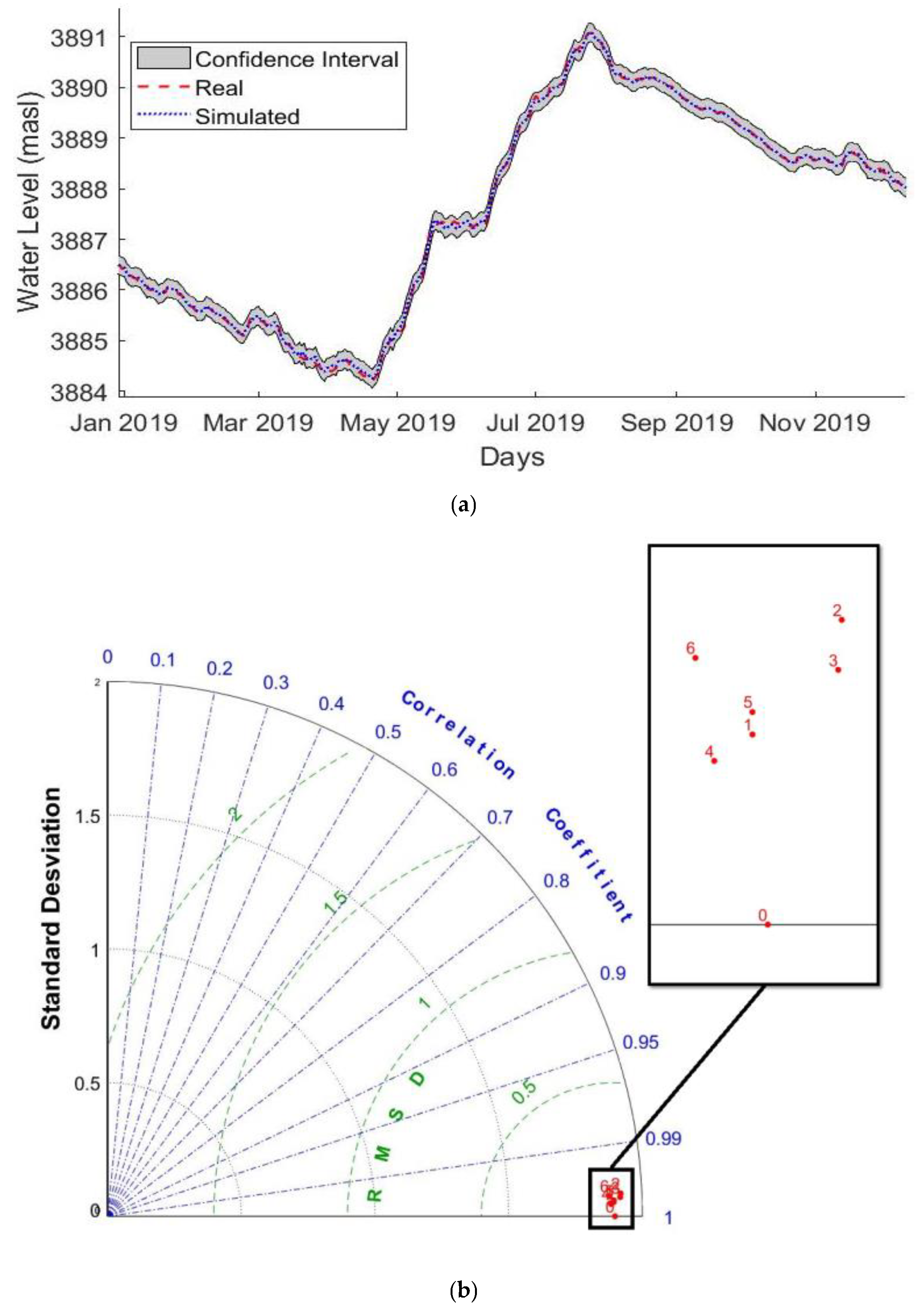
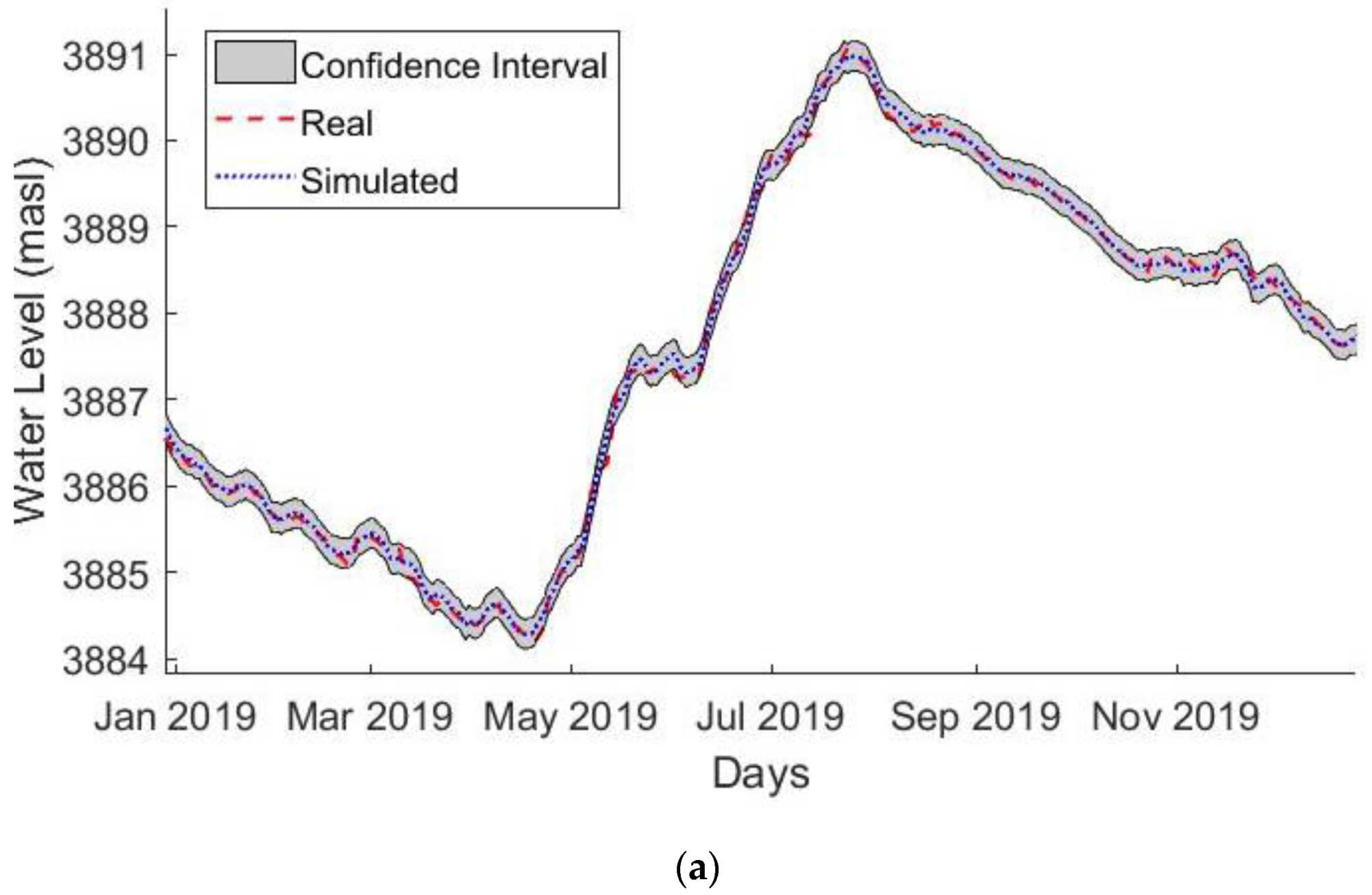
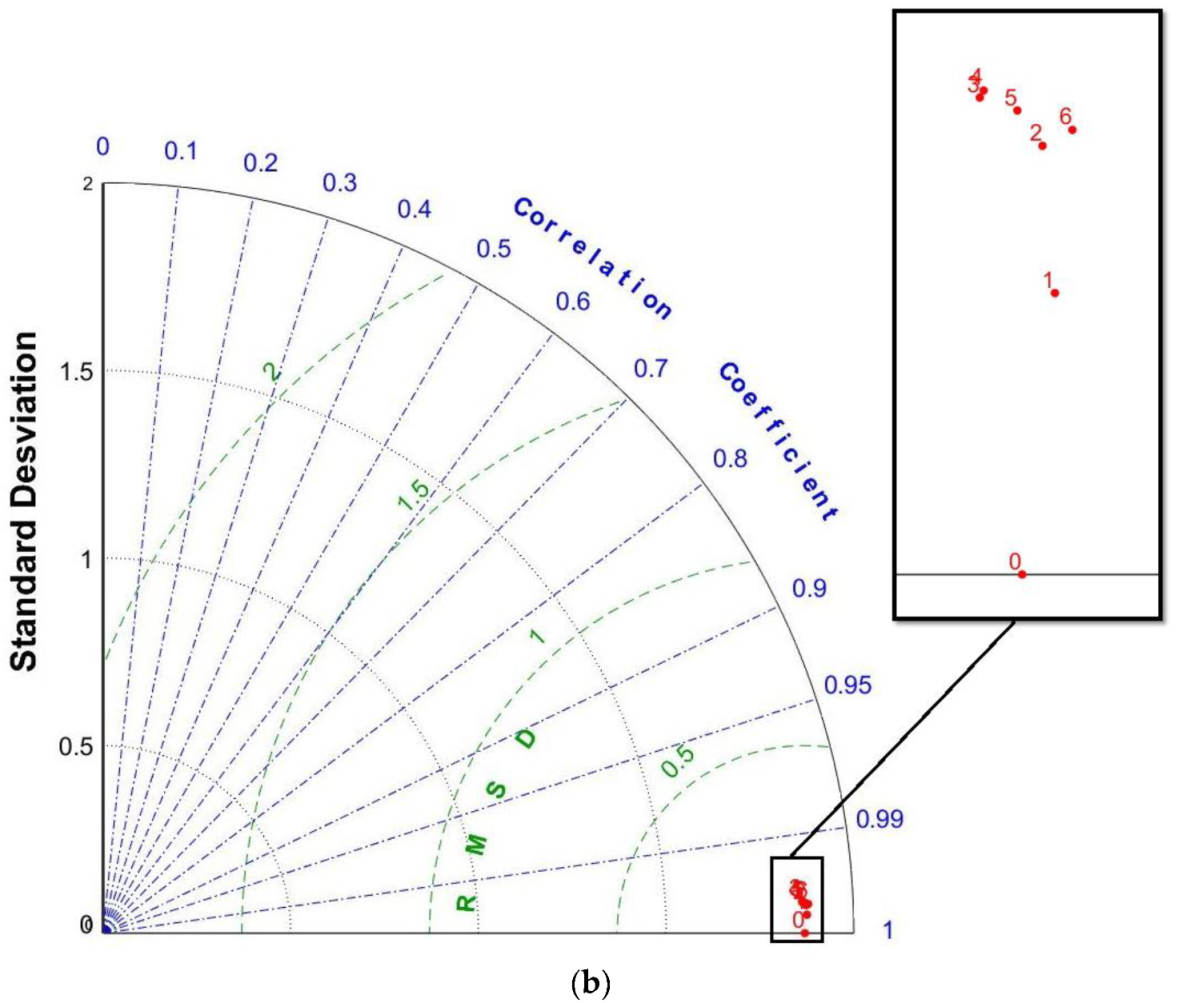
3.2. Neural Network Results
3.3. ANFIS Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Oyebode, O.; Stretch, D. Neural network modeling of hydrological systems: A review of implementation techniques. Nat. Resour. Model. 2018, 32, e12189. [Google Scholar] [CrossRef] [Green Version]
- Halff, A.H.; Halff, H.M.; Azmoodeh, M. Predicting runoff from rainfall using neural network. In Engineering Hydrolgy; American Society of Civil Engineers: New York, NY, USA, 1993; pp. 760–765. [Google Scholar]
- Zhu, M.-L.; Fujita, M.; Hashimoto, N. Application of neural networks to runoff prediction. In Climate Change Impacts on Water Resources, 3rd ed.; Panu, A., Singh, U., Eds.; Springer: Dordrecht, The Netherlands, 1994; Volume 10, pp. 205–216. [Google Scholar]
- Govindaraju, R. Artificial neural networks in hydrology. II: Hydrologic applications. J. Hydrol. Eng. 2000, 5, 124–137. [Google Scholar] [CrossRef]
- Herrera, M.; Torgo, L.; Izquierdo, J.; Pérez-García, R. Predictive models for forecasting hourly urban water demand. J. Hydrol. 2010, 387, 141–150. [Google Scholar] [CrossRef]
