
Coupling Process-Based Models and Machine Learning Algorithms for Predicting Yield and Evapotranspiration of Maize in Arid Environments
 , , , and
, , , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Calibration of DSSAT Model
2.2. Development of the Simulated Dataset
2.3. Machine Learning Models Development and Testing
2.4. Feature Importance and Meta-Model Comparison with DSSAT Model
3. Results and Discussion
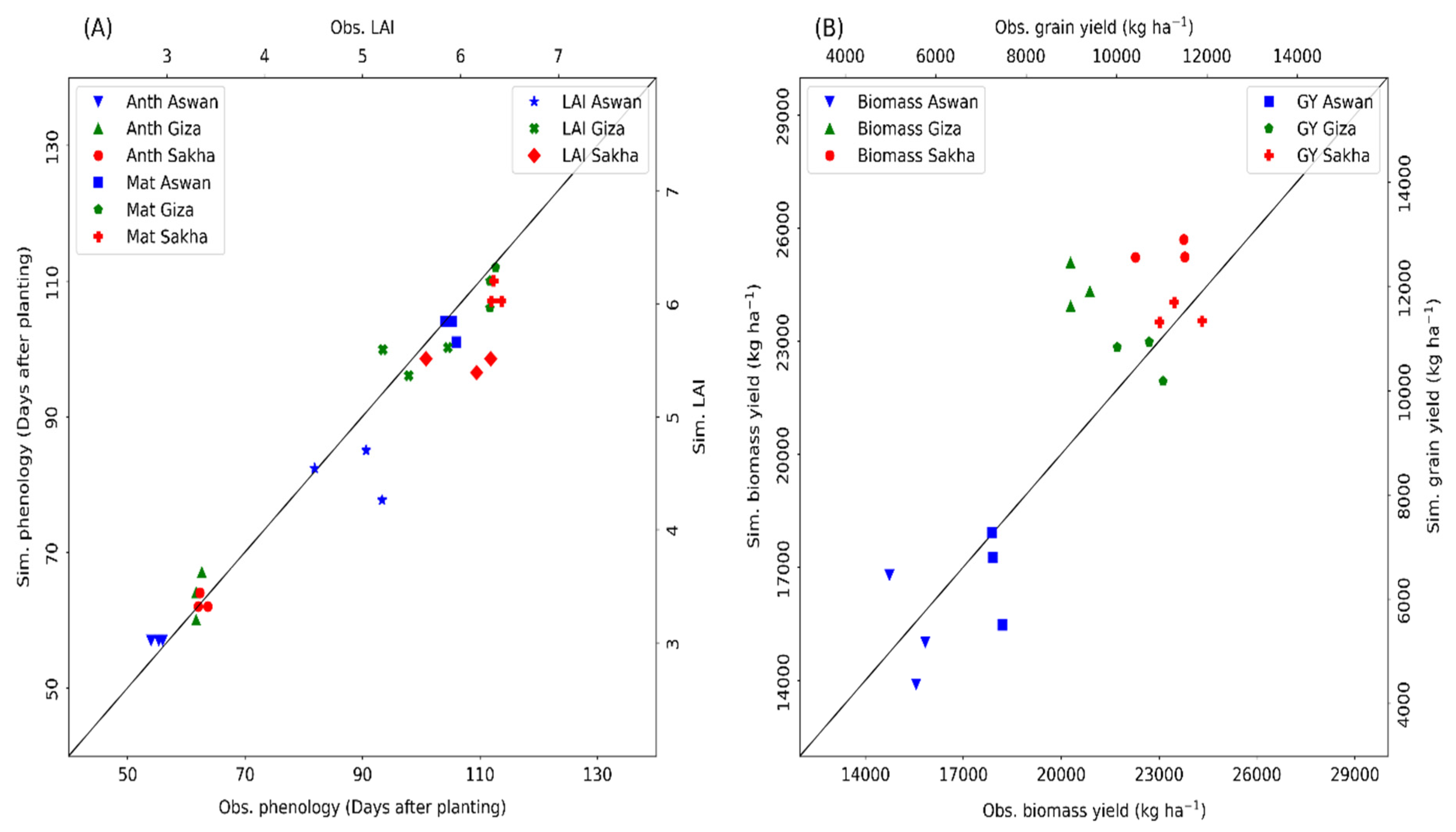
3.1. Validation of DSSAT Maize Model
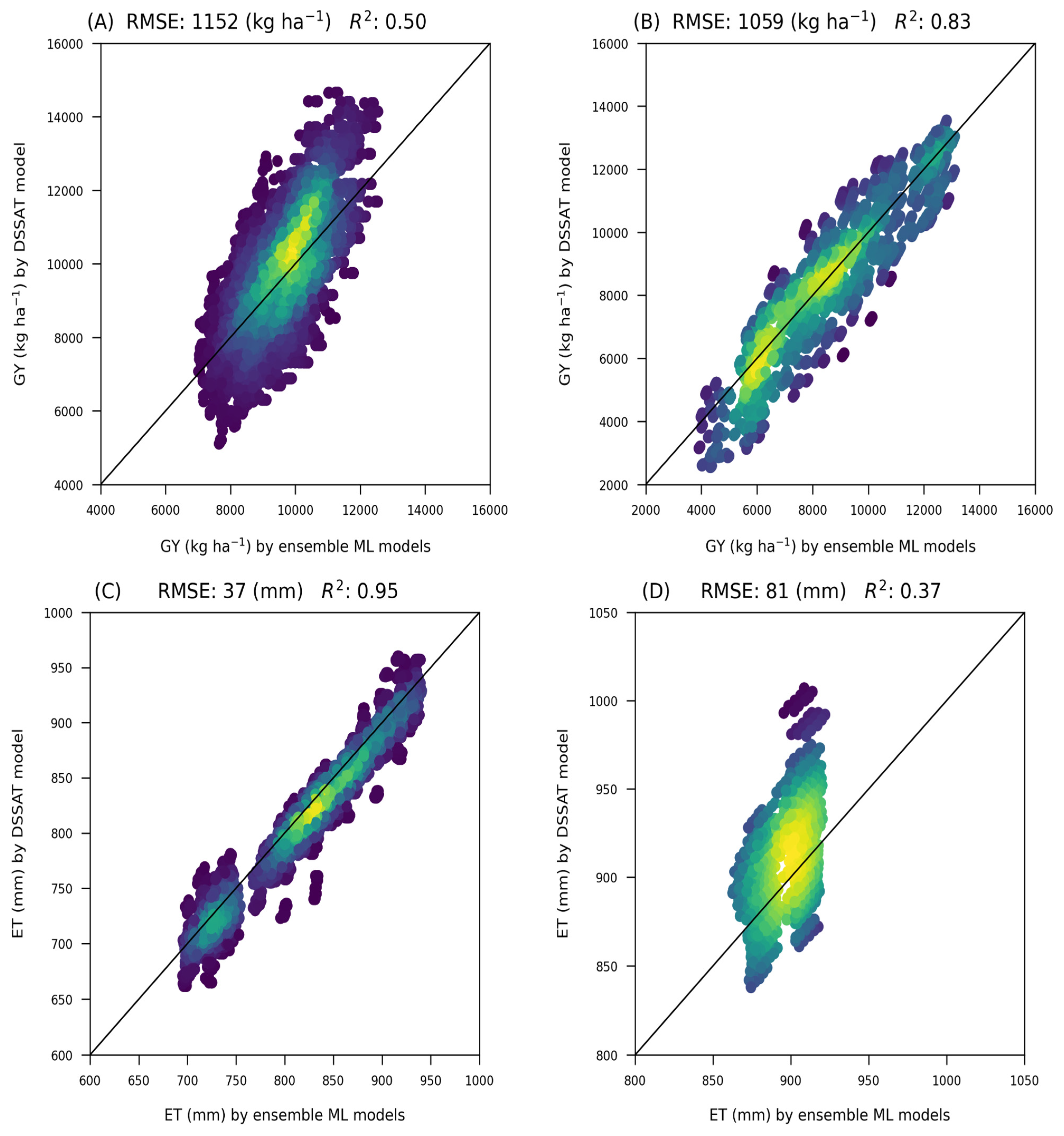
3.2. Evaluation of Trained ML Algorithms
3.3. Predicted Grain Yield and Water Use by DSSAT and ML Algorithms under Broad Range of Management and Environmental Practices
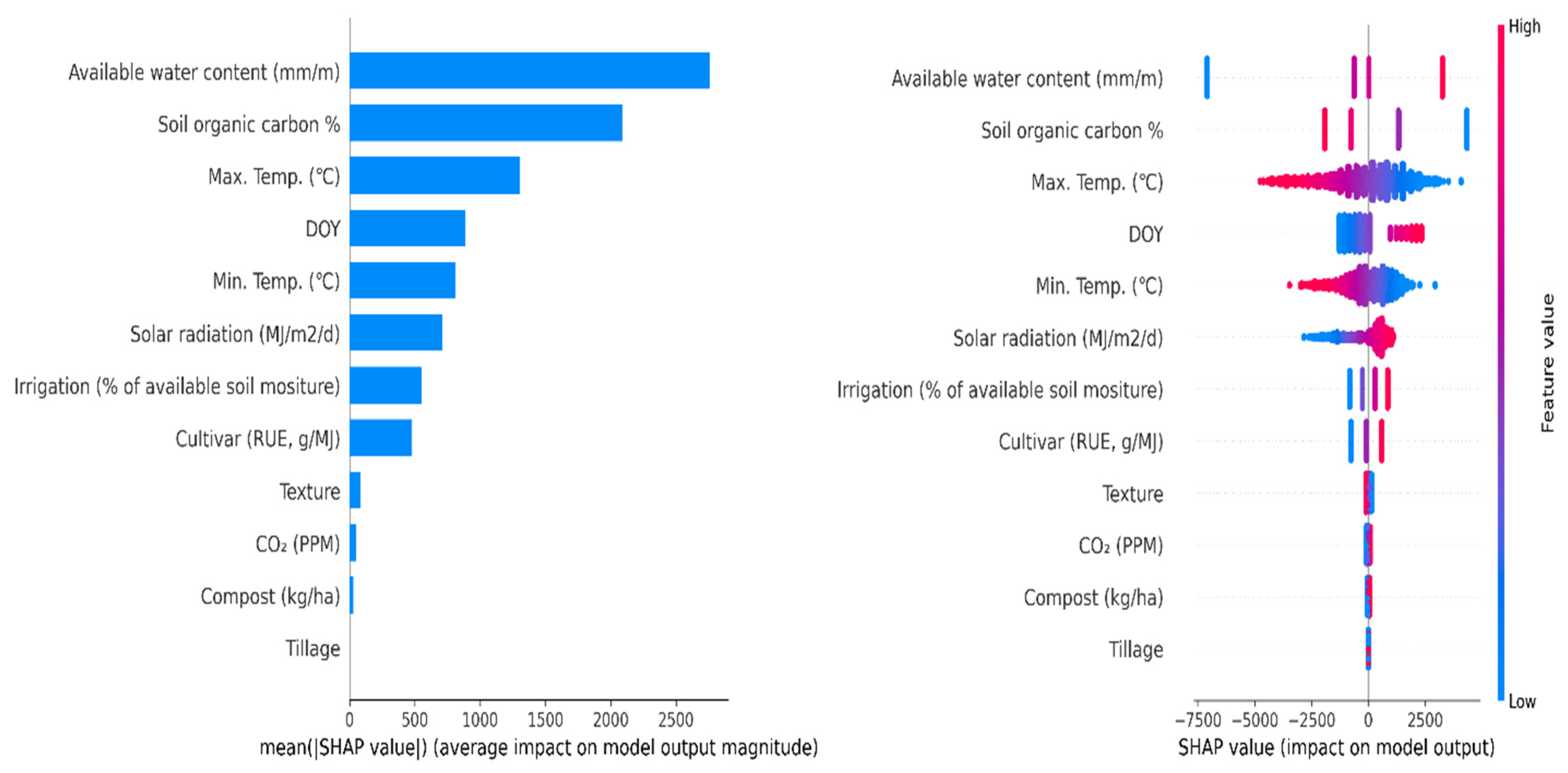
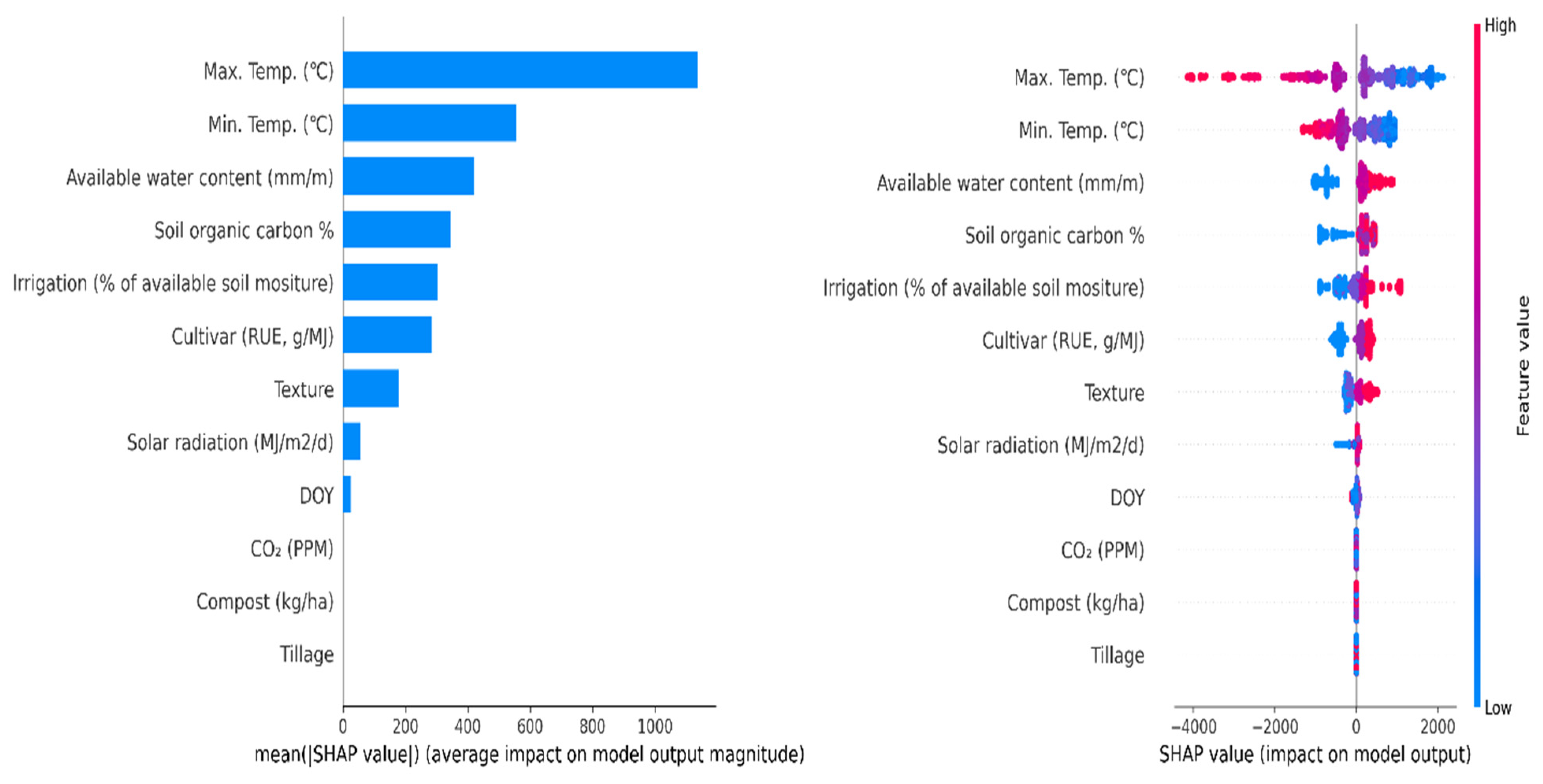
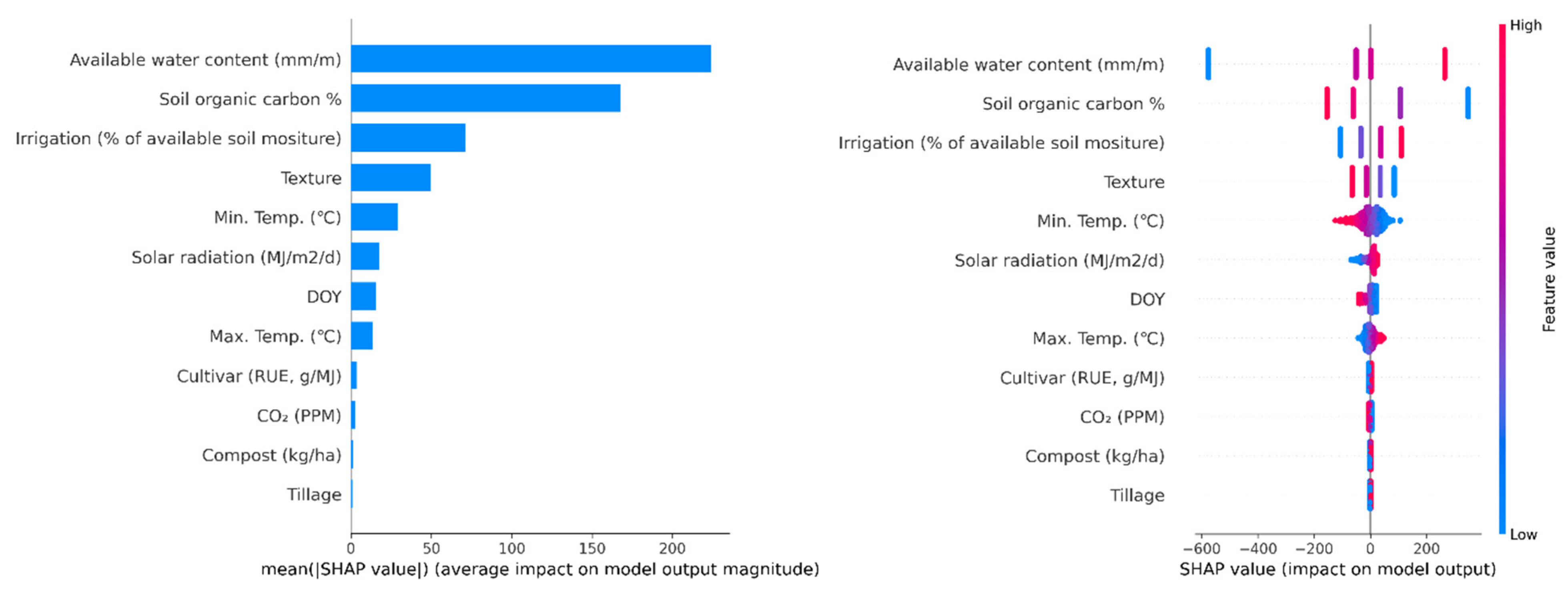
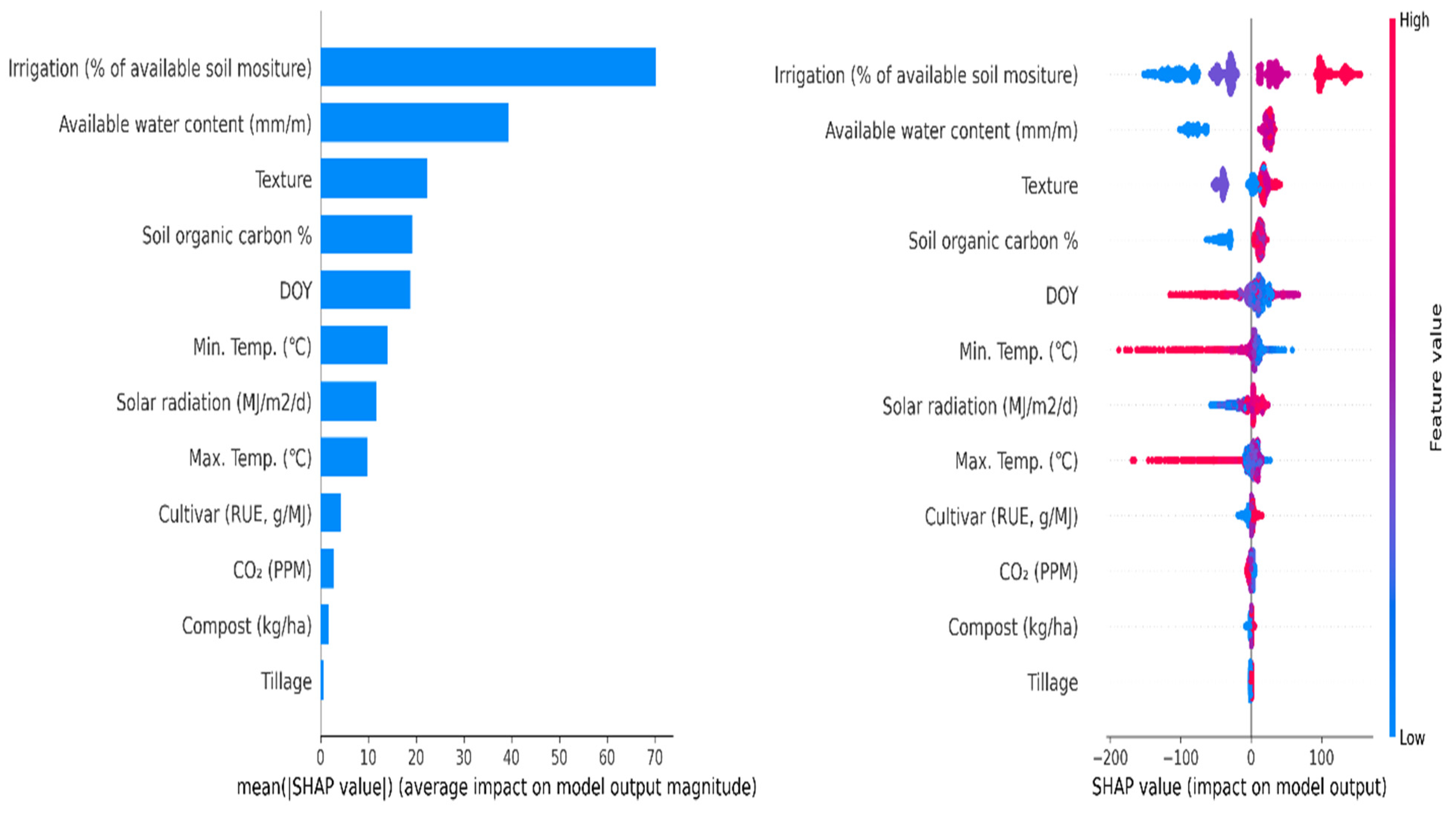
3.4. The Most Important Variables
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gomaa, M.A.; Kandil, E.E.; El-Dein, A.A.M.Z.; Abou-Donia, M.E.M.; Ali, H.M.; Abdelsalam, N.R. Increase maize productivity and water use efficiency through application of potassium silicate under water stress. Sci. Rep. 2021, 11, 224. [Google Scholar] [CrossRef] [PubMed]
- Ranum, P.; Peña-Rosas, J.P.; Garcia-Casal, M.N. Global maize production, utilization, and consumption. Ann. N. Y. Acad. Sci. 2014, 1312, 105–112. [Google Scholar] [CrossRef]
- Maroufpoor, S.; Bozorg-Haddad, O.; Maroufpoor, E.; Gerbens-Leenes, P.W.; Loáiciga, H.A.; Savic, D.; Singh, V.P. Optimal virtual water flows for improved food security in water-scarce countries. Sci. Rep. 2021, 11, 21027. [Google Scholar] [CrossRef] [PubMed]
- McLaughlin, D.; Kinzelbach, W. Food security and sustainable resource management. Water Resour. Res. 2015, 51, 4966–4985. [Google Scholar] [CrossRef]
- Köberle, A.C. Food security in climate mitigation scenarios. Nat. Food 2022, 3, 98–99. [Google Scholar] [CrossRef]
- Godfray, H.C.J.; Beddington, J.R.; Crute, I.R.; Haddad, L.; Lawrence, D.; Muir, J.F.; Pretty, J.; Robinson, S.; Thomas, S.M.; Toulmin, C. Food Security: The Challenge of Feeding 9 Billion People. Science 2010, 327, 812–818. [Google Scholar] [CrossRef] [Green Version]
