
Unsupervised Machine Learning and Data Mining Procedures Reveal Short Term, Climate Driven Patterns Linking Physico-Chemical Features and Zooplankton Diversity in Small Ponds


Abstract
:1. Introduction
2. Materials and Methods
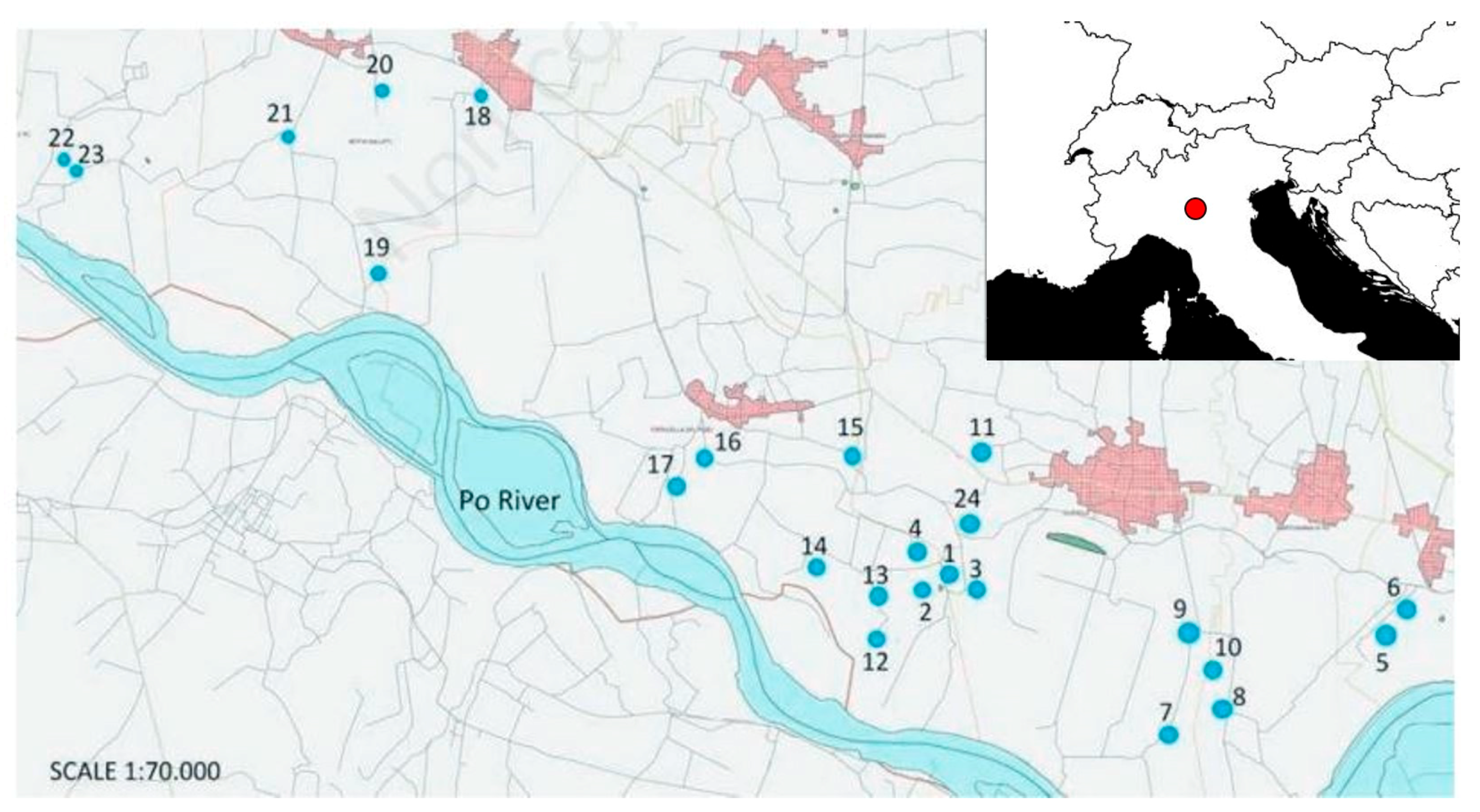
2.1. Data Collection
2.2. Environmental Features Selection
2.3. Fuzzy Clustering
Σ μij = 1 for 1 ≤ i ≤ p
Σ μij > 0 for 1 ≤ j ≤ c
2.4. Richness and Beta Diversity
2.5. Community Structure and Association Rules
3. Results
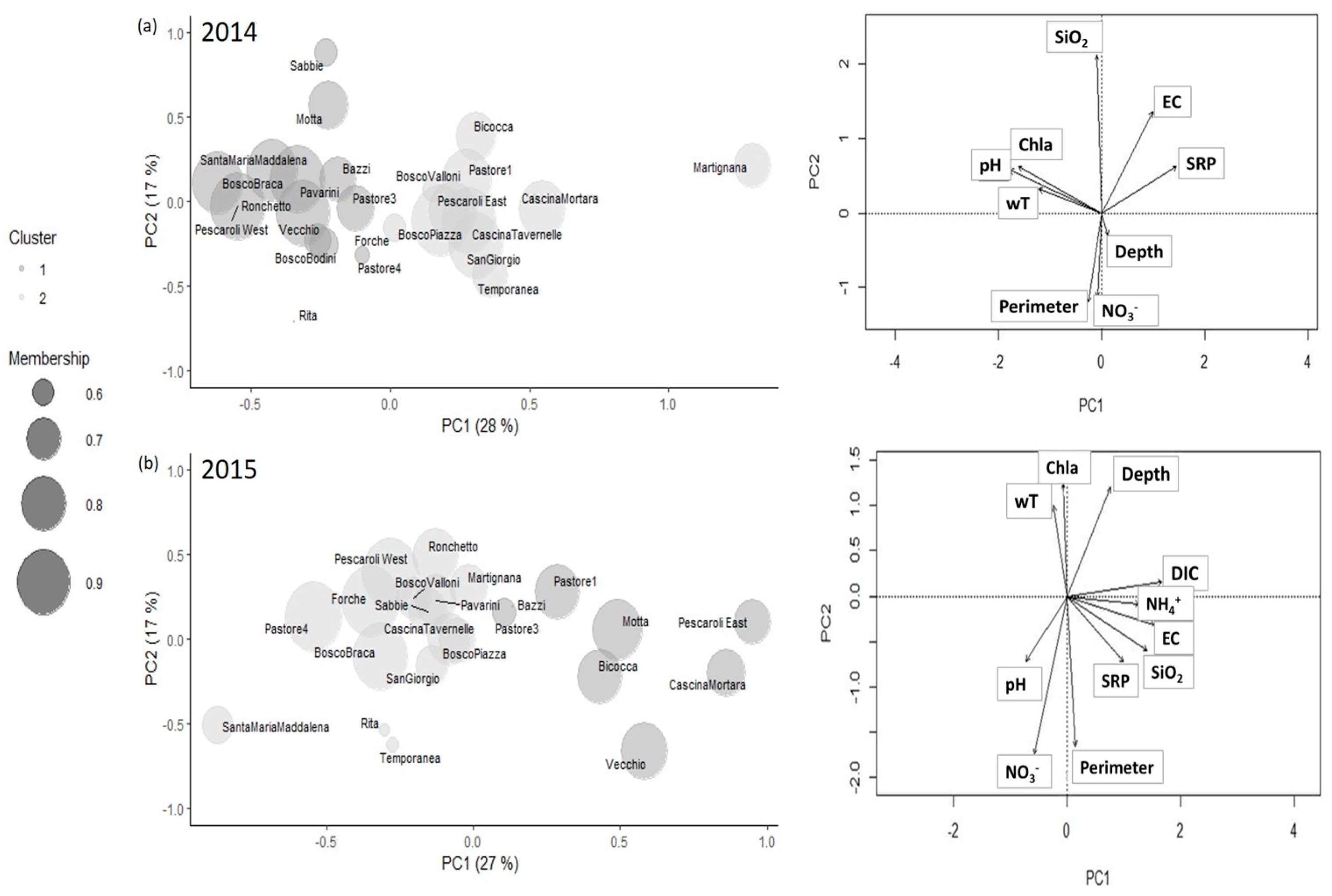
3.1. Environmental Features Selection
3.2. Fuzzy c-Means
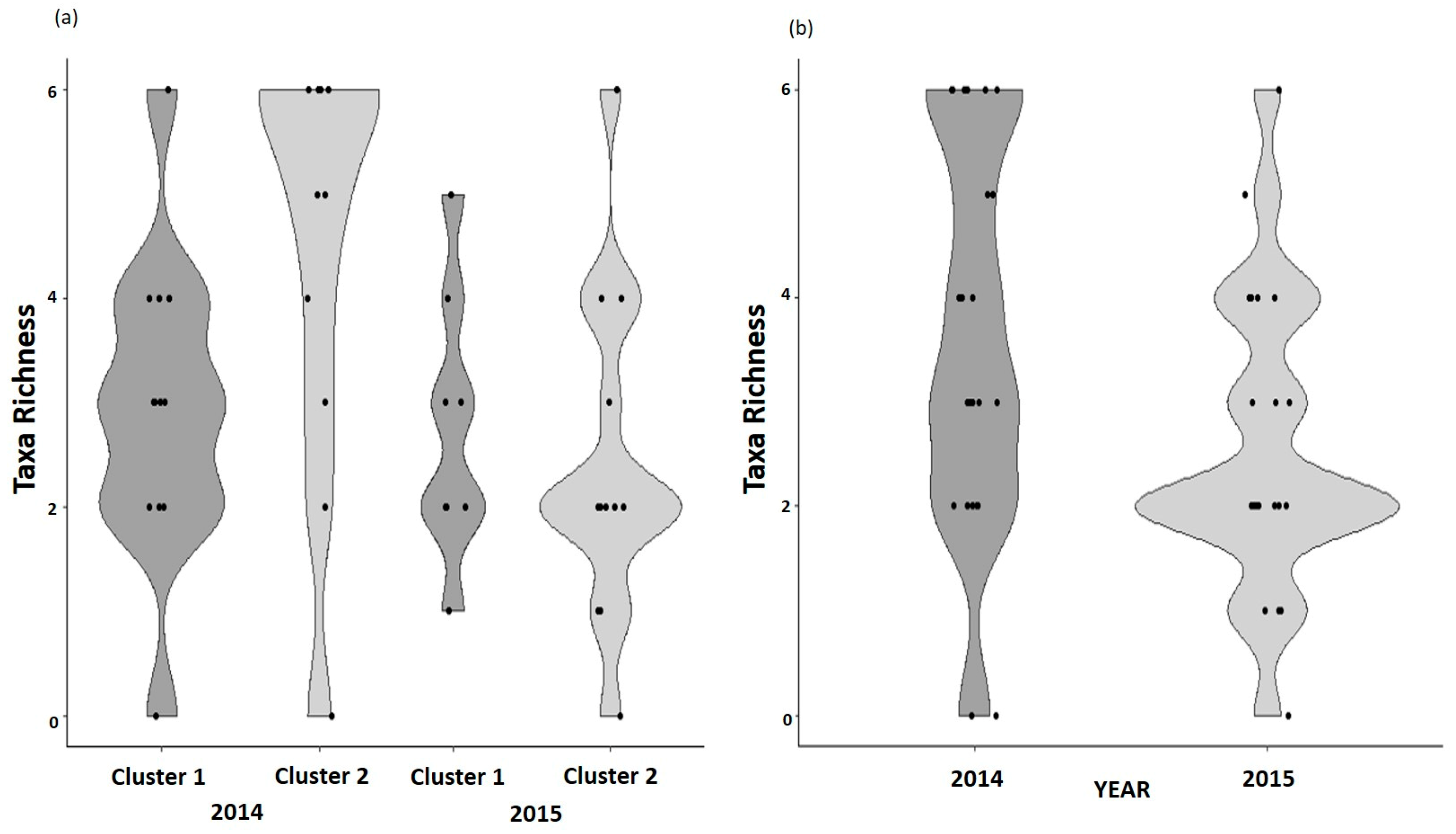
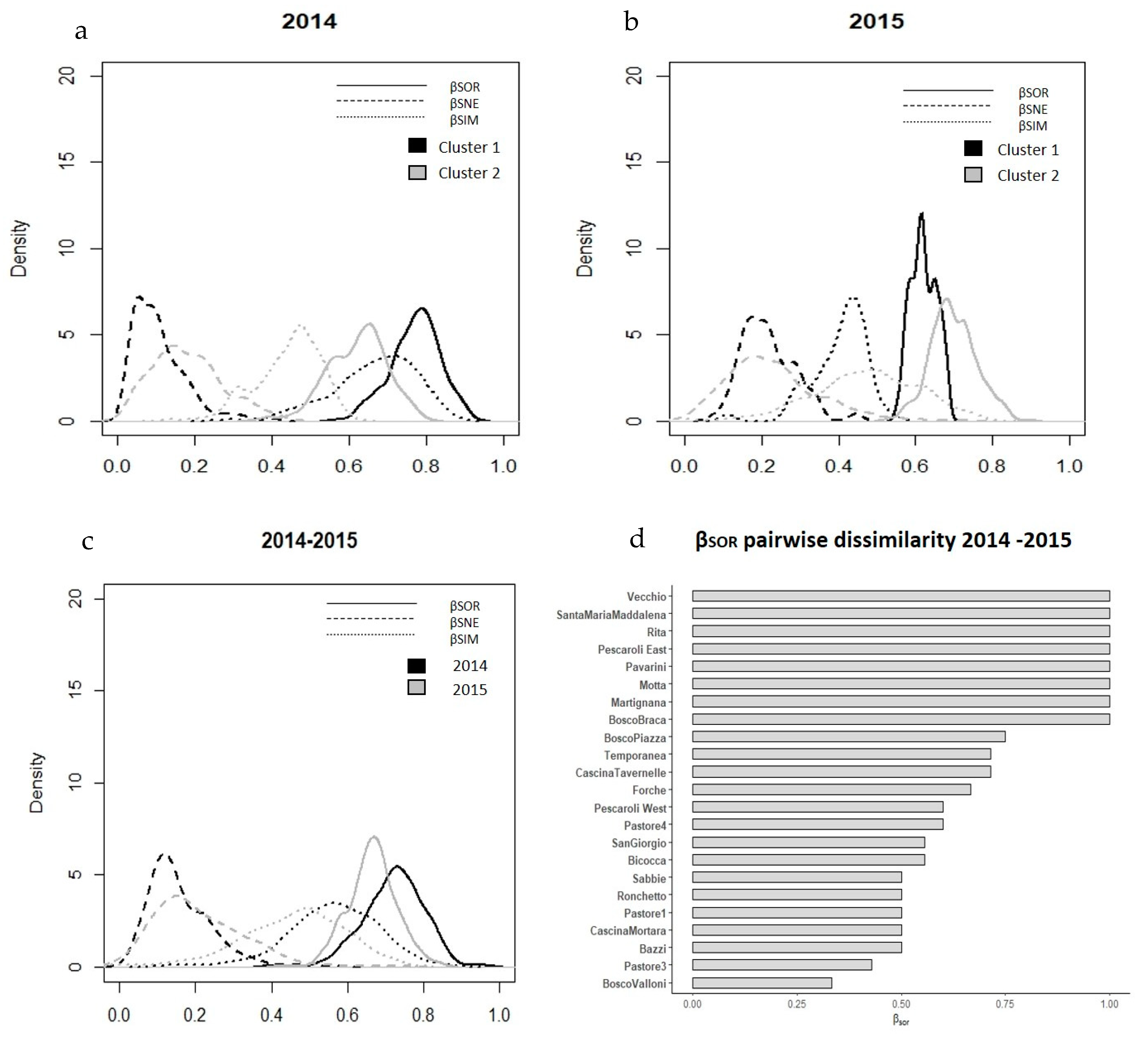
3.3. Richness and Beta Diversity
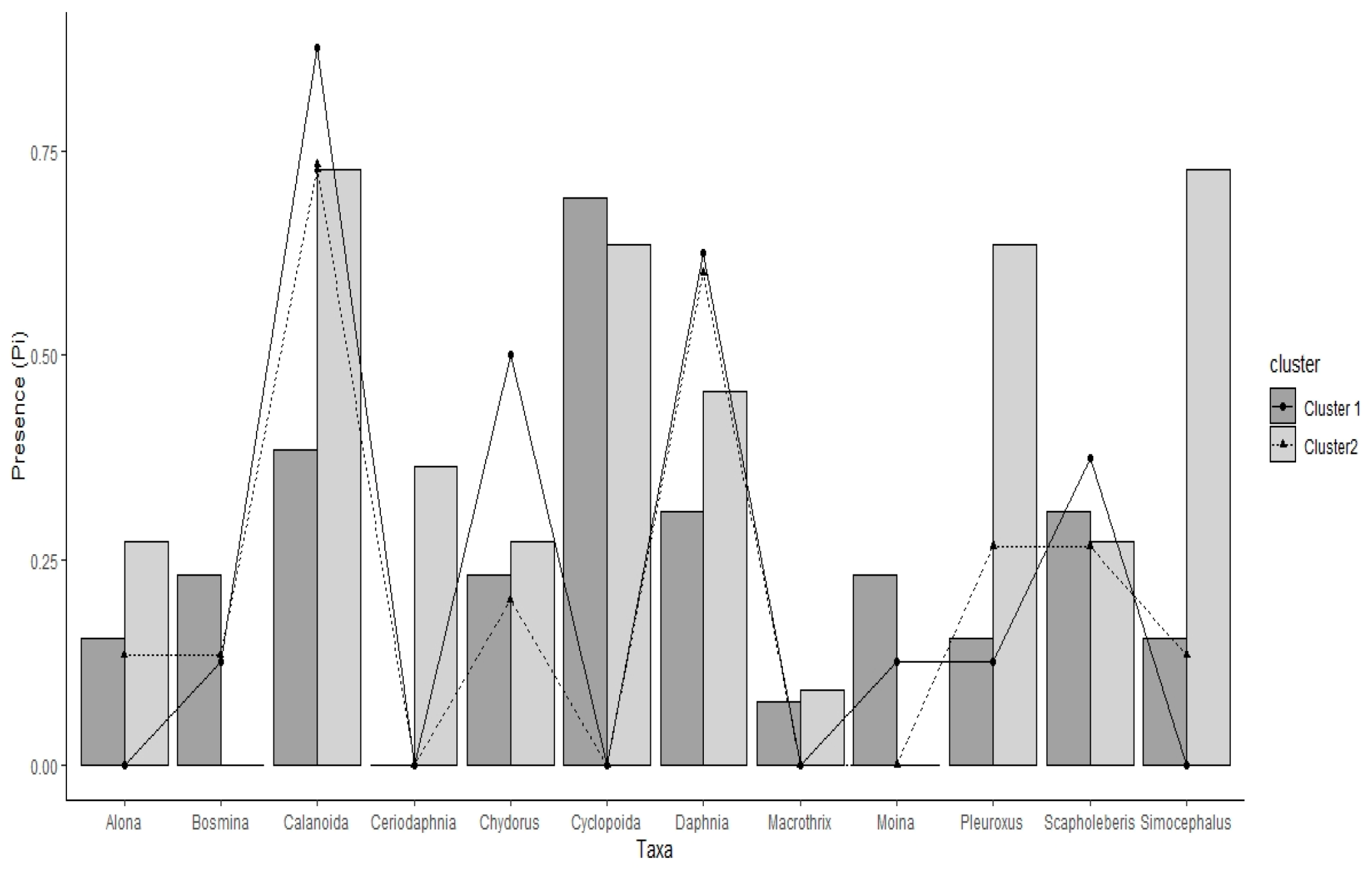
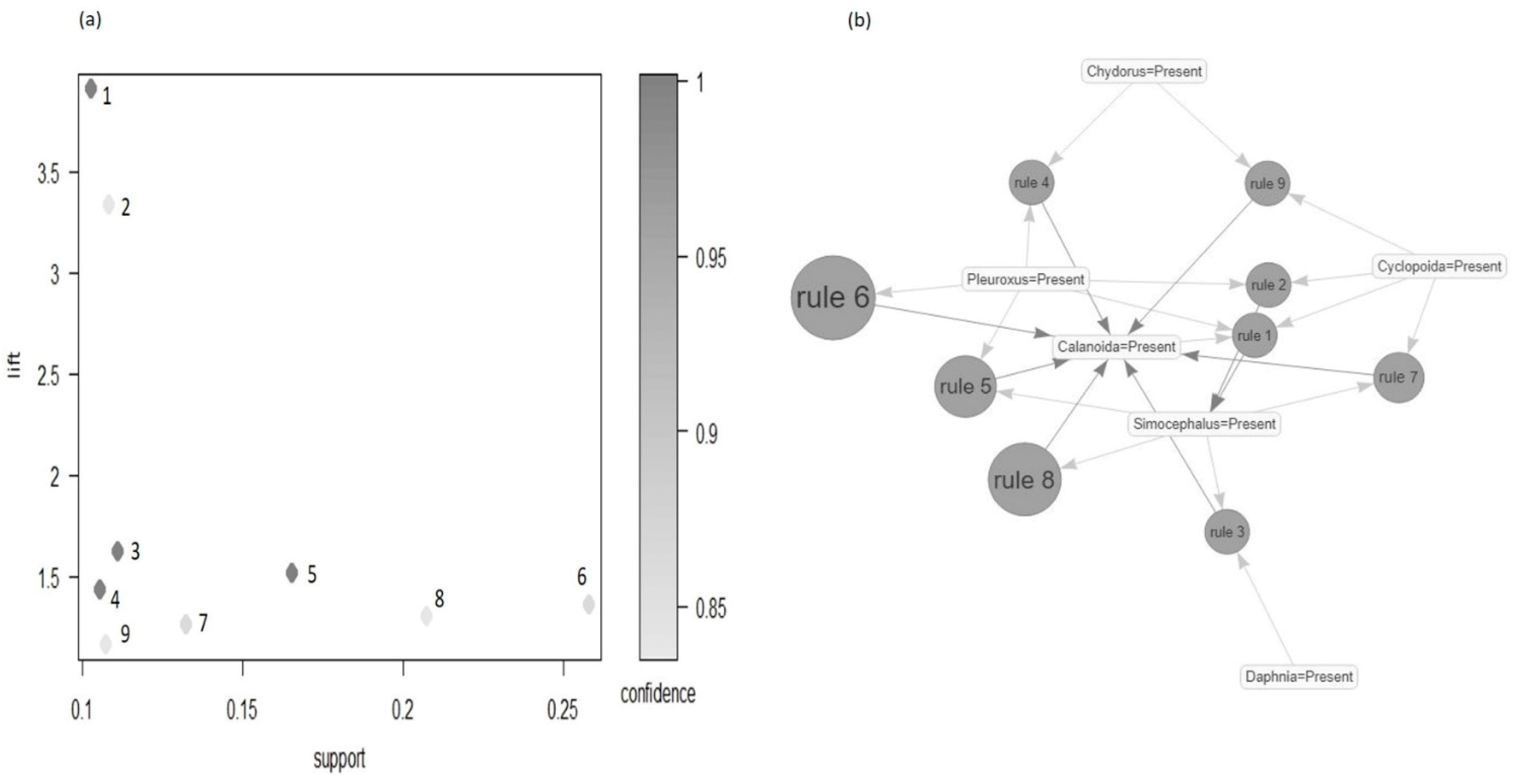
3.4. Community Structure and Association Rules
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rammer, W.; Seidl, R. Harnessing Deep Learning in Ecology: An Example Predicting Bark Beetle Outbreaks. Front. Plant Sci. 2019, 10, 1327. [Google Scholar] [CrossRef] [PubMed]
- Christin, S.; Hervet, É.; le Comte, N. Applications for deep learning in ecology. Methods Ecol. Evol. 2019, 10, 1632–1644. [Google Scholar] [CrossRef]
- Brownscombe, J.W.; Griffin, L.P.; Morley, D.; Acosta, A.; Hunt, J.; Lowerre-Barbieri, S.K.; Adams, A.J.; Danylchuk, A.J.; Cooke, S.J. Application of machine learning algorithms to identify cryptic reproductive habitats using diverse information sources. Oecologia 2020, 194, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Crisci, C.; Ghattas, B.; Perera, G. A review of supervised machine learning algorithms and their applications to ecological data. Ecol. Model. 2012, 240, 113–122. [Google Scholar] [CrossRef]
- Lek, S.; Guégan, J. Artificial neural networks as a tool in ecological modelling, an introduction. Ecol. Model. 1999, 120, 65–73. [Google Scholar] [CrossRef]
- Olden, J.D.; Lawler, J.J.; Poff, N.L. Machine Learning Methods Without Tears: A Primer for Ecologists. Q. Rev. Biol. 2008, 83, 171–193. [Google Scholar] [CrossRef] [Green Version]
- Recknagel, F. Applications of machine learning to ecological modelling. Ecol. Model. 2001, 146, 303–310. [Google Scholar] [CrossRef]
- Armitage, D.W.; Ober, H.K. A comparison of supervised learning techniques in the classification of bat echolocation calls. Ecol. Inform. 2010, 5, 465–473. [Google Scholar] [CrossRef]
- Lumini, A.; Nanni, L. Deep learning and transfer learning features for plankton classification. Ecol. Inform. 2019, 51, 33–43. [Google Scholar] [CrossRef]
- Mellios, N.; Moe, S.J.; Laspidou, C. Machine Learning Approaches for Predicting Health Risk of Cyanobacterial Blooms in Northern European Lakes. Water 2020, 12, 1191. [Google Scholar] [CrossRef] [Green Version]
