
Flood or Non-Flooded: A Comparative Study of State-of-the-Art Models for Flood Image Classification Using the FloodNet Dataset with Uncertainty Offset Analysis
 , , , and
, , , and
Abstract
:1. Introduction
- We utilized a manual annotation process to categorize all images as either “flooded” or “non-flooded”.
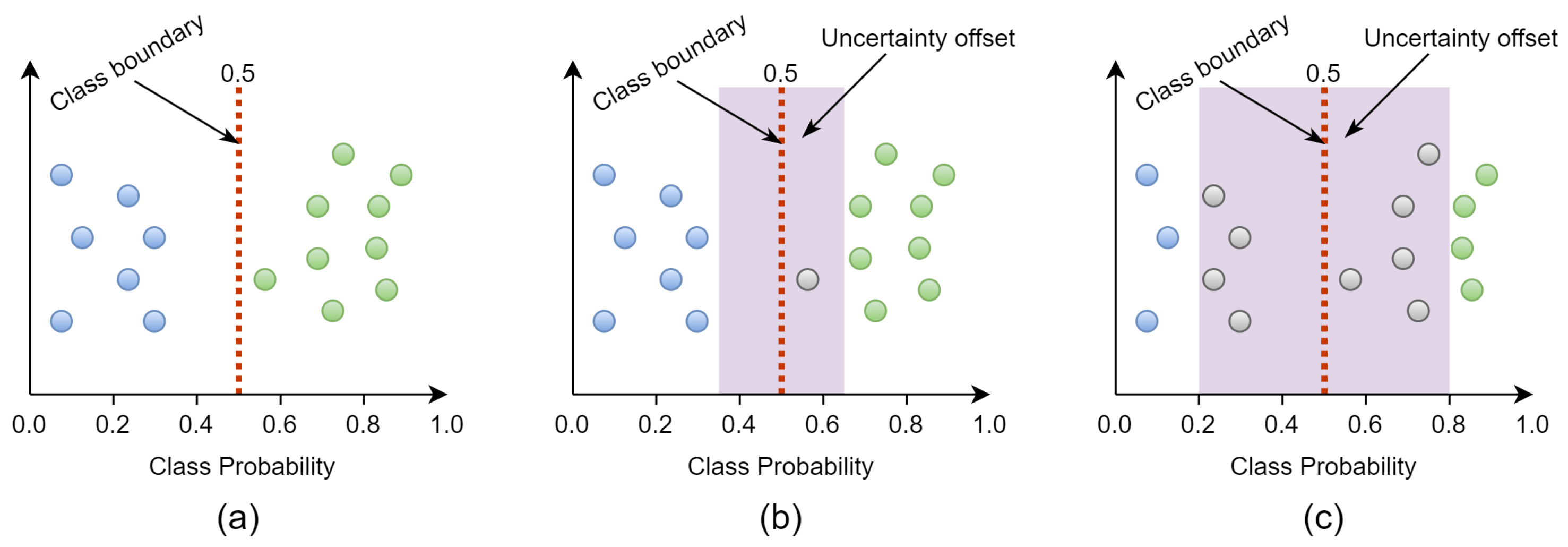
- We utilized a semi-supervised learning methodology that involved the implementation of uncertainty offsets to dynamically annotate the input images. This approach allowed us to analyze and compare the performance of different state-of-the-art models.
- We conducted a thorough evaluation of the performance of state-of-the-art networks through a series of experiments, utilizing a variety of metrics to assess their capabilities.
