
Water Pipeline Leak Detection Based on a Pseudo-Siamese Convolutional Neural Network: Integrating Handcrafted Features and Deep Representations
 ,
,
Abstract
:
1. Introduction
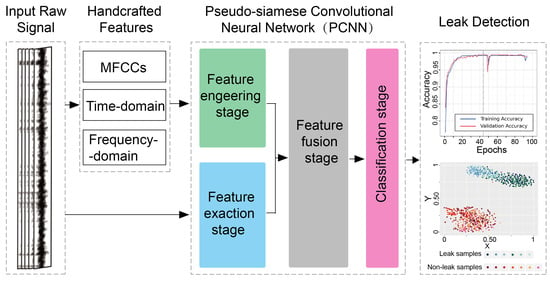
- The present study proposes an effective method for leak detection using ground acoustic signals collected by listening devices, as opposed to methods that use signals from the pipeline wall. This method is based on the fusion of handcrafted features and deep representations, providing a novel approach to leak detection using ground acoustic signals.
- This work innovatively proposes a fusion method that combines handcrafted features with deep representations using a PCNN structure. The effectiveness of this fusion method is demonstrated. The PCNN, integrating handcrafted features and deep representations, outperforms traditional classifiers that rely solely on CNN or handcrafted features. Furthermore, the study extends the application of PCNN and improves the structure of PCNN for leak detection tasks, which is a novel application of PCNN.
- The researchers evaluate the applicability of MFCCs’ features to leak detection in WDS. By combining MFCCs’ features with TFD features, the representation ability of handcrafted features is further investigated.