- Lee, K.Y.; Chung, N.; Hwang, S. Application of an artificial neural network (ANN) model for predicting mosquito abundances in urban areas. Ecol. Inform. 2016, 36, 172–180. [Google Scholar] [CrossRef] [Green Version]
- Chon, T.-S.; Park, Y.-S.; Park, J.H. Determining temporal pattern of community dynamics by using unsupervised learning algorithms. Ecol. Model. 2000, 132, 151–166. [Google Scholar] [CrossRef]
- Fiorentino, D.; Pesch, R.; Guenther, C.-P.; Gutow, L.; Holstein, J.; Dannheim, J.; Ebbe, B.; Bildstein, T.; Schroeder, W.; Schuchardt, B.; et al. A ‘fuzzy clustering’ approach to conceptual confusion: How to classify natural ecological associations. Mar. Ecol. Prog. Ser. 2017, 584, 17–30. [Google Scholar] [CrossRef] [Green Version]
- Sperlea, T.; Kreuder, N.; Beisser, D.; Hattab, G.; Boenigk, J.; Heider, D. Quantification of the covariation of lake microbiomes and environmental variables using a machine learning-based framework. Mol. Ecol. 2021, 14. [Google Scholar] [CrossRef]
- Suppa, A.; Kvist, J.; Li, X.; Dhandapani, V.; Almulla, H.; Tian, A.Y.; Kissane, S.; Zhou, J.; Perotti, A.; Mangelson, H.; et al. Roundup causes embryonic development failure and alters metabolic pathways and gut microbiota functionality in non-target species. Microbiome 2020, 8, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Zimmermann, H.J. Practical Applications of Fuzzy Technologies; Springer: Boston, MA, USA, 1999. [Google Scholar]
- Salski, A. Fuzzy clustering of fuzzy ecological data. Ecol. Inform. 2007, 2, 262–269. [Google Scholar] [CrossRef]
- Equihua, M. Fuzzy Clustering of Ecological Data. J. Ecol. 1990, 78, 519. [Google Scholar] [CrossRef]
- Marsili-Libelli, S. Computer assisted vegetation analysis. In Handbook of Vegetation Science, 1st ed.; Feoli, E., Orloci, L., Eds.; Springer: Berlin/Heidelberg, Germany, 1991; Volume 11. [Google Scholar] [CrossRef]
- Odeh, I.O.A.; McBratney, A.B.; Chittleborough, D.J. Soil Pattern Recognition with Fuzzy-c-means: Application to Classification and Soil-Landform Interrelationships. Soil Sci. Soc. Am. J. 1992, 56, 505–516. [Google Scholar] [CrossRef]
- Friederichs, M.; Fränzle, O.; Salski, A. Fuzzy clustering of existing chemicals according to their ecotoxicological properties. Ecol. Model. 1996, 85, 27–40. [Google Scholar] [CrossRef]
- Zhang, S.; Wu, X. Fundamentals of association rules in data mining and knowledge discovery. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 97–116. [Google Scholar] [CrossRef]
- Nasreen, S.; Azam, M.A.; Shehzad, K.; Naeem, U.; Ghazanfar, M.A. Frequent Pattern Mining Algorithms for Finding Associated Frequent Patterns for Data Streams: A Survey. Procedia Comput. Sci. 2014, 37, 109–116. [Google Scholar] [CrossRef] [Green Version]