2. Related Works
2.1. Supervised Classification
2.2. Unsupervised and Semi-Supervised Approach
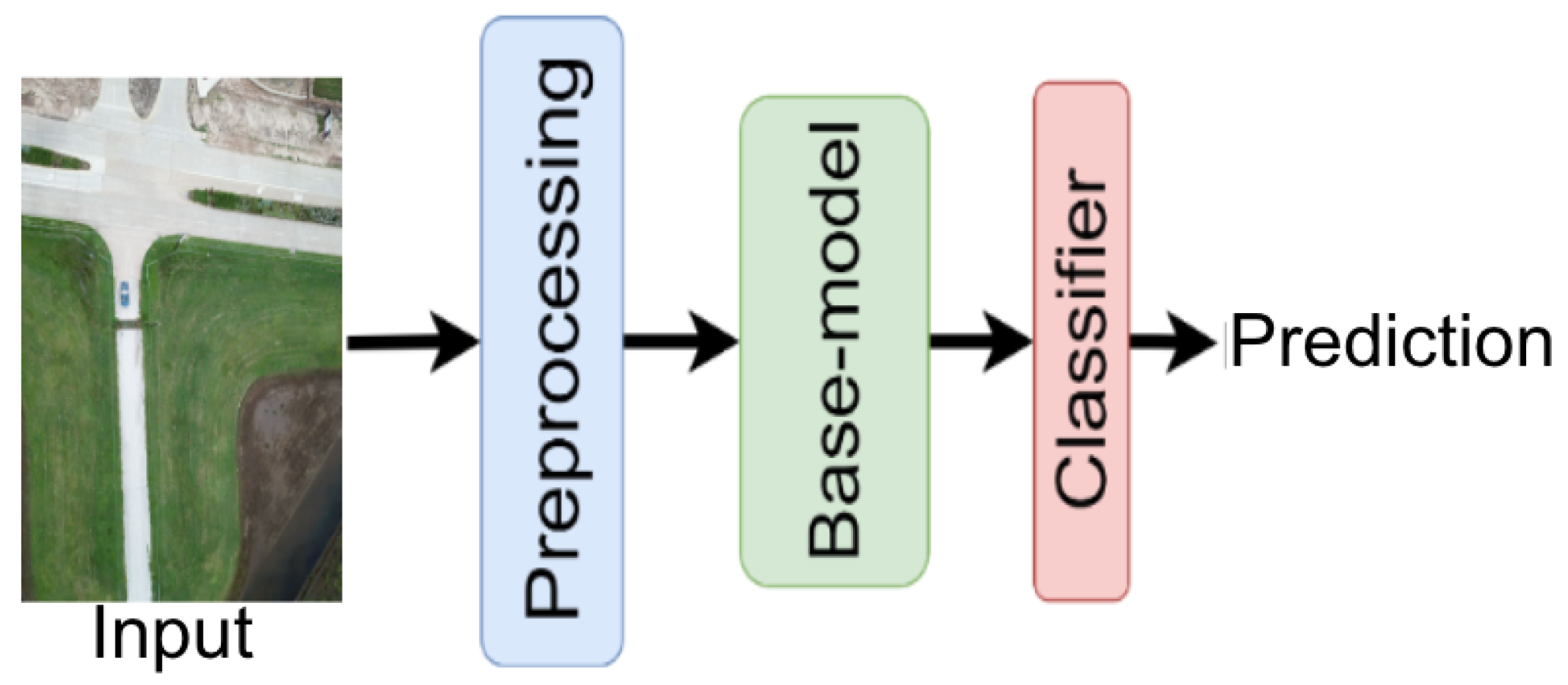
3. Base Models
3.1. ResNet-18
3.2. MobileNet
3.3. Visual Geometry Group-16 (VGG-16)
3.4. EfficientNet
3.5. Vision Transformer (ViT)
3.6. ConvNeXt
3.7. Regular Networks (RegNet)
4. Experiment
4.1. FloodNet Dataset
4.2. Dataset Preprocessing
4.3. Semi-Supervised Training
| Algorithm 1: Semi-supervised training procedure |
 |
4.4. Implementation Details
4.5. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Center, A. Natural Disaster Data Book (An Analytical Overview); Asian Disaster Reduction Center: Kobe, Japan, 2011. [Google Scholar]
- Amankwah, S.; Wang, G.; Gnyawali, K.; Hagan, D.; Sarfo, I.; Zhen, D.; Nooni, I.; Ullah, W.; Duan, Z. Landslide detection from bitemporal satellite imagery using attention-based deep neural networks. Landslides 2022, 19, 2459–2471. [Google Scholar] [CrossRef]
- Jang, Y.; Kang, H.; Kim, H.; Lee, I. Deep Learning-based Damage Assessment of Buildings after Natural Disasters Using Multi-Modal Data. Remote Sens. 2020, 12, 616. [Google Scholar]
- Kamilaris, A.; Ioannides, M. Landslide detection in satellite imagery using convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2018, 142, 1–15. [Google Scholar]
- Shen, Y.; Liu, X.; Chen, Y. Automatic detection of landslides from remote sensing images using deep convolutional neural networks. Int. J. Appl. Earth Obs. Geoinf. 2018, 66, 1–11. [Google Scholar]
- Li, Y.; Chen, Y. A convolutional neural network-based approach for segmenting damaged buildings and roads in overhead imagery captured after natural disasters. Remote Sens. 2019, 11, 60. [Google Scholar]
- Chen, J.; Liu, Y.; Guo, Y. Automatic building damage detection from post-disaster optical imagery using deep convolutional neural networks. Remote Sens. 2019, 11, 136. [Google Scholar]
- Ghasemian, N.; Wang, J.; Najafi, M. Building detection using a dense attention network from LiDAR and image data. Geomatica 2021, 75, 209–236. [Google Scholar] [CrossRef]
- Li, Y.; Chen, Y. A deep-learning-based approach for automatically detecting flooded areas in satellite imagery using convolutional neural networks. Remote Sens. 2018, 10, 568. [Google Scholar]
- Hedayatnia, B.; Yazdani, M.; Nguyen, M.; Block, J.; Altintas, I. Determining feature extractors for unsupervised learning on satellite images. In Proceedings of the 2016 IEEE International Conference On Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 2655–2663. [Google Scholar]
- Vaduva, C.; Costachioiu, T.; Patrascu, C.; Gavat, I.; Lazarescu, V.; Datcu, M. A latent analysis of earth surface dynamic evolution using change map time series. IEEE Trans. Geosci. Remote Sens. 2012, 51, 2105–2118. [Google Scholar] [CrossRef]
- Rahnemoonfar, M.; Chowdhury, T.; Sarkar, A.; Varshney, D.; Yari, M.; Murphy, R. Floodnet: A high resolution aerial imagery dataset for post-flood scene understanding. IEEE Access 2021, 9, 89644–89654. [Google Scholar] [CrossRef]