- Bentley, A.R.; Donovan, J.; Sonder, K.; Baudron, F.; Lewis, J.M.; Voss, R.; Rutsaert, P.; Poole, N.; Kamoun, S.; Saunders, D.G.O.; et al. Near- to long-term measures to stabilize global wheat supplies and food security. Nat. Food 2022, 3, 483–486. [Google Scholar] [CrossRef]
- Gholami, R.; Zahedi, S.M. Identifying superior drought-tolerant olive genotypes and their biochemical and some physiological responses to various irrigation levels. J. Plant Nutr. 2019, 42, 2057–2069. [Google Scholar] [CrossRef]
- Çakir, R. Effect of water stress at different development stages on vegetative and reproductive growth of corn. Field Crops Res. 2004, 89, 1–16. [Google Scholar] [CrossRef]
- Kheir, A.M.S.; Alrajhi, A.A.; Ghoneim, A.M.; Ali, E.F.; Magrashi, A.; Zoghdan, M.G.; Abdelkhalik, S.A.M.; Fahmy, A.E.; Elnashar, A. Modeling deficit irrigation-based evapotranspiration optimizes wheat yield and water productivity in arid regions. Agric. Water Manag. 2021, 256, 107122. [Google Scholar] [CrossRef]
- Clothier, B.; Jovanovic, N.; Zhang, X. Reporting on water productivity and economic performance at the water-food nexus. Agric. Water Manag. 2020, 237, 106123. [Google Scholar] [CrossRef]
- Srivastava, A.; Sahoo, B.; Raghuwanshi, N.S.; Chatterjee, C. Modelling the dynamics of evapotranspiration using Variable Infiltration Capacity model and regionally calibrated Hargreaves approach. Irrig. Sci. 2018, 36, 289–300. [Google Scholar] [CrossRef]
- Sahoo, B.; Walling, I.; Deka, B.C.; Bhatt, B.P. Standardization of Reference Evapotranspiration Models for a Subhumid Valley Rangeland in the Eastern Himalayas. J. Irrig. Drain. Eng. 2012, 138, 880–895. [Google Scholar] [CrossRef]
- Kumar, U.; Sahoo, B.; Chatterjee, C.; Raghuwanshi, N.S. Evaluation of Simplified Surface Energy Balance Index (S-SEBI) Method for Estimating Actual Evapotranspiration in Kangsabati Reservoir Command Using Landsat 8 Imagery. J. Indian Soc. Remote Sens. 2020, 48, 1421–1432. [Google Scholar] [CrossRef]
- Lama, G.F.C.; Sadeghifar, T.; Azad, M.T.; Sihag, P.; Kisi, O. On the Indirect Estimation of Wind Wave Heights over the Southern Coasts of Caspian Sea: A Comparative Analysis. Water 2022, 14, 843. [Google Scholar] [CrossRef]