- Geng, L.; Hamilton, H.J. Interestingness measures for data mining. ACM Comput. Surv. 2006, 38, 24. [Google Scholar] [CrossRef]
- Han, J.; Cheng, H.; Xin, D.; Yan, X. Frequent pattern mining: Current status and future directions. Data Min. Knowl. Discov. 2007, 15, 55–86. [Google Scholar] [CrossRef] [Green Version]
- Céréghino, R.; Boix, D.; Cauchie, H.-M.; Martens, K.; Oertli, B. The ecological role of ponds in a changing world. Hydrobiologia 2014, 723, 1–6. [Google Scholar] [CrossRef] [Green Version]
- De Meester, L.; Declerck, S.; Stoks, R.; Louette, G.; van de Meutter, F.; de Bie, T.; Michels, E.; Brendonck, L. Ponds and pools as model systems in conservation biology, ecology and evolutionary biology. Aquat. Conserv. Mar. Freshw. Ecosyst. 2005, 15, 715–725. [Google Scholar] [CrossRef]
- Downing, A.L.; Leibold, M.A. Species richness facilitates ecosystem resilience in aquatic food webs. Freshw. Biol. 2010, 55, 2123–2137. [Google Scholar] [CrossRef]
- Verdonschot, R.C.M.; Keizer-Vlek, H.E.; Verdonschot, P.F.M. Biodiversity value of agricultural drainage ditches: A comparative analysis of the aquatic invertebrate fauna of ditches and small lakes. Aquat. Conserv. Mar. Freshw. Ecosyst. 2011, 21, 715–727. [Google Scholar] [CrossRef]
- Hassall, C. The ecology and biodiversity of urban ponds. Wiley Interdiscip. Rev. Water 2014, 1, 187–206. [Google Scholar] [CrossRef]
- Céréghino, R.; Biggs, J.; Oertli, B.; Declerck, S. The ecology of European ponds: Defining the characteristics of a neglected freshwater habitat. Hydrobiologia 2008, 597, 1–6. [Google Scholar] [CrossRef]
- Søndergaard, M.; Johansson, L.S.; Lauridsen, T.L.; Jørgensen, T.B.; Liboriussen, L.; Jeppesen, E. Submerged macrophytes as indicators of the ecological quality of lakes. Freshw. Biol. 2010, 55, 893–908. [Google Scholar] [CrossRef]
- Dodson, S.; Arnott, S.; Cottingham, K. The relationhip in lake communities between primary productivity and species richness. Ecology 2000, 81, 2662–2679. [Google Scholar] [CrossRef]
- Dzialowski, A.R. Invasive zebra mussels alter zooplankton responses to nutrient enrichment. Freshw. Sci. 2013, 32, 462–470. [Google Scholar] [CrossRef]
- Kruk, C.; Rodríguez-Gallego, L.; Meerhoff, M.; Quintans, F.; Lacerot, G.; Mazzeo, N.; Scasso, F.; Paggi, J.C.; Peeters, E.T.H.M.; Marten, S. Determinants of biodiversity in subtropical shallow lakes (Atlantic coast, Uruguay). Freshw. Biol. 2009, 54, 2628–2641. [Google Scholar] [CrossRef]
- Meerhoff, M.; Clemente, J.M.; de Mello, F.T.; Iglesias, C.; Pedersen, A.R.; Jeppesen, E. Can warm climate-related structure of littoral predator assemblies weaken the clear water state in shallow lakes? Glob. Chang. Biol. 2007, 13, 1888–1897. [Google Scholar] [CrossRef]
