
An Innovative Hourly Water Demand Forecasting Preprocessing Framework with Local Outlier Correction and Adaptive Decomposition Techniques


Abstract
:1. Introduction
- The earlier models usually neglect the importance of outlier processing. As such, they cannot improve the accuracy of the hourly forecasting models. In this study, in order to improve the accuracy of water demand forecasting models, a global Isolation Forest model and a local Isolation Forest model have been compared to detect and correct outliers.
- In this study, an effective signal decomposition technique of CEEMDAN has been introduced to decompose a complex original signal into sub-signals, which makes water demand forecasting easier.
- A promising deep learning method of Gated Recurrent Unit (GRU) has been introduced and compared with the conventional ANN and Support Vector Regression (SVR) to explore the potential of the deep learning method for hourly water demand forecasting.
- To the best of our knowledge, this study is the first to integrate two preprocessing methods (i.e., signal decomposition and outlier detection and correction methods) for water demand forecasting.
2. Methods
2.1. Isolation Forest
2.2. Complete Ensemble Empirical Mode Decomposition with Adaptive Noise
2.2.1. Empirical Mode Decomposition
- the number of extreme points and the zero crossings are equal or differ at the most by one; and
- the mean value of the upper and lower envelopes is zero at any point.
- Generate a new sequence by calculating the mean value of the upper envelope and the lower envelope of the original signal .
- Subtracting from gives an IMF candidate , where .
- Set as the original signal, repeat the above steps, and obtain the first IMF signal when satisfies the conditions of an IMF.
- Set as the original signal, where . Repeat Steps (1) to (3) until the residue is a monotonic function or satisfies the predefined stopping criterion, where . Then, end the decomposition process, and all the IMFs and the residue of the original signal are obtained.
2.2.2. Ensemble Empirical Mode Decomposition