- Zubaidi, S.; Al-Bugharbee, H.; Ortega-Martorell, S.; Gharghan, S.; Olier, I.; Hashim, K.; Al-Bdairi, N.; Kot, P. A Novel Methodology for Prediction Urban Water Demand by Wavelet Denoising and Adaptive Neuro-Fuzzy Inference System Approach. Water 2020, 12, 1628. [Google Scholar] [CrossRef]
- Azad, A.; Karami, H.; Farzin, S.; Mousavi, S.-F.; Kisi, O. Modeling river water quality parameters using modified adaptive neuro fuzzy inference system. Water Sci. Eng. 2019, 12, 45–54. [Google Scholar] [CrossRef]
- García, I.; Rodríguez, J.G.; Lopez, F.; Tenorio, Y.M. Transporte de Contaminantes en Aguas Subterráneas mediante Redes Neuronales Artificiales. Inf. Tecnológica 2010, 21, 79–86. [Google Scholar] [CrossRef] [Green Version]
- Nalavade, J.E.; Murugan, T.S. HRNeuro-fuzzy: Adapting neuro-fuzzy classifier for recurring concept drift of evolving data streams using rough set theory and holoentropy. J. King Saud Univ. Comput. Inf. Sci. 2018, 30, 498–509. [Google Scholar] [CrossRef] [Green Version]
- Peñas, F.J.; Barquín, J.; Snelder, T.H.; Booker, D.J.; Álvarez, C. The influence of methodological procedures on hydrological classification performance. Hydrol. Earth Syst. Sci. 2014, 18, 3393–3409. [Google Scholar] [CrossRef]