- Pinto-Coelho, R.; Pinel-Alloul, B.; Méthot, G.; Havens, K.E. Crustacean zooplankton in lakes and reservoirs of temperate and tropical regions: Variation with trophic status. Can. J. Fish. Aquat. Sci. 2005, 62, 348–361. [Google Scholar] [CrossRef] [Green Version]
- Wei, W.; Chen, R.; Wang, L.; Fu, L. Spatial distribution of crustacean zooplankton in a large river-connected lake related to trophic status and fish. J. Limnol. 2017, 76, 546–554. [Google Scholar] [CrossRef] [Green Version]
- Belfiore, N.M. Effects of contaminants on genetic patterns in aquatic organisms: A review. Mutat. Res. Mutat. Res. 2001, 489, 97–122. [Google Scholar] [CrossRef]
- Bossuyt, B.T.; Janssen, C.R. Copper toxicity to different field-collected cladoceran species: Intra- and inter-species sensitivity. Environ. Pollut. 2005, 136, 145–154. [Google Scholar] [CrossRef]
- Guan, R.; Wang, W.-X. Multigenerational cadmium acclimation and biokinetics in Daphnia magna. Environ. Pollut. 2006, 141, 343–352. [Google Scholar] [CrossRef]
- Hanazato, T. Influence of food density on the effects of a Chaoborus-released chemical on Daphnia ambigua. Freshw. Biol. 1991, 25, 477–483. [Google Scholar] [CrossRef]
- Hunter, K.; Pyle, G. Morphological Responses of Daphnia Pulex to Chaoborus Americanus Kairomone in the Presence and Absence of Metals. Environ. Toxicol. Chem. 2004, 23, 1311–1316. [Google Scholar] [CrossRef]
- Schindler, D.W. The cumulative effects of climate warming and other human stresses on Canadian freshwaters in the new millennium. Can. J. Fish. Aquat. Sci. 2001, 58, 18–29. [Google Scholar] [CrossRef]
- Schindler, D.W. Lakes as sentinels and integrators for the effects of climate change on watersheds, airsheds, and landscapes. Limnol. Oceanogr. 2009, 54, 2349–2358. [Google Scholar] [CrossRef]
- Riessen, H.P. Costs of predator-induced morphological defences in Daphnia. Freshw. Biol. 2012, 57, 1422–1433. [Google Scholar] [CrossRef]
- Vadadi-Fülöp, C.; Sipkay, C.; Mészáros, G.; Hufnagel, L. Climate change and freshwater zooplankton: What does it boil down to? Aquat. Ecol. 2012, 46, 501–519. [Google Scholar] [CrossRef] [Green Version]
- Rotiroti, M.; Bonomi, T.; Sacchi, E.; McArthur, J.M.; Stefania, G.A.; Zanotti, C.; Taviani, S.; Patelli, M.; Nava, V.; Soler, V.; et al. The effects of irrigation on groundwater quality and quantity in a human-modified hydro-system: The Oglio River basin, Po Plain, northern Italy. Sci. Total. Environ. 2019, 672, 342–356. [Google Scholar] [CrossRef] [PubMed]
- Rossi, V.; Maurone, C.; Benassi, G.; Marková, S.; Kotlík, P.; Bellin, N.; Ferrari, I. Phenology of Daphnia in a Northern Italy pond during the weather anomalous 2014. J. Limnol. 2015, 74, 74. [Google Scholar] [CrossRef] [Green Version]