- Add the Gaussian white noise to the original signal and determine , where .
- Decompose the improved original signal by an EMD algorithm and determine all the ( is the th IMF of the EMD decomposition when adding the white noise at the th time).
- Repeat Steps (1) and (2) for times. It is worth noting that the added Gaussian white noise is different each time.
- The true is the sequence constructed by the mean value of the :
2.2.3. Complete Ensemble Empirical Mode Decomposition with Adaptive Noise
- In CEEMDAN, the way to determine the first decomposition mode is the same as the EEMD. Decompose the signal for the th computation of CEEMDAN, where is the signal-to-noise ratio. Calculate the first IMF as follows:The first residue is:
- Determine the second decomposition mode and the residue as follows:where is the ith decomposition mode of by EMD.
- Similarly, for = 3,4,, I, the and can be calculated as follows:
- Repeat Step (3) until the residue is a monotonic function or satisfies the predefined stopping criterion. The final residue can be calculated as follows:Therefore, the original signal can be described as follows:
2.3. Artificial Neural Network
2.4. Gated Recurrent Unit
2.5. Support Vector Regression
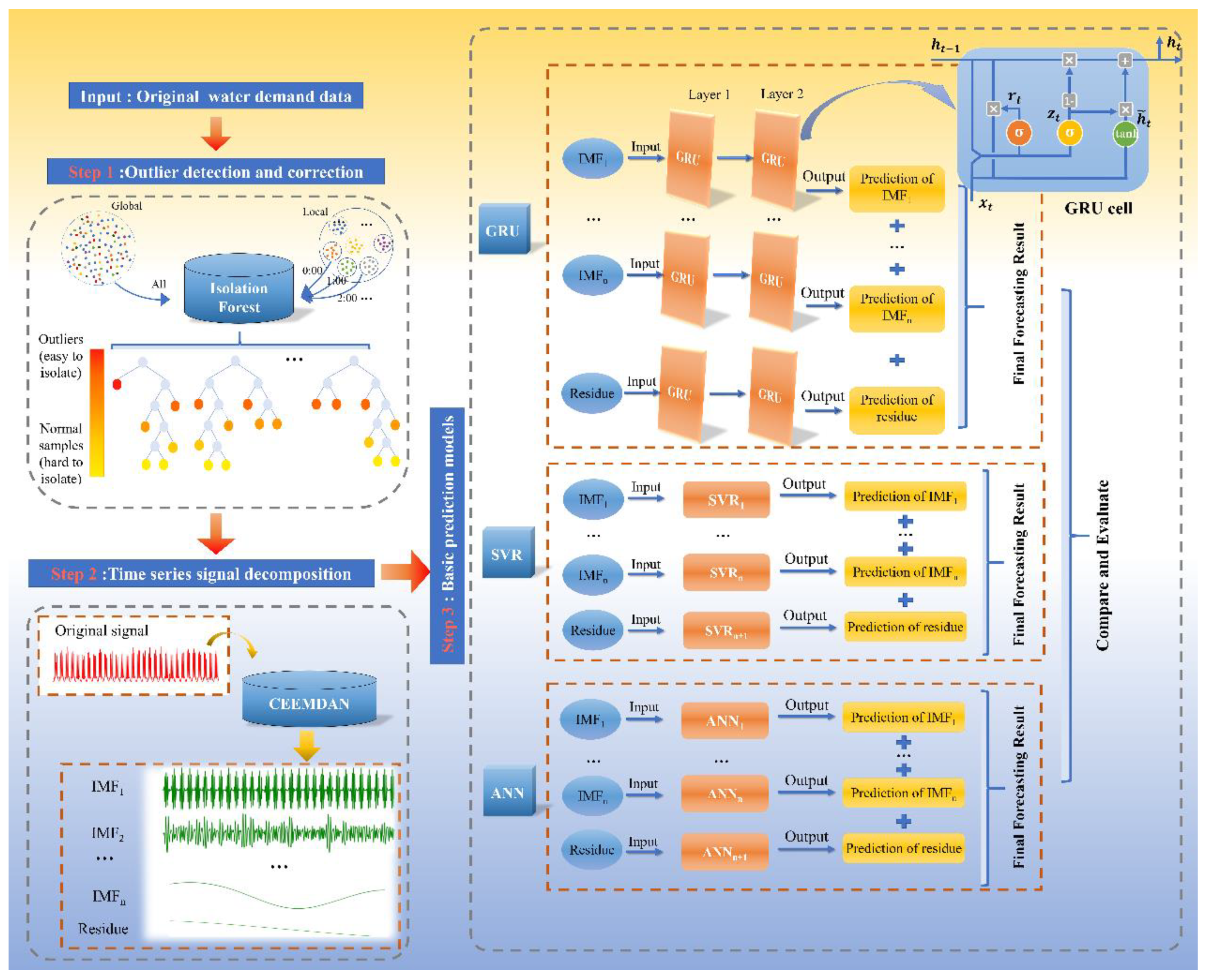
2.6. Research Flowchart
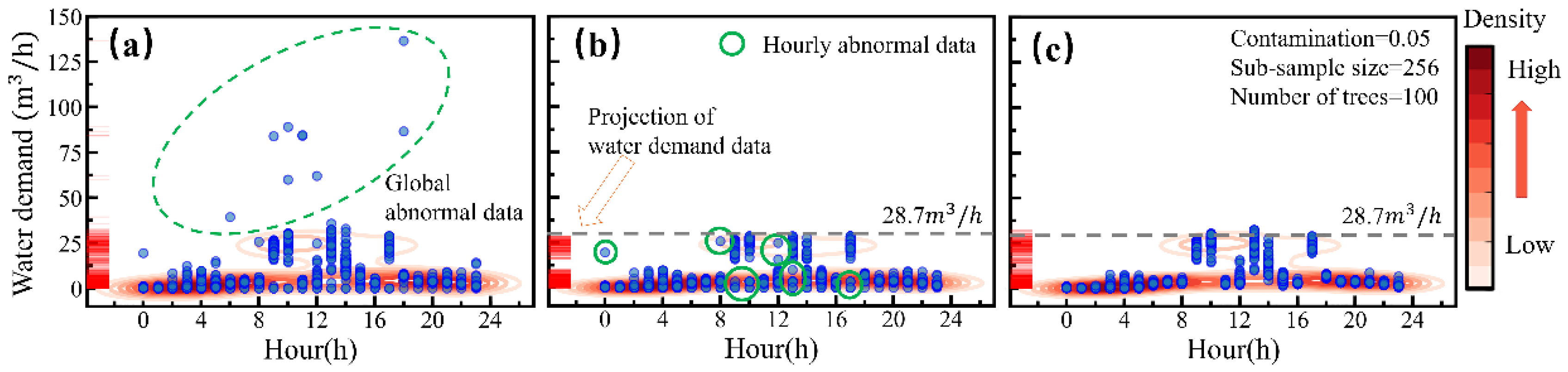
- Through the outlier detection and correction process, the original water demand data are cleaned (i.e., Step 1 in Figure 1). In this study, we have compared the proposed local outlier detection and correction method, and a global outlier detection and correction method. In the local outlier detection and correction method, water demand data are assumed to follow a specific distribution for each hour. First, the water demand data are classified hourly into 24 clusters. Then, 24 Isolation Forest models are built for each cluster to detect the outliers. The outliers are then corrected by the mean value of that hour instead of the global mean value. In the global method, an Isolation Forest model is built based on all the data of water demand, and the outliers are corrected by the global mean value.