- Kadhim, M.; Abed, M. Convolutional neural network for satellite image classification. In Proceedings of the Asian Conference On Intelligent Information And Database Systems, Yogyakarta, Indonesia, 8–11 April 2019; pp. 165–178. [Google Scholar]
- Ghaffarian, S.; Kerle, N. Post-disaster recovery assessment using multi-temporal satellite images with a deep learning approach. In Proceedings of the 39th Annual EARSeL Conference & 43rd General Assembly, Salzburg, Austria, 1–4 July 2019. [Google Scholar]
- Zhu, X.; Liang, J.; Hauptmann, A. Msnet: A multilevel instance segmentation network for natural disaster damage assessment in aerial videos. In Proceedings of the IEEE/CVF Virtual Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 2023–2032. [Google Scholar]
- Gueguen, L.; Soille, P.; Pesaresi, M. Change detection based on information measure. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4503–4515. [Google Scholar] [CrossRef]
- Gueguen, L.; Hamid, R. Large-scale damage detection using satellite imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1321–1328. [Google Scholar]
- Algiriyage, N.; Prasanna, R.; Stock, K.; Doyle, E.E.H.; Johnston, D. Multi-source: Multimodal Data and Deep Learning for Disaster Response: A Systematic Review. Comput. Sci. 2022, 3, 181–189. [Google Scholar] [CrossRef] [PubMed]
- Abdi, G.; Esfandiari, M.; Jabari, S. A deep transfer learning-based damage assessment on post-event very high-resolution orthophotos. Geomatica 2022, 75, 237–250. [Google Scholar] [CrossRef]
- Nex, F.; Duarte, D.; Tonolo, F.G.; Kerle, N. Structural Building Damage Detection with Deep Learning: Assessment of a State-of-the-Art CNN in Operational Conditions. Remote Sens. 2019, 11, 2765. [Google Scholar] [CrossRef] [Green Version]
- Tang, X.; Tu, Z.; Wang, Y.; Liu, M.; Li, D.; Fan, X. Automatic Detection of Coseismic Landslides Using a New Transformer Method. Remote Sens. 2022, 14, 2884. [Google Scholar] [CrossRef]
- Wu, Q.; Feng, D.; Cao, C.; Zeng, X.; Feng, Z.; Wu, J.; Huang, Z. Improved Mask R-CNN for Aircraft Detection in Remote Sensing Images. Sensors 2021, 21, 2618. [Google Scholar] [CrossRef] [PubMed]
- Nemni, E.; Bullock, J.; Belabbes, S.; Bromley, L. Fully Convolutional Neural Network for Rapid Flood Segmentation in Synthetic Aperture Radar Imagery. Remote Sens. 2020, 12, 2532. [Google Scholar] [CrossRef]
- Ayala, C.; Sesma, R.; Aranda, C.; Galar, M. A Deep Learning Approach to an Enhanced Building Footprint and Road Detection in High-Resolution Satellite Imagery. Remote Sens. 2021, 13, 3135. [Google Scholar] [CrossRef]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A deep neural network architecture for real-time semantic segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Chen, L.; Zhu, Y.; Papreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference On Computer Vision And Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chowdhury, T.; Rahnemoonfar, M. Self Attention Based Semantic Segmentation on a Natural Disaster Dataset. In Proceedings of the 2021 IEEE International Conference On Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 2798–2802. [Google Scholar]