- Additionally, the work provides insights into the operation and decision-making process of deep learning for leak detection tasks, contributing to the wider understanding of the application of deep learning to pipeline leak signal recognition.
2. Methods
2.1. Convolutional Neural Network
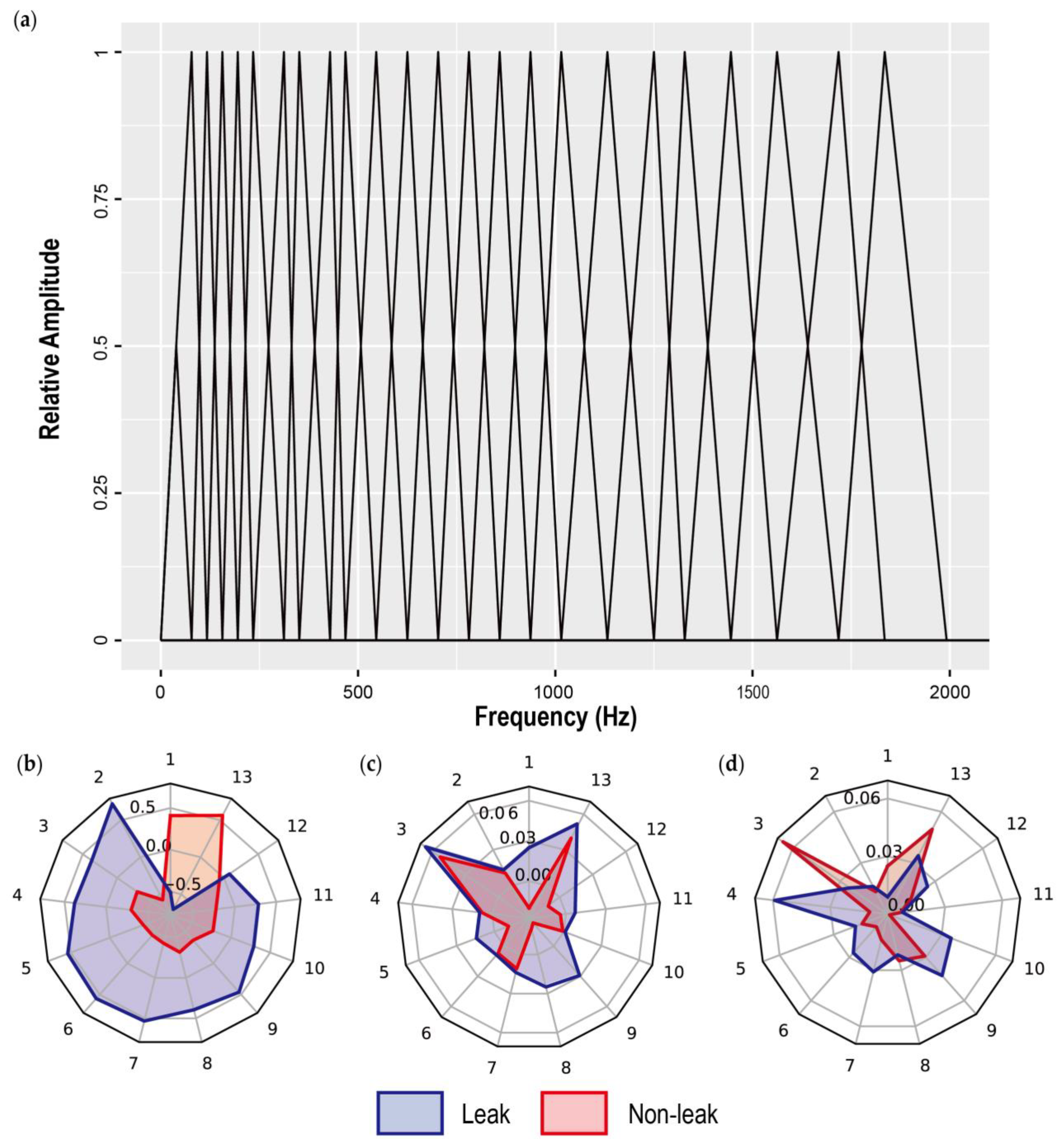
2.2. The Selected Handcrafted Features
2.2.1. MFCCs’ Features
2.2.2. TFD Features