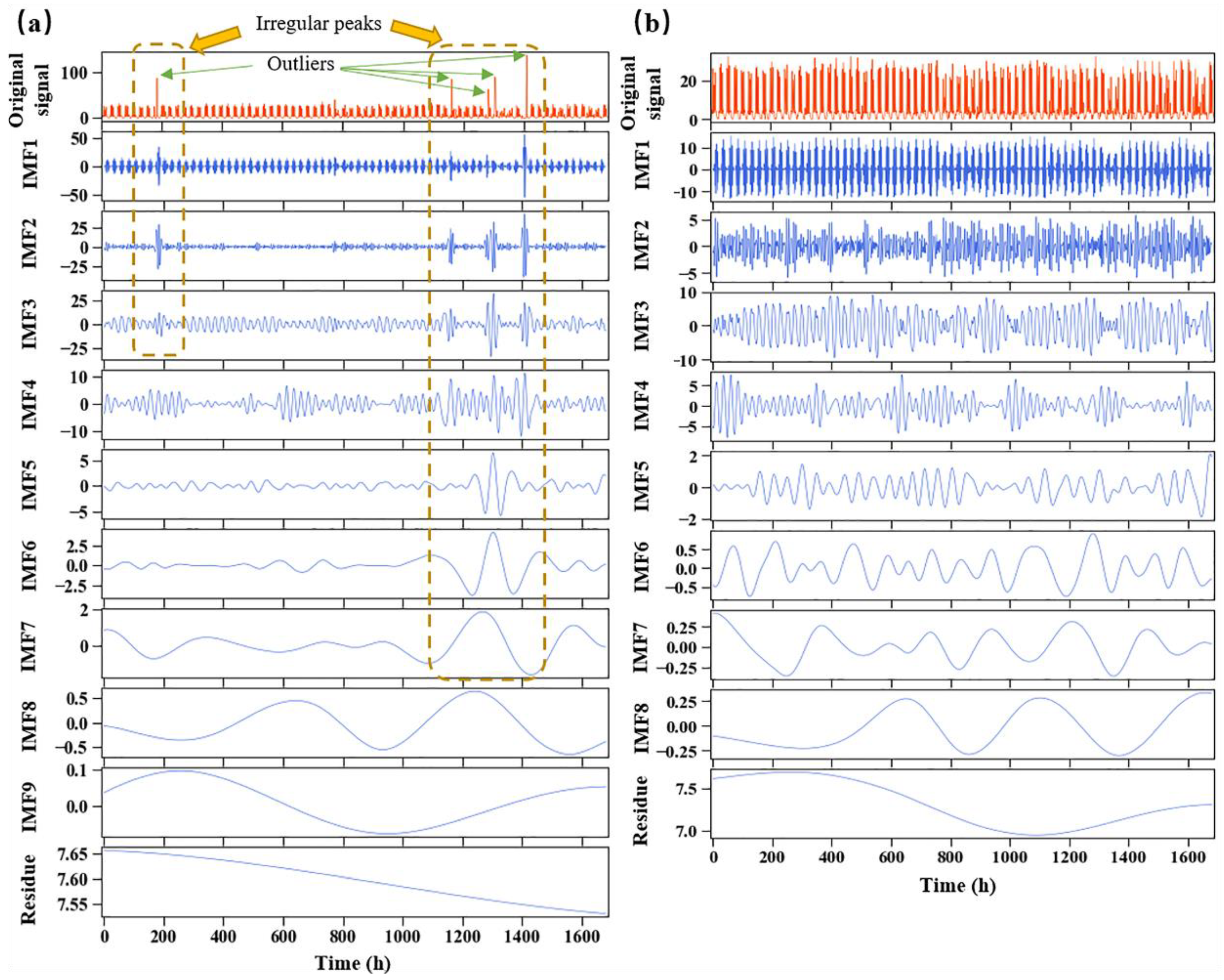
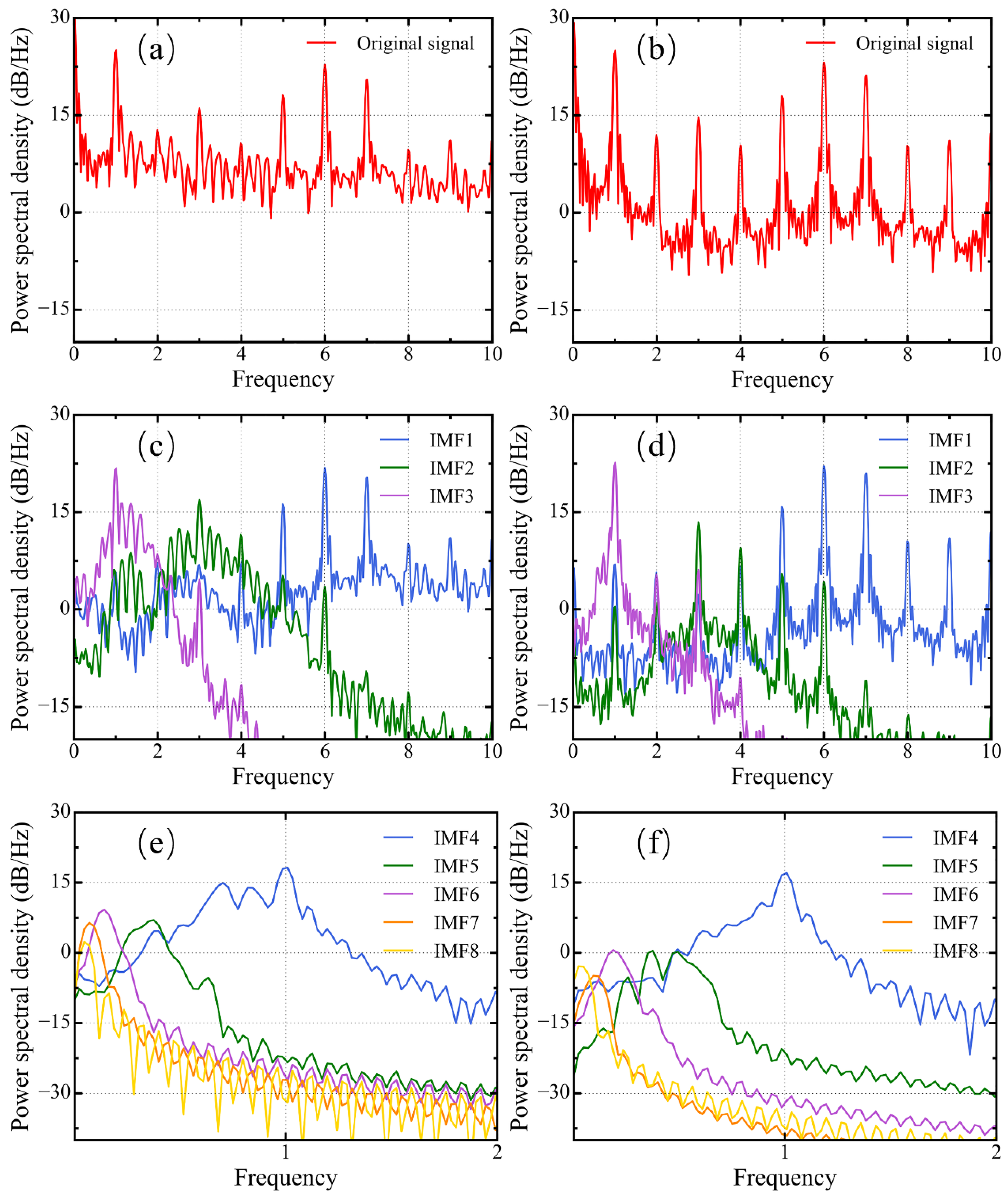
- After outlier correction, the nonstationary and nonlinear time series signal is decomposed adaptively by CEEMDAN and turned into simpler sub-signals (i.e., Step 2 in Figure 1). It is easier for these sub-signals to extract the features.
- The GRU, SVR, and ANN models are built based on each sub-series to explore the efficiency of the proposed preprocessing framework on different forecasting models (i.e., Step 3 in Figure 1). The forecasting result of a water demand time series is the sum of the forecasting results of all the sub-signals.
3. Case Study
3.1. Data Description
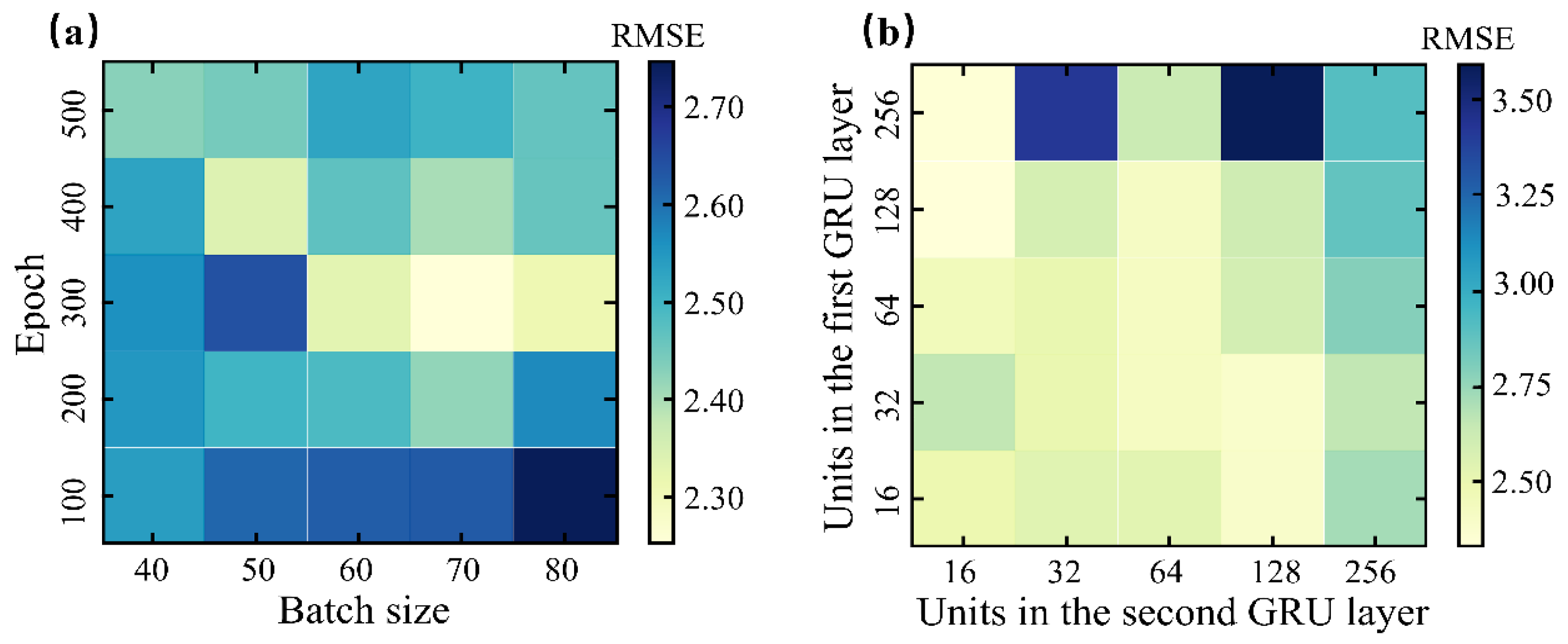
3.2. Model Development
3.3. Performance Evaluation Indices
4. Results and Discussion
4.1. Outlier Detection and Correction
4.2. Time Series Signal Decomposition
4.3. Overall Performance
5. Conclusions
- The proposed preprocessing method can greatly improve the accuracy of hourly water demand forecasting models. The RMSE of the SVR, ANN, and GRU models has reduced by 57.5%, 27.8%, and 30.0%, respectively.
- The local outlier detection and correction method not only effectively identifies global outlier and outlier clusters that are overlapped with other normal data, but also reduce misidentification of normal samples.
- The CEEMDAN model is able to decompose nonstationary and nonlinear water demand time series into sub-signals with an obvious main power spectral density peak, which makes it easier to capture the signal characteristics for prediction.
- Despite the higher computational load, the GRU-based models always perform better than the ANN and SVR-based models. The IF-CEEMDAN-GRU model is the most accurate model among the twelve models examined in this study. The prediction by the SVR model without preprocessing is poor, but the IF-CEEMDAN-SVR model can achieve an accuracy close to that of the IF-CEEMDAN-GRU model with lower computational load. That is, the proposed method can also exert great potential on some of the conventional models.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hao, L.; Sun, G.; Liu, Y.; Qian, H. Integrated Modeling of Water Supply and Demand under Management Options and Climate Change Scenarios in Chifeng City, China. JAWRA J. Am. Water Resour. Assoc. 2015, 51, 655–671. [Google Scholar] [CrossRef]
- Kifle Arsiso, B.; Mengistu Tsidu, G.; Stoffberg, G.H.; Tadesse, T. Climate change and population growth impacts on surface water supply and demand of Addis Ababa, Ethiopia. Clim. Risk Manag. 2017, 18, 21–33. [Google Scholar] [CrossRef]