- Hussain, W.; Ruhana, K.; Norwawi, N.M. Neural network application in reservoir water level forecasting and release decision. Int. J. New Comput. Archit. Appl. 2011, 1, 256–274. [Google Scholar]
- Graf, W.L. Geomorphology and American dams: The scientific, social, and economic context. Geomorphology 2005, 71, 3–26. [Google Scholar] [CrossRef]
- Monadi, M.; Samani, H.M.V.; Mohammadi, M. Optimal design and benefit/cost analysis of reservoir dams by genetic algorithms case study: Sonateh Dam, Kordistan Province, Iran. Int. J. Eng. 2016, 29, 481–488. [Google Scholar] [CrossRef]
- Hejazi, M.I.; Cai, X.; Ruddell, B. The role of hydrologic information in reservoir operation—Learning from historical releases. Adv. Water Resour. 2008, 31, 1636–1650. [Google Scholar] [CrossRef]
- McManamay, R.A. Quantifying and generalizing hydrologic responses to dam regulation using a statistical modeling approach. J. Hydrol. 2014, 519, 1278–1296. [Google Scholar] [CrossRef] [Green Version]
- Loucks, D.P.; Van Beek, E. Water Resource Systems Planning and Management: An Introduction to Methods, Models, and Applications; Springer International Publishing: Basel, Switzerland, 2017. [Google Scholar]