- Kirches, G.; Paperin, M.; Klein, H.; Brockmann, C.; Stelzer, K. GRADHIST—A method for detection and analysis of oceanic fronts from remote sensing data. Remote Sens. Environ. 2016, 181, 264–280. [Google Scholar] [CrossRef]
- Sadeghifar, T.; Lama, G.F.C.; Sihag, P.; Bayram, A.; Kisi, O. Wave height predictions in complex sea flows through soft-computing models: Case study of Persian Gulf. Ocean. Eng. 2022, 245, 110467. [Google Scholar] [CrossRef]
- Hara, P.; Piekutowska, M.; Niedbała, G. Selection of Independent Variables for Crop Yield Prediction Using Artificial Neural Network Models with Remote Sensing Data. Land 2021, 10, 609. [Google Scholar] [CrossRef]
- Jiang, L.; Yang, Y.; Shang, S. Remote Sensing—Based Assessment of the Water-Use Efficiency of Maize over a Large, Arid, Regional Irrigation District. Remote Sens. 2022, 14, 2035. [Google Scholar] [CrossRef]
- Kheir, A.M.S.; Hoogenboom, G.; Ammar, K.A.; Ahmed, M.; Feike, T.; Elnashar, A.; Liu, B.; Ding, Z.; Asseng, S. Minimizing trade-offs between wheat yield and resource-use efficiency in the Nile Delta—A multi-model analysis. Field Crops Res. 2022, 287, 108638. [Google Scholar] [CrossRef]
- Attia, A.; Rajan, N.; Nair, S.S.; DeLaune, P.B.; Xue, Q.; Ibrahim, A.M.H.; Hays, D.B. Modeling Cotton Lint Yield and Water Use Efficiency Responses to Irrigation Scheduling Using Cotton2K. Agron. J. 2016, 108, 1614–1623. [Google Scholar] [CrossRef]
- Ding, Z.; Ali, E.F.; Elmahdy, A.M.; Ragab, K.E.; Seleiman, M.F.; Kheir, A.M.S. Modeling the combined impacts of deficit irrigation, rising temperature and compost application on wheat yield and water productivity. Agric. Water Manag. 2021, 244, 106626. [Google Scholar] [CrossRef]
- Asseng, S.; Jamieson, P.D.; Kimball, B.; Pinter, P.; Sayre, K.; Bowden, J.W.; Howden, S.M. Simulated wheat growth affected by rising temperature, increased water deficit and elevated atmospheric CO2. Field Crops Res. 2004, 85, 85–102. [Google Scholar] [CrossRef]
- Martre, P.; Wallach, D.; Asseng, S.; Ewert, F.; Jones, J.W.; Rötter, R.P.; Boote, K.J.; Ruane, A.C.; Thorburn, P.J.; Cammarano, D.; et al. Multimodel ensembles of wheat growth: Many models are better than one. Glob. Change Biol. 2015, 21, 911–925. [Google Scholar] [CrossRef] [PubMed]