- Adamowski, J.; Fung Chan, H.; Prasher, S.O.; Ozga-Zielinski, B.; Sliusarieva, A. Comparison of multiple linear and nonlinear regression, autoregressive integrated moving average, artificial neural network, and wavelet artificial neural network methods for urban water demand forecasting in Montreal, Canada. Water Resour. Res. 2012, 48. [Google Scholar] [CrossRef]
- Donkor, E.A.; Mazzuchi, T.A.; Soyer, R.; Roberson, J.A. Urban Water Demand Forecasting: Review of Methods and Models. J. Water Resour. Plan. Manag. 2014, 140, 146–159. [Google Scholar] [CrossRef]
- Polebitski, A.S.; Palmer, R.N. Seasonal Residential Water Demand Forecasting for Census Tracts. J. Water Resour. Plan. Manag. 2010, 136, 27–36. [Google Scholar] [CrossRef]
- Francesca, G.; Stefano, A.; Zoran, K.; Marco, F. A probabilistic short-termwater demand forecasting model based on the Markov chain. Water 2017, 9, 507. [Google Scholar]
- Duerr, I.; Merrill, H.R.; Wang, C.; Bai, R.; Boyer, M.; Dukes, M.D.; Bliznyuk, N. Forecasting urban household water demand with statistical and machine learning methods using large space-time data: A Comparative study. Environ. Model. Softw. 2018, 102, 29–38. [Google Scholar] [CrossRef]
- McKenna, S.A.; Fusco, F.; Eck, B.J. Water Demand Pattern Classification from Smart Meter Data. Procedia Eng. 2014, 70, 1121–1130. [Google Scholar] [CrossRef] [Green Version]
- Mamade, A.; Loureiro, D.; Covas, D.; Coelho, S.T.; Amado, C. Spatial and Temporal Forecasting of Water Consumption at the DMA Level Using Extensive Measurements. Procedia Eng. 2014, 70, 1063–1073. [Google Scholar] [CrossRef] [Green Version]
- Seok, J.; Kim, J.; Lee, J.; Lee, J.; Song, Y.; Shin, G. Abnormal data refinement and error percentage correction methods for effective short-term hourly water demand forecasting. Int. J. Control Autom. 2014, 12, 1245–1256. [Google Scholar] [CrossRef]
- De Souza Groppo, G.; Costa, M.A.; Libânio, M. Predicting water demand: A review of the methods employed and future possibilities. Water Supply 2019, 19, 2179–2198. [Google Scholar] [CrossRef]
- Adamowski, J.F. Peak Daily Water Demand Forecast Modeling Using Artificial Neural Networks. J. Water Resour. Plan. Manag. 2008, 134, 119–128. [Google Scholar] [CrossRef] [Green Version]
- Caiado, J. Performance of Combined Double Seasonal Univariate Time Series Models for Forecasting Water Demand. J. Hydrol. Eng. 2010, 15, 215–222. [Google Scholar] [CrossRef] [Green Version]
- Oyebode, O.; Ighravwe, D.E. Urban Water Demand Forecasting: A Comparative Evaluation of Conventional and Soft Computing Techniques. Resources 2019, 8, 156. [Google Scholar] [CrossRef] [Green Version]