- Martinez, L.; Santos, F. Generación de Modelos Estadísticos Utilizando Redes Neuronales Y Series de Tiempo Para el Pronóstico de Los Niveles del Reservorio de la Presa Hidroeléctrica Cerrón Grande de el Salvador; Universidad de EL Salvador: Santa Ana, El Salvador, 2019. [Google Scholar]
- Solomatine, D.P.; Torres, A. Neural network approximation of a hydrodynamic model in optimizing reservoir operation. In Proceedings of the 2nd International Conference on Hydroinformatics, Zurich, Switzerland, 9–13 September 1996. [Google Scholar]
- Piri, J.; Rezaei, M. Prediction of water level fluctuations of chahnimeh reservoirs in zabol using ANN, ANFIS and Cuckoo Optimization Algorithm. Iran. J. Health Saf. Environ. 2016, 4, 706–715. [Google Scholar]
- Chang, F.-J.; Chang, Y.-T. Adaptive neuro-fuzzy inference system for prediction of water level in reservoir. Adv. Water Resour. 2006, 29, 1–10. [Google Scholar] [CrossRef]
- Üneş, F.; Demirci, M.; Taşar, B.; Kaya, Y.Z.; Varçin, H. Estimating Dam Reservoir Level Fluctuations Using Data-Driven Techniques. Pol. J. Environ. Stud. 2019, 28, 3451–3462. [Google Scholar] [CrossRef]