- Hoogenboom, G.; Porter, C.H.; Boote, K.J.; Shelia, V.; Wilkens, P.W.; Singh, U.; White, J.W.; Asseng, S.; Lizaso, J.I.; Moreno, L.P.; et al. The DSSAT crop modeling ecosystem. In Advances in Crop Modeling for a Sustainable Agriculture; Boote, K.J., Ed.; Burleigh Dodds Science Publishing: Cambridge, UK, 2019; pp. 173–216. [Google Scholar] [CrossRef]
- Kothari, K.; Ale, S.; Attia, A.; Rajan, N.; Xue, Q.; Munster, C.L. Potential climate change adaptation strategies for winter wheat production in the Texas High Plains. Agric. Water Manag. 2019, 225, 105764. [Google Scholar] [CrossRef]
- Attia, A.; El-Hendawy, S.; Al-Suhaibani, N.; Tahir, M.U.; Mubushar, M.; Vianna, M.d.S.; Ullah, H.; Mansour, E.; Datta, A. Sensitivity of the DSSAT model in simulating maize yield and soil carbon dynamics in arid Mediterranean climate: Effect of soil, genotype and crop management. Field Crops Res. 2021, 260, 107981. [Google Scholar] [CrossRef]
- Ali, M.G.M.; Ahmed, M.; Ibrahim, M.M.; El Baroudy, A.A.; Ali, E.F.; Shokr, M.S.; Aldosari, A.A.; Majrashi, A.; Kheir, A.M.S. Optimizing sowing window, cultivar choice, and plant density to boost maize yield under RCP8.5 climate scenario of CMIP5. Int. J. Biometeorol. 2022, 66, 971–985. [Google Scholar] [CrossRef]
- Van Ittersum, M.K.; Cassman, K.G.; Grassini, P.; Wolf, J.; Tittonell, P.; Hochman, Z. Yield gap analysis with local to global relevance—A review. Field Crops Res. 2013, 143, 4–17. [Google Scholar] [CrossRef] [Green Version]
- Gustafson, D.I.; Jones, J.W.; Porter, C.H.; Hyman, G.; Edgerton, M.D.; Gocken, T.; Shryock, J.; Doane, M.; Budreski, K.; Stone, C. Climate adaptation imperatives: Untapped global maize yield opportunities. Int. J. Agric. Sustain. 2014, 12, 471–486. [Google Scholar] [CrossRef]
- Lama, G.F.C.; Errico, A.; Pasquino, V.; Mirzaei, S.; Preti, F.; Chirico, G.B. Velocity uncertainty quantification based on Riparian vegetation indices in open channels colonized by Phragmites australis. J. Ecohydraulics 2022, 7, 71–76. [Google Scholar] [CrossRef]