- Shvartser, L.; Shamir, U.; Feldman, M. Forecasting Hourly Water Demands by Pattern Recognition Approach. J. Water Resour. Plan. Manag. 1993, 119, 611–627. [Google Scholar] [CrossRef]
- Arandia, E.; Ba, A.; Eck, B.; McKenna, S. Tailoring Seasonal Time Series Models to Forecast Short-Term Water Demand. J. Water Resour. Plan. Manag. 2016, 142, 4015067. [Google Scholar] [CrossRef] [Green Version]
- Adamowski, J.; Karapataki, C. Comparison of Multivariate Regression and Artificial Neural Networks for Peak Urban Water-Demand Forecasting: Evaluation of Different ANN Learning Algorithms. J. Hydrol. Eng. 2010, 15, 729–743. [Google Scholar] [CrossRef] [Green Version]
- Herrera, M.; Torgo, L.; Izquierdo, J.; Pérez-García, R. Predictive models for forecasting hourly urban water demand. J. Hydrol. 2010, 387, 141–150. [Google Scholar] [CrossRef]
- Ghalehkhondabi, I.; Ardjmand, E.; Weckman, G.; Young, W. Water Demand Forecasting: Review of Soft Computing Methods. Environ. Monit. Assess. 2017, 189, 313. [Google Scholar] [CrossRef]
- Bougadis, J.; Adamowski, K.; Diduch, R. Short-term municipal water demand forecasting. Hydrol. Process. 2005, 19, 137–148. [Google Scholar] [CrossRef]
- Ghiassi, M.; Zimbra, D.K.; Saidane, H. Urban Water Demand Forecasting with a Dynamic Artificial Neural Network Model. J. Water Resour. Plan. Manag. 2008, 134, 138–146. [Google Scholar] [CrossRef]
- Fei, S.; He, Y. Wind speed prediction using the hybrid model of wavelet decomposition and artificial bee colony algorithm-based relevance vector machine. Int. J. Electr. Power Energy Syst. 2015, 73, 625–631. [Google Scholar] [CrossRef]
- Shen, C. A Transdisciplinary Review of Deep Learning Research and Its Relevance for Water Resources Scientists. Water Resour. Res. 2018, 54, 8558–8593. [Google Scholar] [CrossRef]
- Guo, G.; Liu, S.; Wu, Y.; Li, J.; Zhou, R.; Zhu, X. Short-Term Water Demand Forecast Based on Deep Learning Method. J. Water Resour. Plan. Manag. 2018, 144, 04018076. [Google Scholar] [CrossRef]
- Ren, Z.; Li, S. Short-term demand forecasting for distributed water supply networks: A multi-scale approach. In Proceedings of the 2016 12th World Congress on Intelligent Control and Automation (WCICA), Guilin, China, 12–15 June 2016; pp. 1860–1865. [Google Scholar]
- Wu, Z.; Huang, N.E. Ensemble Empirical Mode Decomposition: A Noise-Assisted Data Analysis Method. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Deng, X.; Hou, S.; Li, W.; Liu, X. Hourly Campus Water Demand Forecasting Using a Hybrid. EEMD-Elman Neural Network Model; Dong, W., Lian, Y., Zhang, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 71–80. [Google Scholar]