- Yates, D.; Sieber, J.; Purkey, D.; Huber-Lee, A. WEAP21—A Demand-, Priority-, and Preference-Driven Water Planning Model. Water Int. 2005, 30, 487–500. [Google Scholar] [CrossRef]
- Kangrang, A.; Prasanchum, H.; Hormwichian, R. Development of future rule curves for multipurpose reservoir operation using conditional genetic and tabu search algorithms. Adv. Civ. Eng. 2018, 2018, 6474870. [Google Scholar] [CrossRef] [Green Version]
- Bazartseren, B.; Hildebrandt, G.; Holz, K.-P. Short-term water level prediction using neural networks and neuro-fuzzy approach. Neurocomputing 2003, 55, 439–450. [Google Scholar] [CrossRef]
- Yang, S.; Yang, D.; Chen, J.; Zhao, B. Real-time reservoir operation using recurrent neural networks and inflow forecast from a distributed hydrological model. J. Hydrol. 2019, 579, 124229. [Google Scholar] [CrossRef]
- INE. Población Por Sexo, Según Provincia, Parroquia y Cantón de Empadronamiento; INE: Quito, Ecuador, 2011.
- EPMAPS. Caracterización de Las Microcuencas Aportantes al Embalse Salve Faccha del Sistema Papallacta; EPMAPS: Quito, Ecuador, 2016. [Google Scholar]
- Cañadas, L. El Mapa Bioclimático y Ecológico del Ecuador; MAF-Pronareg: Quito, Ecuador, 1983.