- Khan, M.A.; Sharma, N.; Lama, G.F.C.; Hasan, M.; Garg, R.; Busico, G.; Alharbi, R.S. Three-Dimensional Hole Size (3DHS) Approach for Water Flow Turbulence Analysis over Emerging Sand Bars: Flume-Scale Experiments. Water 2022, 14, 1889. [Google Scholar] [CrossRef]
- Lobell, D.B.; Asseng, S. Comparing estimates of climate change impacts from process-based and statistical crop models. Environ. Res. Lett. 2017, 12, 015001. [Google Scholar] [CrossRef]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N.; Prabhat. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef] [PubMed]
- Kheir, A.M.S.; Ammar, K.A.; Amer, A.; Ali, M.G.M.; Ding, Z.; Elnashar, A. Machine learning-based cloud computing improved wheat yield simulation in arid regions. Comput. Electron. Agric. 2022, 203, 107457. [Google Scholar] [CrossRef]
- Dou, X.; Yang, Y. Evapotranspiration estimation using four different machine learning approaches in different terrestrial ecosystems. Comput. Electron. Agric. 2018, 148, 95–106. [Google Scholar] [CrossRef]
- Rashid Niaghi, A.; Hassanijalilian, O.; Shiri, J. Estimation of Reference Evapotranspiration Using Spatial and Temporal Machine Learning Approaches. Hydrology 2021, 8, 25. [Google Scholar] [CrossRef]
- Shahhosseini, M.; Martinez-Feria, R.A.; Hu, G.; Archontoulis, S.V. Maize yield and nitrate loss prediction with machine learning algorithms. Environ. Res. Lett. 2019, 14, 124026. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Gao, P.; Zhu, X.; Guo, W.; Ding, J.; Li, C.; Zhu, M.; Wu, X. Design of an integrated climatic assessment indicator (ICAI) for wheat production: A case study in Jiangsu Province, China. Ecol. Indic. 2019, 101, 943–953. [Google Scholar] [CrossRef]
- Shahhosseini, M.; Hu, G.; Archontoulis, S.V. Forecasting Corn Yield With Machine Learning Ensembles. Front. Plant Sci. 2020, 11, 1120. [Google Scholar] [CrossRef]
- Srivastava, A.K.; Safaei, N.; Khaki, S.; Lopez, G.; Zeng, W.; Ewert, F.; Gaiser, T.; Rahimi, J. Winter wheat yield prediction using convolutional neural networks from environmental and phenological data. Sci. Rep. 2022, 12, 3215. [Google Scholar] [CrossRef]
- Van der Laan, M.J.; Polley, E.C.; Hubbard, A.E. Super learner. Stat. Appl. Genet. Mol. Biol. 2007, 6. Article25. [Google Scholar] [CrossRef] [PubMed]