- Marková, S.; Maurone, C.; Racchetti, E.; Bartoli, M.; Rossi, V. Daphnia diversity in water bodies of the Po River Basin. J. Limnol. 2016, 76, 261–271. [Google Scholar] [CrossRef] [Green Version]
- AAVV. Appunti Sulla Golena del Po. Le Lanche di Motta e Torricella del Pizzo; Comune di Cremona: Cremona, Italy, 1999. [Google Scholar]
- Anderson, L.G.; Hall, P.O.J.; Iverfeldt, A.; van der Loejf, M.M.R.; Sundby, B.; Westerlund, S.F.G. Benthic respiration measured by total carbonate production. Limnol. Oceanogr. 1986, 31, 319–329. [Google Scholar] [CrossRef] [Green Version]
- Valderrama, J.C. Methods Used by the Hydrographical Department of the National Board of Fisheries. In Report of the Baltic Intercalibration Workshop. Annex; Grasshof, K., Ed.; Interim Commission for the Protection of the Environment of the Baltic Sea: Goteborg, Sweden, 1977; pp. 14–43. [Google Scholar]
- Water Environmental Federation; American Public Health Association. Standard Methods for the Examination of Water and Wastewater; APHA: Washington, DC, USA, 1981. [Google Scholar]
- Rodier, J.; Legube, B.; Merlet, N. L’Analyse de l’ Eau; Dunod: Paris, France, 1987. [Google Scholar]
- D’Auria, G.; Zavagno, F. Indagine sui Bodri della Provincia di Cremona. Monogr. Pianura 1999, 3, 5–229. [Google Scholar]
- Bruce, P.; Bruce, A. Practical Statistics for Data Scientists; O’Reilly Media: Sebastobol, CA, USA, 2017. [Google Scholar]
- James, G.; Daniela, W.; Trevor, H.; Robert, T. An Introduction to Statistical Learning: With Applications in R; Springer Publishing Company, Inc: New York, NY, USA, 2014. [Google Scholar]
- Tilson, L.; Excell, P.; Green, R. A Generalisation of The Fuzzy C-means Clustering Algorithm. Int. Geosci. Remote Sens. Symp. Remote Sens. 2005, 3, 1783–1784. [Google Scholar] [CrossRef]
- Roubens, M. Fuzzy clustering algorithms and their cluster validity. Eur. J. Oper. Res. 1982, 10, 294–301. [Google Scholar] [CrossRef]
- Carlson, R.E. A trophic state index for lakes1. Limnol. Oceanogr. 1977, 22, 361–369. [Google Scholar] [CrossRef] [Green Version]
- Heino, J.; Grönroos, M.; Ilmonen, J.; Karhu, T.; Niva, M.; Paasivirta, L. Environmental heterogeneity and β diversity of stream macroinvertebrate communities at intermediate spatial scales. Freshw. Sci. 2013, 32, 142–154. [Google Scholar] [CrossRef]
- Anderson, M.J. Distance-Based Tests for Homogeneity of Multivariate Dispersions. Biometrics 2005, 62, 245–253. [Google Scholar] [CrossRef]
- Stier, A.C.; Geange, S.W.; Hanson, K.; Bolker, B.M. Predator density and timing of arrival affect reef fish community assembly. Ecology 2013, 94, 1057–1068. [Google Scholar] [CrossRef]