- Himeur, Y.; Ghanem, K.; Alsalemi, A.; Bensaali, F.; Amira, A. Artificial intelligence based anomaly detection of energy consumption in buildings: A review, current trends and new perspectives. Appl. Energy 2021, 287, 116601. [Google Scholar] [CrossRef]
- Santos, F. Modern methods for old data: An overview of some robust methods for outliers detection with applications in osteology. J. Archaeol. Sci. Rep. 2020, 32, 102423. [Google Scholar] [CrossRef]
- Zheng, S.; Zhu, Y.X.; Li, D.Q.; Cao, Z.J.; Phoon, K.K. Probabilistic outlier detection for sparse multivariate geotechnical site investigation data using Bayesian learning. Geosci. Front. 2020, 12, 425–439. [Google Scholar] [CrossRef]
- Van Capelleveen, G.; Poel, M.; Mueller, R.M.; Thornton, D.; Van Hillegersberg, J. Outlier detection in healthcare fraud: A case study in the Medicaid dental domain. Int. J. Account. Inf. Syst. 2016, 21, 18–31. [Google Scholar] [CrossRef]
- Michalak, M.; Wawrowski, U.; Sikora, M.; Kurianowicz, R.; Bialas, A. Outlier Detection in Network Traffic Monitoring. In Proceedings of the 10th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2021), Vienna, Austria, 4–6 February 2021. [Google Scholar]
- Laurikkala, J.; Juhola, M.; Kentala, E. Informal Identification of Outliers in Medical Data. In Proceedings of the Fifth International Workshop on Intelligent Data Analysis in Medicine and Pharmacology, Berlin, Germany, 22 August 2000. [Google Scholar]
- Rousseeuw, P.J.; Driessen, K.V. Computing LTS Regression for Large Data Sets. Data Min. Knowl. Discov. 2006, 12, 29–45. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Hutter, M.; Jin, H. A New Local Distance-Based Outlier Detection Approach for Scattered Real-World Data. In Pacific-asia Conference on Knowledge Discovery & Data Mining; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Breunig, M.; Kriegel, H.; Ng, R.; Sander, J. LOF: Identifying Density-Based Local Outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 16–18 May 2000; Volume 29, pp. 93–104. [Google Scholar]
- Smiti, A. A critical overview of outlier detection methods. Comput. Sci. Rev. 2020, 38, 100306. [Google Scholar] [CrossRef]
- Chan, T.K.; Chin, C.S. Unsupervised Bayesian Nonparametric Approach with Incremental Similarity Tracking of Unlabeled Water Demand Time Series for Anomaly Detection. Water 2019, 11, 2066. [Google Scholar] [CrossRef] [Green Version]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation Forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008. [Google Scholar]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Torres, M.E.; Colominas, M.A.; Schlotthauer, G.; Flandrin, P. A complete ensemble empirical mode decomposition with adaptive noise. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 4144–4147. [Google Scholar]