- Baquero, F.; Sierra, R.; Ordóñez, L.; Tipán, M.; Espinosa, L.; Belen Rivera, M.; Soria, P. La Vegetación de los Andes del Ecuador; EcoCiencia/CESLA/EcoPar/MAG SIGAGRO/CDC-JATUN SACHA/División Geográfica—IGM: Quito, Ecuador, 2004. [Google Scholar]
- Zhu, S.; Lu, H.; Ptak, M.; Dai, J.; Ji, Q. Lake water-level fluctuation forecasting using machine learning models: A systematic review. Environ. Sci. Pollut. Res. 2020, 27, 44807–44819. [Google Scholar] [CrossRef] [PubMed]
- Vaziri, M. Predicting caspian sea surface water level by ANN and ARIMA Models. J. Waterw. Port Coast. Ocean Eng. 1997, 123, 158–162. [Google Scholar] [CrossRef]
- Altunkaynak, A. Forecasting Surface Water Level Fluctuations of Lake Van by Artificial Neural Networks. Water Resour. Manag. 2006, 21, 399–408. [Google Scholar] [CrossRef]
- Nayak, P.; Sudheer, K.; Rangan, D.; Ramasastri, K. A neuro-fuzzy computing technique for modeling hydrological time series. J. Hydrol. 2004, 291, 52–66. [Google Scholar] [CrossRef]
- Dalkiliç, H.Y.; Hashimi, S.A. Prediction of daily streamflow using artificial neural networks (ANNs), wavelet neural networks (WNNs), and adaptive neuro-fuzzy inference system (ANFIS) models. Water Supply 2020, 20, 1396–1408. [Google Scholar] [CrossRef] [Green Version]
- Yarar, A.; Onucyıldız, M.; Copty, N.K. Modelling level change in lakes using neuro-fuzzy and artificial neural networks. J. Hydrol. 2009, 365, 329–334. [Google Scholar] [CrossRef]
- Kisi, O.; Shiri, J.; Nikoofar, B. Forecasting daily lake levels using artificial intelligence approaches. Comput. Geosci. 2012, 41, 169–180. [Google Scholar] [CrossRef]
- Svozil, D.; Kvasnicka, V.; Pospichal, J. Introduction to multi-layer feed-forward neural networks. Chemom. Intell. Lab. Syst. 1997, 39, 43–62. [Google Scholar] [CrossRef]
- Abrahart, R.; Kneale, P.; See, L.M. Neural Networks for Hydrological Modeling; A.A.Balkema Publishers: London, UK, 2004. [Google Scholar]
- Ata, R.; Kocyigit, Y. An adaptive neuro-fuzzy inference system approach for prediction of tip speed ratio in wind turbines. Expert Syst. Appl. 2010, 37, 5454–5460. [Google Scholar] [CrossRef]
- Shing, R.; Sun, C.-T.; Mizutani, E. Neuro-Fuzzy and Soft Computing: A Computional Approach to Learning a Machine Intelligence, 1st ed.; Prentice Hall: Englewood Cliffs, NJ, USA, 1997. [Google Scholar]
- Khoshnevisan, B.; Rafiee, S.; Omid, M.; Mousazadeh, H. Development of an intelligent system based on ANFIS for predicting wheat grain yield on the basis of energy inputs. Inf. Process. Agric. 2014, 1, 14–22. [Google Scholar] [CrossRef] [Green Version]
- Talebizadeh, M.; Moridnejad, A. Uncertainty analysis for the forecast of lake level fluctuations using ensembles of ANN and ANFIS models. Expert Syst. Appl. 2011, 38, 4126–4135. [Google Scholar] [CrossRef]
- Bezdek, J.C.; Ehrlich, R.; Full, W. FCM: The fuzzy c-means clustering algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar] [CrossRef]
- Yager, R.R.; Filev, D.P. Generation of Fuzzy Rules by Mountain Clustering. J. Intell. Fuzzy Syst. 1994, 2, 209–219. [Google Scholar] [CrossRef]
- Sivaraman, E.; Arulselvi, S. Gustafson-kessel (G-K) clustering approach of T-S fuzzy model for nonlinear processes. In Proceedings of the 2009 Chinese Control and Decision Conference, Shanghai, China, 15–18 December 2009; pp. 791–796. [Google Scholar]
- Chiu, S.L. Fuzzy Model Identification Based on Cluster Estimation. J. Intell. Fuzzy Syst. 1994, 2, 267–278. [Google Scholar] [CrossRef]
- Wang, X.L.; Wen, Q.H.; Wu, Y. Penalized Maximal t Test for Detecting Undocumented Mean Change in Climate Data Series. J. Appl. Meteorol. Clim. 2007, 46, 916–931. [Google Scholar] [CrossRef]
- Wang, X.L.; Yang, F. RHtestsV3 User Manual; Climate Research Division Atmospheric Science and Technology Directorate Science and Technology Branch, Environment Canada: Toronto, ON, Canada, 2010.