- Oksanen, J.; Blanchet, F.G.; Kindt, R.; Legendre, P.; Minchin, P.R.; O’Hara, R.; Simpson, G.L.; Solymos, P.; Stevens, M.H.H.; Wagner, H. Vegan: Community Ecology Package. Ordination Methods, Diversity Analysis and Other Functions for Community and Vegetation Ecologists; R Package Version. 2.5-7. 2020. Available online: https://CRAN.R-project.org/package=vegan (accessed on 27 April 2021).
- Baselga, A. Multiple site dissimilarity quantifies compositional heterogeneity among several sites, while average pairwise dissimilarity may be misleading. Ecography 2013, 36, 124–128. [Google Scholar] [CrossRef]
- Baselga, A.; Orme, C.D.L. Betapart: An R package for the study of beta diversity. Methods Ecol. Evol. 2012, 3, 808–812. [Google Scholar] [CrossRef]
- Baselga, A.; Orme, D.; Villeger, S.; de Bortoli, J.; Leprieur, F.; Logez, M. Betapart: Partitioning Beta Diversity into Turnover and Nestedness Components. R Package Version 1.5.2. 2020. Available online: https://CRAN.R-project.org/package=betapart (accessed on 27 April 2021).
- Rachor, E.; Reiss, H.; Degraer, S.; Duineveld, G.C.A.; van Hoey, G.; Lavaleye, M.; Willems, W.; Rees, H.L. Structure, distribution, and characterizing species of North Sea macro-zoobenthos communities in 2000. In Structure and dynamics of the North Sea benthos; Rees, H.L., Eggleton, J.D., Rachor, E., Vanden Berghe, E., Eds.; ICES Cooperative Research: Copenhagen, Danmark, 2007; Volume 288, pp. 46–59. [Google Scholar]
- Höppner, F. Association Rules. In Data Mining and Knowledge Discovery Handbook; Springer: Cham, Switzerland, 2009. [Google Scholar]
- Freitas, A.A. On objective measures of rule surprisingness. In Transactions on Petri Nets and Other Models of Concurrency XV; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 1998; Volume 1510, pp. 1–9. [Google Scholar]
- Silberschatz, A.; Tuzhilin, A. On Subjective Measures of Interestingness Discovery in Knowledge Bell Laboratories Measures. In Proceedings of the 1st International Conference on Knowledge Discovery and Data Mining, Montreal, QC, Canada, 20–21 August 1995; pp. 275–281. [Google Scholar]
- Agrawal, R.; Imieliński, T.; Swami, A. Mining association rules between sets of items in large databases. ACM SIGMOD Rec. 1993, 22, 207–216. [Google Scholar] [CrossRef]
- Chiu, S.-H.; Chen, C.-C.; Yuan, G.-F.; Lin, T.-H. Association algorithm to mine the rules that govern enzyme definition and to classify protein sequences. BMC Bioinform. 2006, 7, 304. [Google Scholar] [CrossRef]
- Frank, E.; Hal, L.M.A.; Witten, I.H. The WEKA Workbench. Online Appendix for “Data Mining: Practical Machine Learning Tools and Techniques, 4th ed.; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- Hahsler, M. ArulesViz: Visualizing Association Rules and Frequent Itemsets. R Package Version 1.3-3. 2019. Available online: https://CRAN.R-project.org/package=arulesViz (accessed on 27 April 2021).