- Naimi, A.I.; Balzer, L.B. Stacked generalization: An introduction to super learning. Eur. J. Epidemiol. 2018, 33, 459–464. [Google Scholar] [CrossRef] [PubMed]
- Altmann, A.; Toloşi, L.; Sander, O.; Lengauer, T. Permutation importance: A corrected feature importance measure. Bioinformatics 2010, 26, 1340–1347. [Google Scholar] [CrossRef] [Green Version]
- Attia, A.; El-Hendawy, S.; Al-Suhaibani, N.; Alotaibi, M.; Tahir, M.U.; Kamal, K.Y. Evaluating deficit irrigation scheduling strategies to improve yield and water productivity of maize in arid environment using simulation. Agric. Water Manag. 2021, 249, 106812. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing, R Foundation for Statistical Computing; R Core Team: Vienna, Austria, 2020; Available online: https://www.R-project.org/ (accessed on 1 March 2022).
- Pasquel, D.; Roux, S.; Richetti, J.; Cammarano, D.; Tisseyre, B.; Taylor, J.A. A review of methods to evaluate crop model performance at multiple and changing spatial scales. Precis. Agric. 2022, 23, 1489–1513. [Google Scholar] [CrossRef]
- Nyéki, A.; Kerepesi, C.; Daróczy, B.; Benczúr, A.; Milics, G.; Nagy, J.; Harsányi, E.; Kovács, A.J.; Neményi, M. Application of spatio-temporal data in site-specific maize yield prediction with machine learning methods. Precis. Agric. 2021, 22, 1397–1415. [Google Scholar] [CrossRef]
- Yang, L.; Shami, A. On hyperparameter optimization of machine learning algorithms: Theory and practice. Neurocomputing 2020, 415, 295–316. [Google Scholar] [CrossRef]
- Elgeldawi, E.; Sayed, A.; Galal, A.R.; Zaki, A.M. Hyperparameter Tuning for Machine Learning Algorithms Used for Arabic Sentiment Analysis. Informatics 2021, 8, 79. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| P1 (C Days) | P2 (Days) | P5 (C Days) | G2 (Number) | G3 (mg day−1) | PHINT (C Days) | |
|---|---|---|---|---|---|---|
| Calibration range | 130–380 | 0–2 | 600–1100 | 400–1100 | 4–11.5 | 35–65 |
| Calibrated values | 320 | 0.8 | 968 | 794 | 8.5 | 51 |
| Feature Name | Type | Description | Levels |
|---|---|---|---|
| Environmental variables | |||
| Minimum temperature | Numeric | Daily minimum temperature | Baseline, +1, +2, +3, +4 |