- Campozano, L.; Sánchez, E.; Avilés, Á.; Samaniego, E. Evaluation of infilling methods for time series of daily precipitation and temperature: The case of the Ecuadorian Andes. MASKANA 2014, 5, 99–115. [Google Scholar] [CrossRef]
- Blázquez-García, A.; Conde, A.; Mori, U.; Lozano, J.A. A review on outlier/anomaly detection in time series data. ACM Comput. Surv. 2020, 54, 1–33. [Google Scholar] [CrossRef]
- Huang, W.; Foo, S. Neural network modeling of salinity variation in Apalachicola River. Water Res. 2002, 36, 356–362. [Google Scholar] [CrossRef]
- Silverman, D.; Dracup, J.A. Artificial neural networks and long-range precipitation prediction in California. J. Appl. Meteorol. 2000, 39, 57–66. [Google Scholar] [CrossRef]
- Maier, H.R.; Jain, A.; Dandy, G.C.; Sudheer, K. Methods used for the development of neural networks for the prediction of water resource variables in river systems: Current status and future directions. Environ. Model. Softw. 2010, 25, 891–909. [Google Scholar] [CrossRef]
- Apaydin, H.; Feizi, H.; Sattari, M.T.; Colak, M.S.; Shamshirband, S.; Chau, K.-W. Comparative Analysis of Recurrent Neural Network Architectures for Reservoir Inflow Forecasting. Water 2020, 12, 1500. [Google Scholar] [CrossRef]
- Chiew, F.; Stewardson, M.; McMahon, T. Comparison of six rainfall-runoff modelling approaches. J. Hydrol. 1993, 147, 1–36. [Google Scholar] [CrossRef]
- Cowpertwait, P.S.P. Bootstrap confidence intervals for predicted rainfall quantiles. Int. J. Clim. 2001, 21, 89–94. [Google Scholar] [CrossRef] [Green Version]
- Jung, K.; Lee, J.; Gupta, V.; Cho, G. Comparison of bootstrap confidence interval methods for gsca using a monte carlo simulation. Front. Psychol. 2019, 10, 2215. [Google Scholar] [CrossRef] [Green Version]
- Bowden, G.J.; Dandy, G.C.; Maier, H.R. Input determination for neural network models in water resources applications. Part 1—background and methodology. J. Hydrol. 2005, 301, 75–92. [Google Scholar] [CrossRef]
- Garreaud, R. The Andes climate and weather. Adv. Geosci. 2009, 22, 3–11. [Google Scholar] [CrossRef] [Green Version]
- Buytaert, W.; Célleri, R.; De Bièvre, B.; Cisneros, F.; Wyseure, G.; Deckers, J.; Hofstede, R. Human impact on the hydrology of the Andean páramos. Earth-Sci. Rev. 2006, 79, 53–72. [Google Scholar] [CrossRef]
- Banhatti, A.G.; Deka, P.C. Effects of Data Pre-processing on the Prediction Accuracy of Artificial Neural Network Model in Hydrological Time Series. In Climate Change Impacts on Water Resources; Springer: Cham, Switzerland, 2016; pp. 265–275. [Google Scholar]
- Londhe, S. Towards predicting water levels using artificial neural networks. In Proceedings of the OCEANS 2009-EUROPE, Bremen, Germany, 11–14 May 2009; pp. 1–6. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Forecast | Correlation | RMSE | NS | Delay (Days) | Nodes | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| WP | WOP | WP | WOP | WP | WOP | WP | WOP | WP | WOP | |