- Hahsler, M.; Buchta, C.; Gruen, B.; Hornik, K. Arules: Mining Association Rules and Frequent Itemsets. R Package Version 1.6-6. 2020. Available online: https://CRAN.R-project.org/package=arules (accessed on 27 April 2021).
- Bennion, H.; Smith, M.A. Variability in the water chemistry of shallow ponds in southeast England, with special reference to the seasonality of nutrients and implications for modelling trophic status. Hydrobiologia 2000, 436, 145–158. [Google Scholar] [CrossRef]
- Lischeid, G.; Kalettka, T.; Holländer, M.; Steidl, J.; Merz, C.; Dannowski, R.; Hohenbrink, T.; Lehr, C.; Onandia, G.; Reverey, F.; et al. Natural ponds in an agricultural landscape: External drivers, internal processes, and the role of the terrestrial-aquatic interface. Limnologica 2018, 68, 5–16. [Google Scholar] [CrossRef]
- Marlene, P.; Kalettka, T.; Onandia, G.; Balla, D.; Lischeid, G.; Pätzig, M. How much information do we gain from multiple-year sampling in natural pond research? Limnologica 2020, 80, 125728. [Google Scholar] [CrossRef]
- Recknagel, F.; Michene, W.K. Ecological Informatics Data Management and Knowledge Discovery; Springer International Publishing AG: Cham, Switzerland, 2018. [Google Scholar]
- Humphries, G.R.W.; Huettmann, F. Machine Learning in Wildlife Biology: Algorithms, Data Issues and Availability, Workflows, Citizen Science, Code Sharing, Metadata and a Brief Historical Perspective; J.B. Metzler: Stuttgart, Germany, 2018; pp. 3–26. [Google Scholar]
- Senent-Aparicio, J.; Soto, J.; Pérez-Sánchez, J.; Garrido, J. A novel fuzzy clustering approach to regionalise watersheds with an automatic determination of optimal number of clusters. J. Hydrol. Hydromech. 2017, 65, 359–365. [Google Scholar] [CrossRef] [Green Version]
- Allen, A.P.; Whittier, T.R.; Kaufmann, P.R.; Larsen, D.P.; O’Connor, R.J.; Hughes, R.M.; Stemberger, R.S.; Dixit, S.S.; Brinkhurst, R.O.; Herlihy, A.T.; et al. Concordance of taxonomic richness patterns across multiple assemblages in lakes of the northeastern United States. Can. J. Fish. Aquat. Sci. 1999, 56, 739–747. [Google Scholar] [CrossRef]
- Allen, A.P.; Whittier, T.R.; Larsen, D.P.; Kaufmann, P.R.; O’Connor, R.J.; Hughes, R.M.; Stemberger, R.S.; Dixit, S.S.; Brinkhurst, R.O.; Herlihy, A.T.; et al. Concordance of taxonomic composition patterns across multiple lake assemblages: Effects of scale, body size, and land use. Can. J. Fish. Aquat. Sci. 1999, 56, 2029–2040. [Google Scholar] [CrossRef]
- Belyea, L.R.; Lancaster, J. Assembly within a contingent rules ecology. Oikos 2012, 86, 402–416. [Google Scholar] [CrossRef]
- Gyllström, M.; Hansson, L.-A.; Jeppesen, E.; Criado, F.G.; Gross, E.; Irvine, K.; Kairesalo, T.; Kornijow, R.; Miracle, M.R.; Nykänen, M.; et al. The role of climate in shaping zooplankton communities of shallow lakes. Limnol. Oceanogr. 2005, 50, 2008–2021. [Google Scholar] [CrossRef] [Green Version]
- Havens, K.E.; Hanazato, T. Zooplankton community responses to chemical stressors: A comparison of results from acidification and pesticide contamination research. Environ. Pollut. 1993, 82, 277–288. [Google Scholar] [CrossRef]
- Wellborn, G.A.; Skelly, D.K.; Werner, E.E. Mechanisms Creating Community Structure across a Freshwater Habitat Gradient. Annu. Rev. Ecol. Syst. 1996, 27, 337–363. [Google Scholar] [CrossRef] [Green Version]
- Arnott, S.E.; Vanni, M.J. Zooplankton Assemblages in Fishless Bog Lakes: Influence of Biotic and Abiotic Factors. Ecology 1993, 74, 2361–2380. [Google Scholar] [CrossRef]
- Steiner, C.F. Daphnia dominance and zooplankton community structure in fishless ponds. J. Plankton Res. 2004, 26, 799–810. [Google Scholar] [CrossRef] [Green Version]
- Weidman, P.R.; Schindler, D.W.; Thompson, P.; Vinebrooke, R.D. Interactive effects of higher temperature and dissolved organic carbon on planktonic communities in fishless mountain lakes. Freshw. Biol. 2014, 59, 889–904. [Google Scholar] [CrossRef]
- Wright, D.H.; Reeves, J.H. On the meaning and measurement of nestedness of species assemblages. Oecologia 1992, 92, 416–428. [Google Scholar] [CrossRef] [PubMed]
- Ulrich, W.; Gotelli, N.J. Null Model Analysis of Species Nestedness Patterns. Ecology 2007, 88, 1824–1831. [Google Scholar] [CrossRef] [PubMed]
- Gaston, K.J.; Blackburn, T.M. Pattern and Process in Macroecology; Gaston, K.J., Blackburn, T.M., Eds.; Wiley: Hoboaken, NY, USA, 2000; ISBN 9780632056538. [Google Scholar]
- Qian, H.; Ricklefs, R.E.; White, P.S. Beta diversity of angiosperms in temperate floras of eastern Asia and eastern North America. Ecol. Lett. 2004, 8, 15–22. [Google Scholar] [CrossRef]
- Gianuca, A.T.; Declerck, S.A.J.; Lemmens, P.; de Meester, L. Effects of dispersal and environmental heterogeneity on the replacement and nestedness components of β-diversity. Ecology 2017, 98, 525–533. [Google Scholar] [CrossRef] [PubMed]
- Margalef, R. Information Theory in Ecology. Gen. Syst. 1958, 3, 36–71. [Google Scholar]
- Gannon, J.E.; Stemberger, R.S. Zooplankton (Especially Crustaceans and Rotifers) as Indicators of Water Quality. Trans. Am. Microsc. Soc. 1978, 97, 16. [Google Scholar] [CrossRef]