| Maximum temperature | Numeric | Daily maximum temperature | Baseline, +1, +2, +3, +4 |
| CO2 | Numeric | CO2 concentration | Baseline (380 ppm), +20, +40,+60, +80 |
| Solar radiation | Numeric | Daily solar radiation (MJ/m2/d) | Baseline |
| Texture | Factor | Soil texture | Sandy, Silty Clay, Silty Clay Loam, and Clay Loam for Ismailia, Giza, Sakha, and Aswan sites, respectively |
| Available water content | Numeric | Average soil water holding capacity (mm of water/m of soil depth) | 65, 115, 145, and 120 for Ismailia, Giza, Sakha, and Aswan sites, respectively |
| Soil organic carbon | Numeric | Percent of soil organic carbon in 60 cm soil depth | 0.46, 0.98, 1.54, and 1.34 for Ismailia, Giza, Sakha, and Aswan sites, respectively |
| Management variables | |||
| Cultivar | Numeric | Calibrated radiation use efficiency | Baseline (3.7), 4.07, 4.44 |
| DOY | Numeric | Day of year | Weakly planting for 3 weeks before the recommended planting date and 3 weeks after the recommended planting date, plus the recommended planting date totaling 7 planting dates |
| Irrigation * | Numeric | Percent of available soil moisture content in the 30 cm soil depth | 90%, 70%, 50%, and 30% |
| Compost | Numeric | Level of compost application | 0, 5000 kg/ha and 10,000 kg/ha |
| Tillage | Factor | Tillage operation | No tillage and conventional tillage |
| Model | Hyperparameter | Space | Optimized Values for Grain Yield | Optimized Values for Evapotranspiration |
|---|---|---|---|---|
| Ridge regression | ‘alpha’ | ‘alpha’: (0,10000) | ‘alpha’: 51.603 | ‘alpha’: 3.326 |
| Lasso regression | ‘alpha’ | ‘alpha’: (0,10000) | ‘alpha’: 0.011 | ‘alpha’: 0.044 |
| K-nearest neighbors | {‘leaf_size’, ‘n_neighbors’} | {‘leaf_size’: (1,50), ‘n_neighbors’: (1,30)} | {‘leaf_size’: 47, ‘n_neighbors’: 22} | {‘leaf_size’: 11, ‘n_neighbors’: 20} |
| Random forest | {‘max_depth’, ‘min_samples_leaf’, ‘min_samples_split’, ‘n_estimators’} | {‘max_depth’: (5,20), ‘min_samples_leaf’: (1,5), ‘min_samples_split’: (2,6), ‘n_estimators’: (100,500)} | {‘max_depth’: 9.874, ‘min_samples_leaf’: 4.584, ‘min_samples_split’: 4.145, ‘n_estimators’: 485.329} | {‘max_depth’: 9.087, ‘min_samples_leaf’: 1.971, ‘min_samples_split’: 5.769, ‘n_estimators’: 265.092} |