- Seo, Y.; Kwon, S.; Choi, Y. Short-Term Water Demand Forecasting Model Combining Variational Mode Decomposition and Extreme Learning Machine. Hydrology 2018, 5, 54. [Google Scholar] [CrossRef] [Green Version]
- Cho, K.; van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Pesantez, J.E.; Berglund, E.Z.; Kaza, N. Smart meters data for modeling and forecasting water demand at the user-level. Environ. Model. Softw. 2020, 125, 104633. [Google Scholar] [CrossRef]
- Antonio, C. Clustering and Support Vector Regression for Water Demand Forecasting and Anomaly Detection. Water 2017, 9, 224. [Google Scholar]
- Candelieri, A.; Archetti, F. Identifying Typical Urban Water Demand Patterns for a Reliable Short-term Forecasting—The Icewater Project Approach. Procedia Eng. 2014, 89, 1004–1012. [Google Scholar] [CrossRef] [Green Version]
- Candelieri, A.; Giordani, I.; Archetti, F.; Barkalov, K.; Meyerov, I.; Polovinkin, A.; Sysoyev, A.; Zolotykh, N. Tuning hyperparameters of a SVM-based water demand forecasting system through parallel global optimization. Comput. Oper. Res. 2018, 106, 202–209. [Google Scholar] [CrossRef]
- Bernhard Scholkopf, A.J.S. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; Adaptive Computation and Machine Learning Series; The MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Bakker, M.; Vreeburg, J.H.G.; van Schagen, K.M.; Rietveld, L.C. A fully adaptive forecasting model for short-term drinking water demand. Environ. Model. Softw. 2013, 48, 141–151. [Google Scholar] [CrossRef]
- Alvisi, S.; Franchini, M.; Marinelli, A. A short-term, pattern-based model for water-demand forecasting. J. Hydroinform. 2007, 9, 39–50. [Google Scholar] [CrossRef] [Green Version]
- Carriero, A.; Kapetanios, G.; Marcellino, M. Forecasting large datasets with Bayesian reduced rank multivariate models. J. Appl. Econ. 2011, 26, 735–761. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.; Xiong, F.; Huang, B.; Xu, C.; Jiao, R.; Liao, B.; Yin, Z.; Li, J. Game-Theoretical Energy Management for Energy Internet With Big Data-Based Renewable Power Forecasting. IEEE Access 2017, 5, 5731–5746. [Google Scholar] [CrossRef]
- Raza, M.Q.; Nadarajah, M.; Ekanayake, C. Demand forecast of PV integrated bioclimatic buildings using ensemble framework. Appl. Energy 2017, 208, 1626–1638. [Google Scholar] [CrossRef]