- Rudner, T.; Rußwurm, M.; Fil, J.; Pelich, R.; Bischke, B.; Kopačková, V.; Biliński, P. Multi3Net: Segmenting flooded buildings via fusion of multiresolution, multisensor, and multitemporal satellite imagery. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 702–709. [Google Scholar]
- Gupta, R.; Shah, M. Rescuenet: Joint building segmentation and damage assessment from satellite imagery. In Proceedings of the 2020 25th International Conference On Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 4405–4411. [Google Scholar]
- Rahnemoonfar, M.; Murphy, R.; Miquel, M.; Dobbs, D.; Adams, A. Flooded area detection from UAV images based on densely connected recurrent neural networks. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience And Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 1788–1791. [Google Scholar]
- Xu, J.; Lu, W.; Li, Z.; Khaitan, P.; Zaytseva, V. Building damage detection in satellite imagery using convolutional neural networks. arXiv 2019, arXiv:1910.06444. [Google Scholar]
- Chen, Z.; Wagner, M.; Das, J.; Doe, R.; Cerveny, R. Data-driven approaches for tornado damage estimation with unpiloted aerial systems. Remote Sens. 2021, 13, 1669. [Google Scholar] [CrossRef]
- Pi, Y.; Nath, N.; Behzadan, A. Convolutional neural networks for object detection in aerial imagery for disaster response and recovery. Adv. Eng. Inform. 2020, 43, 101009. [Google Scholar] [CrossRef]
- Cheng, C.; Behzadan, A.; Noshadravan, A. Deep learning for post-hurricane aerial damage assessment of buildings. Comput.-Aided Civ. Infrastruct. Eng. 2021, 36, 695–710. [Google Scholar] [CrossRef]
- Markou, M.; Singh, S. Novelty detection: A review—Part 1: Statistical approaches. Signal Process. 2003, 83, 2481–2497. [Google Scholar] [CrossRef]
- Liu, Z.; Mercier, G.; Dezert, J.; Pan, Q. Change detection in heterogeneous remote sensing images based on multidimensional evidential reasoning. IEEE Geosci. Remote Sens. Lett. 2013, 11, 168–172. [Google Scholar] [CrossRef]
- Li, F.; Runger, G.; Tuv, E. Supervised learning for change-point detection. Int. J. Prod. Res. 2006, 44, 2853–2868. [Google Scholar] [CrossRef]
- Li, Y.; Hu, W.; Li, H.; Dong, H.; Zhang, B.; Tian, Q. Aligning discriminative and representative features: An unsupervised domain adaptation method for building damage assessment. IEEE Trans. Image Process. 2020, 29, 6110–6122. [Google Scholar] [CrossRef]
- Daniel, T.; Kurutach, T.; Tamar, A. Deep variational semi-supervised novelty detection. arXiv 2019, arXiv:1911.04971. [Google Scholar]