| XGBoost | {‘colsample_bytree’, ‘gamma’, ‘max_depth’, ‘min_child_weight’, ‘n_estimators’, ‘reg_alpha’, ‘reg_lambda’} | {‘colsample_bytree’: (0.5,1), ‘gamma’: (1,9), ‘max_depth’: (3,18), ‘min_child_weight’: (0,10), ‘n_estimators’: (80,280), ‘reg_alpha’: (40,180), ‘reg_lambda’: (0,1)} | {‘colsample_bytree’: 0.803, ‘gamma’: 2.01, ‘max_depth’: 3.0, ‘min_child_weight’: 7.0, ‘n_estimators’: 14, ‘reg_alpha’: 53.0, ‘reg_lambda’: 0.432} | {‘colsample_bytree’: 0.562, ‘gamma’: 5.565, ‘max_depth’: 3.0, ‘min_child_weight’: 10.0, ‘n_estimators’: 63, ‘reg_alpha’: 162.0, ‘reg_lambda’: 0.816} |
| RMSE (kg ha−1) | R-RMSE (%) | R2 | RMSE | R-RMSE | R2 | |
|---|---|---|---|---|---|---|
| Grain Yield (kg ha−1) | Evapotranspiration (mm) | |||||
| Linear regression | 1467 | 9.76 | 0.77 | 64 | 7.23 | 0.79 |
| Ridge regression | 1468 | 9.77 | 0.77 | 64 | 7.24 | 0.80 |
| Lasso regression | 1467 | 9.76 | 0.77 | 64 | 7.23 | 0.79 |
| K-nearest neighbors | 1287 | 8.56 | 0.82 | 36 | 4.12 | 0.93 |
| Random forest | 1296 | 8.62 | 0.82 | 39 | 4.44 | 0.92 |
| XGBoost | 1285 | 8.55 | 0.82 | 37 | 4.27 | 0.93 |
| Super learner model | 1185 | 7.88 | 0.85 | 35 | 4.03 | 0.94 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Attia, A.; Govind, A.; Qureshi, A.S.; Feike, T.; Rizk, M.S.; Shabana, M.M.A.; Kheir, A.M.S. Coupling Process-Based Models and Machine Learning Algorithms for Predicting Yield and Evapotranspiration of Maize in Arid Environments. Water 2022, 14, 3647. https://doi.org/10.3390/w14223647
Attia A, Govind A, Qureshi AS, Feike T, Rizk MS, Shabana MMA, Kheir AMS. Coupling Process-Based Models and Machine Learning Algorithms for Predicting Yield and Evapotranspiration of Maize in Arid Environments. Water. 2022; 14(22):3647. https://doi.org/10.3390/w14223647
Chicago/Turabian StyleAttia, Ahmed, Ajit Govind, Asad Sarwar Qureshi, Til Feike, Mosa Sayed Rizk, Mahmoud M. A. Shabana, and Ahmed M.S. Kheir. 2022. "Coupling Process-Based Models and Machine Learning Algorithms for Predicting Yield and Evapotranspiration of Maize in Arid Environments" Water 14, no. 22: 3647. https://doi.org/10.3390/w14223647