| t + 1 | 0.9992 | 0.999 | 0.076 | 0.053 | 0.998 | 0.999 | 13 | 13 | 15 | 20 |
| t + 2 | 0.9996 | 0.999 | 0.056 | 0.096 | 0.999 | 0.997 | 13 | 13 | 15 | 30 |
| t + 3 | 0.999 | 0.999 | 0.093 | 0.076 | 0.998 | 0.998 | 11 | 10 | 20 | 20 |
| t + 4 | 0.9993 | 1.000 | 0.076 | 0.046 | 0.998 | 0.999 | 11 | 12 | 20 | 20 |
| t + 5 | 0.9993 | 0.999 | 0.095 | 0.062 | 0.998 | 0.999 | 13 | 10 | 15 | 15 |
| t + 6 | 0.9994 | 0.999 | 0.066 | 0.075 | 0.999 | 0.998 | 13 | 8 | 25 | 15 |
| Forecast | Correlation | RMSE | ns | Delay (Days) | ||||
|---|---|---|---|---|---|---|---|---|
| WP | WOP | WP | WOP | WP | WOP | WP | WOP | |
| t + 1 | 0.9996 | 0.9996 | 0.0517 | 0.0505 | 0.9992 | 0.9993 | 3 | 3 |
| t + 2 | 0.9992 | 0.9992 | 0.0756 | 0.0745 | 0.9984 | 0.9984 | 3 | 4 |
| t + 3 | 0.9989 | 0.9990 | 0.0880 | 0.0820 | 0.9978 | 0.9981 | 3 | 4 |
| t + 4 | 0.9989 | 0.9990 | 0.0884 | 0.0807 | 0.9978 | 0.9981 | 3 | 4 |
| t + 5 | 0.9990 | 0.9990 | 0.0837 | 0.0769 | 0.9980 | 0.9981 | 3 | 4 |
| t + 6 | 0.9991 | 0.9992 | 0.0780 | 0.0737 | 0.9983 | 0.9981 | 3 | 4 |
| Model | Forecast | Rainy Season | Dry Season | ||||
|---|---|---|---|---|---|---|---|
| Correlation | RMSE | NS | Correlation | RMSE | NS | ||
| Neural Networks | t + 1 | 0.9996 | 0.0653 | 0.9992 | 0.9997 | 0.0424 | 0.9994 |
| t + 2 | 0.9989 | 0.105 | 0.9979 | 0.9994 | 0.0595 | 0.9988 | |
| t + 3 | 0.9987 | 0.118 | 0.9973 | 0.9992 | 0.0674 | 0.9984 | |
| t + 4 | 0.9987 | 0.1159 | 0.9974 | 0.9992 | 0.0697 | 0.9983 | |
| t + 5 | 0.9988 | 0.1075 | 0.9978 | 0.9992 | 0.0635 | 0.9986 | |
| t + 6 | 0.9989 | 0.1092 | 0.9977 | 0.9993 | 0.0674 | 0.9984 | |
| ANFIS | t + 1 | 0.9995 | 0.077 | 0.9988 | 0.9998 | 0.0402 | 0.9995 |
| t + 2 | 0.9983 | 0.1351 | 0.9965 | 0.9996 | 0.0744 | 0.9981 | |
| t + 3 | 0.999 | 0.1082 | 0.9977 | 0.9996 | 0.0579 | 0.9989 | |
| t + 4 | 0.9997 | 0.0659 | 0.9992 | 0.9998 | 0.0342 | 0.9996 | |
| t + 5 | 0.9992 | 0.1146 | 0.9974 | 0.9996 | 0.0523 | 0.9991 | |
| t + 6 | 0.9988 | 0.0888 | 0.9985 | 0.9995 | 0.0472 | 0.9992 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Páliz Larrea, P.; Zapata-Ríos, X.; Campozano Parra, L. Application of Neural Network Models and ANFIS for Water Level Forecasting of the Salve Faccha Dam in the Andean Zone in Northern Ecuador. Water 2021, 13, 2011. https://doi.org/10.3390/w13152011
Páliz Larrea P, Zapata-Ríos X, Campozano Parra L. Application of Neural Network Models and ANFIS for Water Level Forecasting of the Salve Faccha Dam in the Andean Zone in Northern Ecuador. Water. 2021; 13(15):2011. https://doi.org/10.3390/w13152011
Chicago/Turabian StylePáliz Larrea, Pablo, Xavier Zapata-Ríos, and Lenin Campozano Parra. 2021. "Application of Neural Network Models and ANFIS for Water Level Forecasting of the Salve Faccha Dam in the Andean Zone in Northern Ecuador" Water 13, no. 15: 2011. https://doi.org/10.3390/w13152011