- Vijayanarasimhan, S.; Grauman, K. Large-scale live active learning: Training object detectors with crawled data and crowds. Int. J. Comput. Vis. 2014, 108, 97–114. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Peng, Y.; Tu, Z.W. Deep learning for remote sensing data: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2016, 4, 6–36. [Google Scholar]
- Volpi, M.; Alparone, L. Deep learning for remote sensing data classification: A review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1266–1282. [Google Scholar]
- Sandler, M.; Howard, A.G.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11966–11976. [Google Scholar]
- Radosavovic, I.; Kosaraju, R.; Girshick, R.B.; He, K.; Dollár, P. Designing Network Design Spaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 10425–10433. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Uncertainty Offset | Loss | Accuracy | F1 Score | Precision | Recall | ROC-AUC |
|---|---|---|---|---|---|---|
| 0 | 0.069 | 98.684 | 94.828 | 91.667 | 100 | 98.875 |
| 0.1 | 0.074 | 98.246 | 93.103 | 100 | 100 | 98.875 |
| 0.2 | 0.056 | 98.684 | 94.915 | 91.667 | 100 | 99.25 |
| 0.3 | 0.066 | 98.246 | 93.103 | 91.837 | 100 | 98.875 |
| 0.4 | 0.075 | 98.684 | 94.915 | 92.105 | 100 | 99.25 |
| Base-Model | Loss | Accuracy | F1 Score | Precision | Recall | ROC-AUC |
|---|---|---|---|---|---|---|
| ResNet-18 | 0.056 | 98.684 | 94.915 | 91.667 | 100 | 99.254 |
| VGG-16 | 0.096 | 97.368 | 90.214 | 100 | 100 | 98.251 |
| ShuffleNet V2 | 0.186 | 94.737 | 77.358 | 82.342 | 91.071 | 90.411 |
| MobileNet V2 | 0.185 | 95.175 | 80.645 | 86.667 | 100 | 92.554 |
| EfficientNet-B0 | 0.108 | 95.833 | 84.553 | 95.122 | 94.643 | 94.571 |
| EfficientNet-B3 | 0.099 | 96.93 | 87.931 | 89.13 | 96.429 | 95.821 |
| RegNet-8 | 0.099 | 96.711 | 87.179 | 85.185 | 100 | 96.625 |
| RegNet-16 | 0.115 | 97.368 | 90.323 | 88.889 | 100 | 98.523 |
| Vision Transformer-16 | 0.103 | 96.931 | 88.333 | 88.679 | 94.643 | 95.946 |
| Vision Transformer-32 | 0.137 | 95.175 | 82.258 | 86.111 | 100 | 93.411 |
| ConvNeXt-smal | 0.200 | 93.642 | 77.863 | 77.778 | 100 | 92.536 |
| ConvNeXt-base | 0.204 | 92.763 | 73.282 | 100 | 98.214 | 94.107 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jackson, J.; Yussif, S.B.; Patamia, R.A.; Sarpong, K.; Qin, Z. Flood or Non-Flooded: A Comparative Study of State-of-the-Art Models for Flood Image Classification Using the FloodNet Dataset with Uncertainty Offset Analysis. Water 2023, 15, 875. https://doi.org/10.3390/w15050875
Jackson J, Yussif SB, Patamia RA, Sarpong K, Qin Z. Flood or Non-Flooded: A Comparative Study of State-of-the-Art Models for Flood Image Classification Using the FloodNet Dataset with Uncertainty Offset Analysis. Water. 2023; 15(5):875. https://doi.org/10.3390/w15050875
Chicago/Turabian StyleJackson, Jehoiada, Sophyani Banaamwini Yussif, Rutherford Agbeshi Patamia, Kwabena Sarpong, and Zhiguang Qin. 2023. "Flood or Non-Flooded: A Comparative Study of State-of-the-Art Models for Flood Image Classification Using the FloodNet Dataset with Uncertainty Offset Analysis" Water 15, no. 5: 875. https://doi.org/10.3390/w15050875