- Mauchline, J. Advances in Marine Biology; The Biology of Calanoid Copepods, 1st ed.; Academic Press: San Diego, CA, USA, 1998. [Google Scholar]
- Burns, C.W.; Schallenberg, M. Calanoid copepods versus cladocerans: Consumer effects on protozoa in lakes of different trophic status. Limnol. Oceanogr. 2001, 46, 1558–1565. [Google Scholar] [CrossRef]
- Iii, F.S.C.; Zavaleta, E.S.; Eviner, V.T.; Naylor, R.L.; Vitousek, P.M.; Reynolds, H.L.; Hooper, D.U.; Lavorel, S.; Sala, O.E.; Hobbie, S.E.; et al. Consequences of changing biodiversity. Nat. Cell Biol. 2000, 405, 234–242. [Google Scholar] [CrossRef]
- Doubek, J.P.; Campbell, K.L.; Lofton, M.E.; McClure, R.P.; Carey, C.C. Hypolimnetic Hypoxia Increases the Biomass Variability and Compositional Variability of Crustacean Zooplankton Communities. Water 2019, 11, 2179. [Google Scholar] [CrossRef] [Green Version]
- Hébert, M.-P.; Beisner, B.E.; Maranger, R. Linking zooplankton communities to ecosystem functioning: Toward an effect-trait framework. J. Plankton Res. 2017, 39, 3–12. [Google Scholar] [CrossRef] [Green Version]
- Sterner, R.W.; Elser, J.J. Ecological Stoichiometry: The Biology of Elements from Molecules to the Biosphere; Princeton University Press: Princeton, NJ, USA, 2002; pp. 46–59. [Google Scholar]
- Barnett, A.J.; Finlay, K.; Beisner, B.E. Functional diversity of crustacean zooplankton communities: Towards a trait-based classification. Freshw. Biol. 2007, 52, 796–813. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Enviromental Features | VIF (2014) | VIF (2015) |
|---|---|---|
| Water temperature (wT) | 1.40 | 1.69 |
| pH | 3.90 | 2.15 |
| Oxygen (O2) | >4 | >4 |
| Conductivity (EC) | 1.96 | 2.78 |
| Ammonia (NH4+) | >4 | 3.88 |
| Dissolved inorganic carbon (DIC) | >4 | 1.81 |
| Soluble reactive phosphorus (SRP) | 1.99 | 1.90 |
| Nitrate (NO3−) | 1.22 | 2.25 |
| Chlorophyll-a (Chla) | 2.38 | 1.29 |
| Silica (SiO2) | 2.06 | 2.60 |
| Depth | 1.33 | 1.97 |
| Perimeter | 1.32 | 1.74 |
| Ponds | 2014 | 2015 | ||
|---|---|---|---|---|
| Cluster 1 | Cluster 2 | Cluster 1 | Cluster 2 | |
| Pastore 3 | 0.72 | 0.28 | 0.63 | 0.37 |
| Pastore 1 | 0.14 | 0.86 | 0.77 | 0.23 |
| Pastore 4 | 0.56 | 0.432 | 0.11 | 0.89 |
| Temporanea | 0.30 | 0.70 | 0.41 | 0.59 |
| Bosco Braca | 0.88 | 0.12 | 0.13 | 0.87 |
| Pavarini | 0.93 | 0.07 | 0.26 | 0.74 |
| Bosco Valloni | 0.41 | 0.59 | 0.31 | 0.69 |
| San Giorgio | 0.08 | 0.92 | 0.33 | 0.67 |
| Forche | 0.39 | 0.61 | 0.10 | 0.90 |
| Martignana | 0.29 | 0.71 | 0.29 | 0.71 |
| Santa Maria Maddalena | 0.88 | 0.12 | 0.34 | 0.66 |
| Bosco Bodini | 0.65 | 0.35 | - | - |
| Cacina Mortara | 0.18 | 0.82 | 0.72 | 0.28 |
| Bosco Piazza | 0.03 | 0.97 | 0.30 | 0.70 |
| Cascina Tavernelle | 0.09 | 0.91 | 0.25 | 0.75 |
| Vecchio | 0.63 | 0.37 | 0.79 | 0.21 |
| Bazzi | 0.72 | 0.28 | 0.57 | 0.43 |
| Motta | 0.75 | 0.25 | 0.81 | 0.19 |
| Ronchetto | 0.91 | 0.09 | 0.22 | 0.77 |
| Rita | 0.54 | 0.46 | 0.42 | 0.58 |
| Bicocca | 0.26 | 0.74 | 0.77 | 0.23 |
| Pescaroli West | 0.93 | 0.072 | 0.12 | 0.88 |
| Pescaroli East | 0.17 | 0.83 | 0.70 | 0.30 |
| Sabbie | 0.61 | 0.39 | 0.28 | 0.72 |
| Enviromental Features | Prototypes 2014 | Prototypes 2015 | ||
|---|---|---|---|---|
| Cluster 1 | Cluster 2 | Cluster 1 | Cluster 2 | |
| Water temperature (wT) | 20.29 | 17.69 | 23.49 | 23.92 |
| pH | 8.00 | 7.63 | 7.67 | 7.71 |
| Conductivity (EC) | 542.18 | 673.30 | 584.32 | 364.03 |
| Ammonia (NH4+) | - | - | 3.58 | 2.35 |
| Dissolved inorganic carbon (DIC) | - | - | 0.65 | 0.24 |
| Soluble reactive phosphorus (SRP) | 0.058 | 0.18 | 0.098 | 0.044 |
| Nitrate (NO3–) | 0.11 | 0.17 | 0.17 | 0.15 |
| Chlorophyll-a (Chla) | 2.70 | 0.90 | 3.44 | 4.46 |
| Silica (SiO2) | 2.44 | 2.24 | 14.30 | 7.47 |
| Depth | 4.28 | 4.18 | 4.50 | 4.02 |
| Perimeter | 209.08 | 205.97 | 221.58 | 204.73 |
| Beta Diversity | 2014 | 2015 | Overall 2014 | Overall 2015 | α | ||||
|---|---|---|---|---|---|---|---|---|---|
| Cluster 1 | Cluster 2 | α | Cluster 1 | Cluster 2 | α | ||||
| βSOR | 0.85 | 0.76 | <0.0001 | 0.71 | 0.84 | <0.0001 | 0.89 | 0.87 | <0.0001 |
| βSNE | 0.07 | 0.14 | <0.0001 | 0.19 | 0.15 | <0.0001 | 0.07 | 0.12 | <0.0001 |
| βSIM | 0.78 | 0.61 | <0.0001 | 0.52 | 0.69 | <0.0001 | 0.82 | 0.75 | <0.0001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bellin, N.; Racchetti, E.; Maurone, C.; Bartoli, M.; Rossi, V. Unsupervised Machine Learning and Data Mining Procedures Reveal Short Term, Climate Driven Patterns Linking Physico-Chemical Features and Zooplankton Diversity in Small Ponds. Water 2021, 13, 1217. https://doi.org/10.3390/w13091217
Bellin N, Racchetti E, Maurone C, Bartoli M, Rossi V. Unsupervised Machine Learning and Data Mining Procedures Reveal Short Term, Climate Driven Patterns Linking Physico-Chemical Features and Zooplankton Diversity in Small Ponds. Water. 2021; 13(9):1217. https://doi.org/10.3390/w13091217
Chicago/Turabian StyleBellin, Nicolò, Erica Racchetti, Catia Maurone, Marco Bartoli, and Valeria Rossi. 2021. "Unsupervised Machine Learning and Data Mining Procedures Reveal Short Term, Climate Driven Patterns Linking Physico-Chemical Features and Zooplankton Diversity in Small Ponds" Water 13, no. 9: 1217. https://doi.org/10.3390/w13091217