- Ding, Z.; Fei, M. An Anomaly Detection Approach Based on Isolation Forest Algorithm for Streaming Data using Sliding Window. IFAC Proc. Vol. 2013, 46, 12–17. [Google Scholar] [CrossRef]
- Colominas, M.A.; Schlotthauer, G.; Torres, M.E. Improved complete ensemble EMD: A suitable tool for biomedical signal processing. Biomed. Signal Process. Control 2014, 14, 19–29. [Google Scholar] [CrossRef]
- Lei, Y.; Liu, Z.; Ouazri, J.; Lin, J. A fault diagnosis method of rolling element bearings based on CEEMDAN. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 2015, 231, 1804–1815. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.; Zhou, Z. Isolation-Based Anomaly Detection. ACM Trans. Knowl. Discov. Data TKDD 2012, 6, 1–39. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | MAE | RMSE | r | |
|---|---|---|---|---|
| SVR | 4.60996 | 5.58961 | 0.50343 | 0.75491 |
| IF-SVR | 2.23167 | 2.95628 | 0.861099 | 0.928563 |
| CEEMDAN-SVR | 2.60908 | 3.56389 | 0.798133 | 0.904639 |
| IF-CEEMDAN-SVR | 1.79512 | 2.37339 | 0.910473 | 0.955239 |
| ANN | 2.59636 | 3.60472 | 0.793481 | 0.89321 |
| IF-ANN | 2.07612 | 3.17677 | 0.839606 | 0.917693 |
| CEEMDAN-ANN | 2.99397 | 3.99805 | 0.745954 | 0.878257 |
| IF-CEEMDAN-ANN | 1.9694 | 2.6012 | 0.892461 | 0.945378 |
| GRU | 2.27949 | 3.32249 | 0.824554 | 0.910801 |
| IF-GRU | 1.98076 | 3.26109 | 0.830978 | 0.916113 |
| CEEMDAN-GRU | 1.67429 | 2.35978 | 0.911497 | 0.957639 |
| IF-CEEMDAN-GRU | 1.52313 | 2.32435 | 0.914134 | 0.956688 |
| Model | CPU Time (s) | Model | CPU Time (s) |
|---|---|---|---|
| SVR | 0.008 | CEEMDAN-SVR | 13.579 |
| IF-SVR | 3.584 | IF-CEEMDAN-SVR | 17.134 |
| ANN | 0.075 | CEEMDAN-ANN | 14.641 |
| IF-ANN | 3.668 | IF-CEEMDAN-ANN | 18.529 |
| GRU | 192.128 | CEEMDAN-GRU | 1934.022 |
| IF-GRU | 194.508 | IF-CEEMDAN-GRU | 1996.464 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, S.; Gao, J.; Zhong, D.; Deng, L.; Ou, C.; Xin, P. An Innovative Hourly Water Demand Forecasting Preprocessing Framework with Local Outlier Correction and Adaptive Decomposition Techniques. Water 2021, 13, 582. https://doi.org/10.3390/w13050582
Hu S, Gao J, Zhong D, Deng L, Ou C, Xin P. An Innovative Hourly Water Demand Forecasting Preprocessing Framework with Local Outlier Correction and Adaptive Decomposition Techniques. Water. 2021; 13(5):582. https://doi.org/10.3390/w13050582
Chicago/Turabian StyleHu, Shiyuan, Jinliang Gao, Dan Zhong, Liqun Deng, Chenhao Ou, and Ping Xin. 2021. "An Innovative Hourly Water Demand Forecasting Preprocessing Framework with Local Outlier Correction and Adaptive Decomposition Techniques" Water 13, no. 5: 582. https://doi.org/10.3390/w13050582