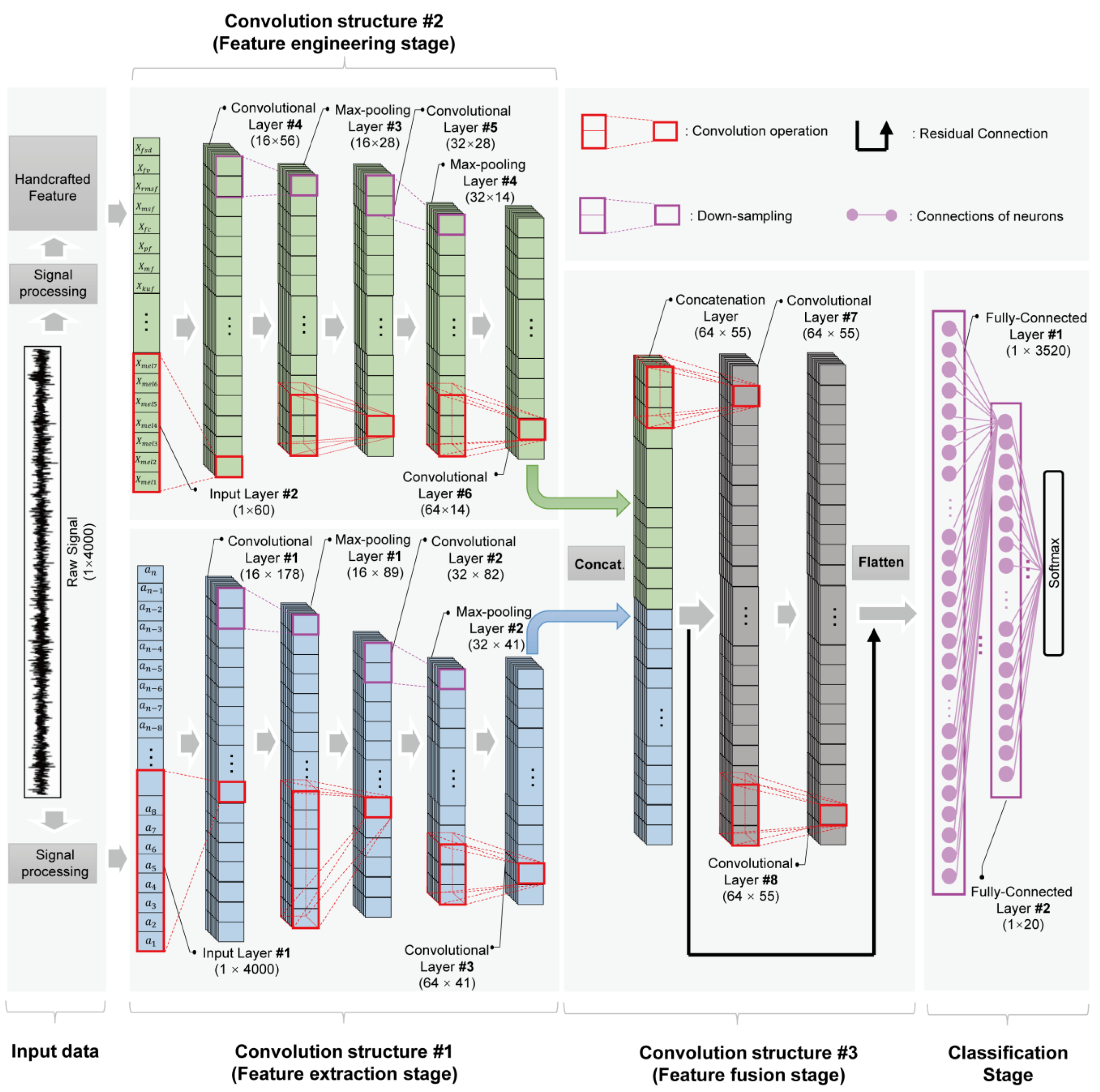
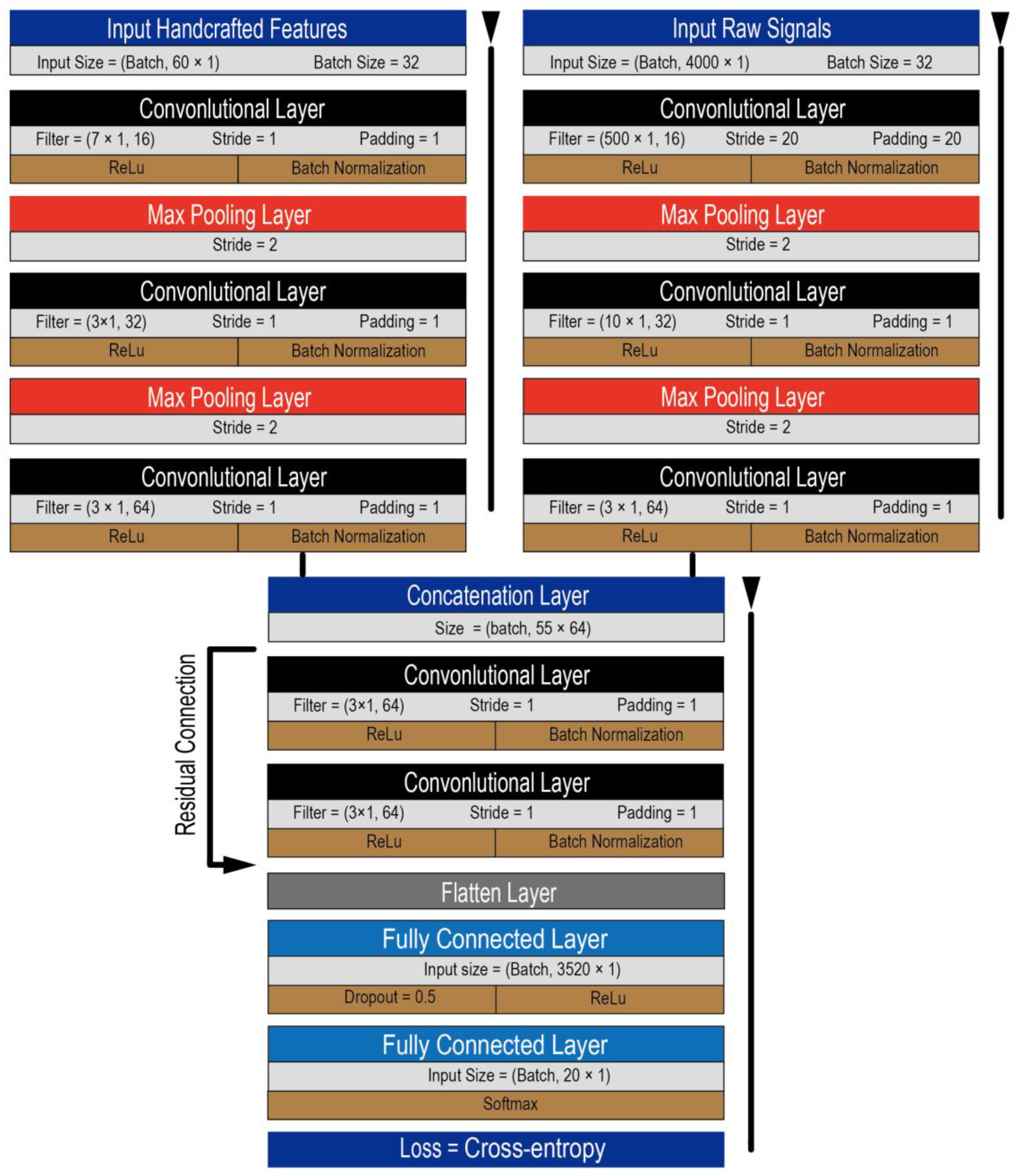
2.3. Pseudo-Siamese Convolutional Neural Network for Feature Fusion
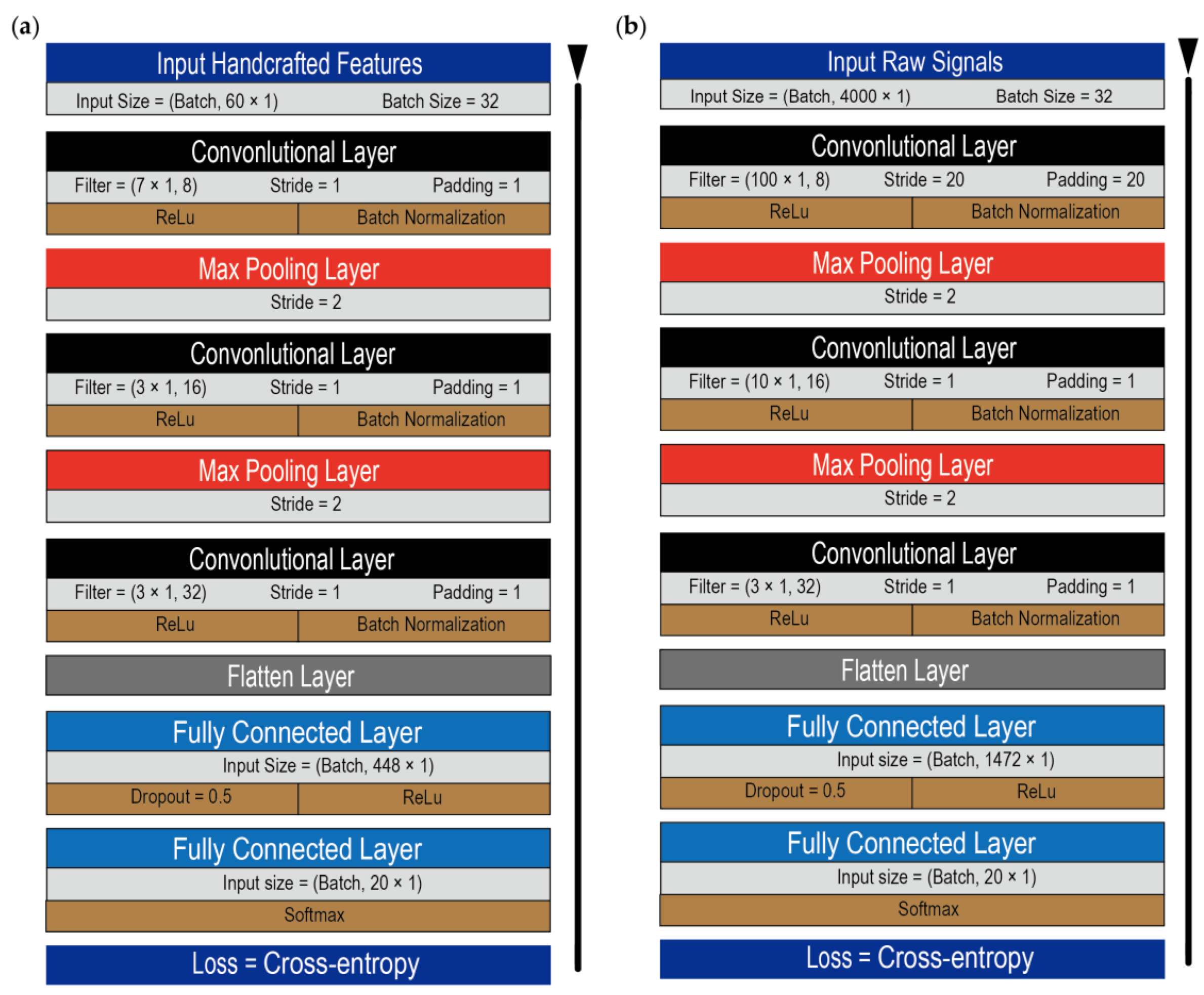
2.3.1. Feature Engineering Stage
2.3.2. Feature Extraction Stage
2.3.3. Feature Fusion Stage and Classification Stage
2.3.4. Classification Stage and Loss Function
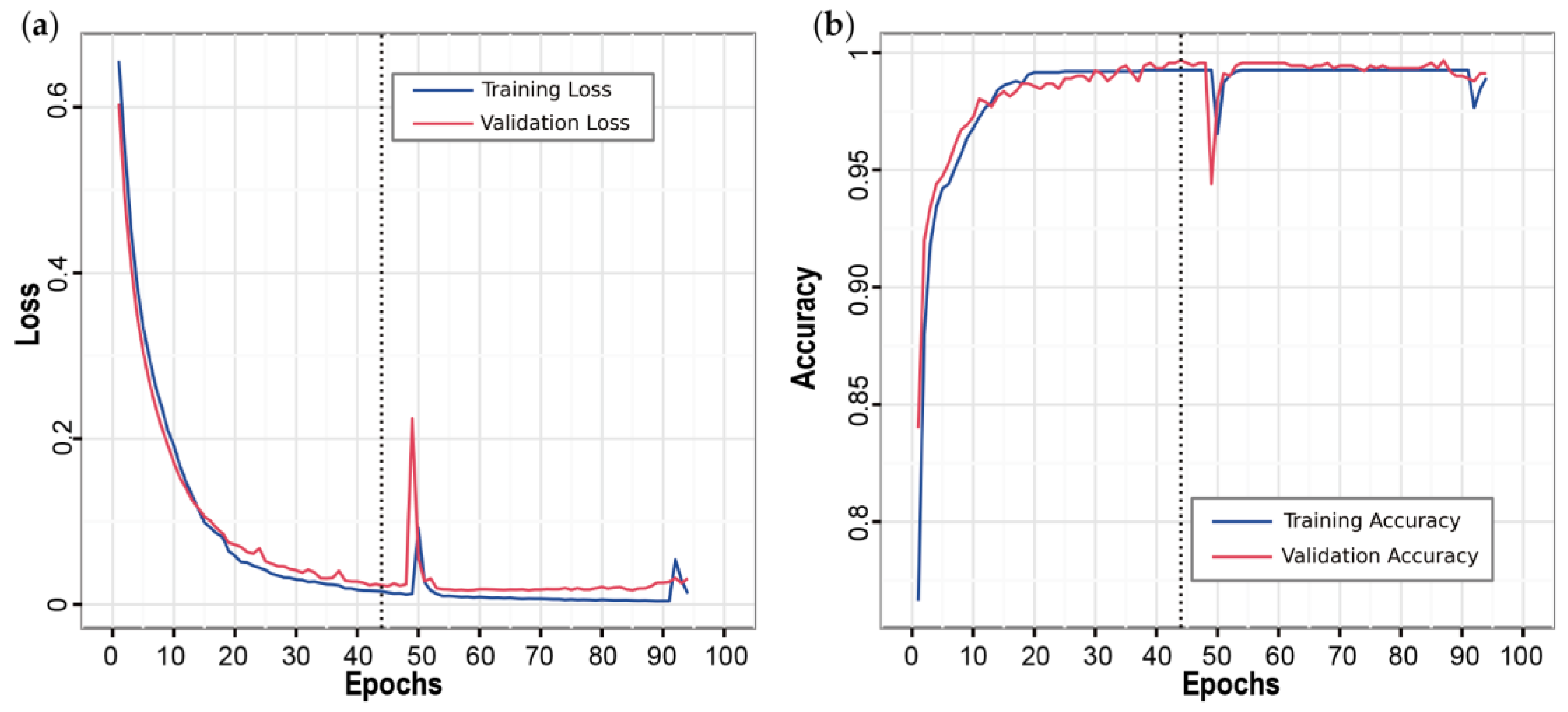
2.3.5. Network Training
2.4. Experiments Settings
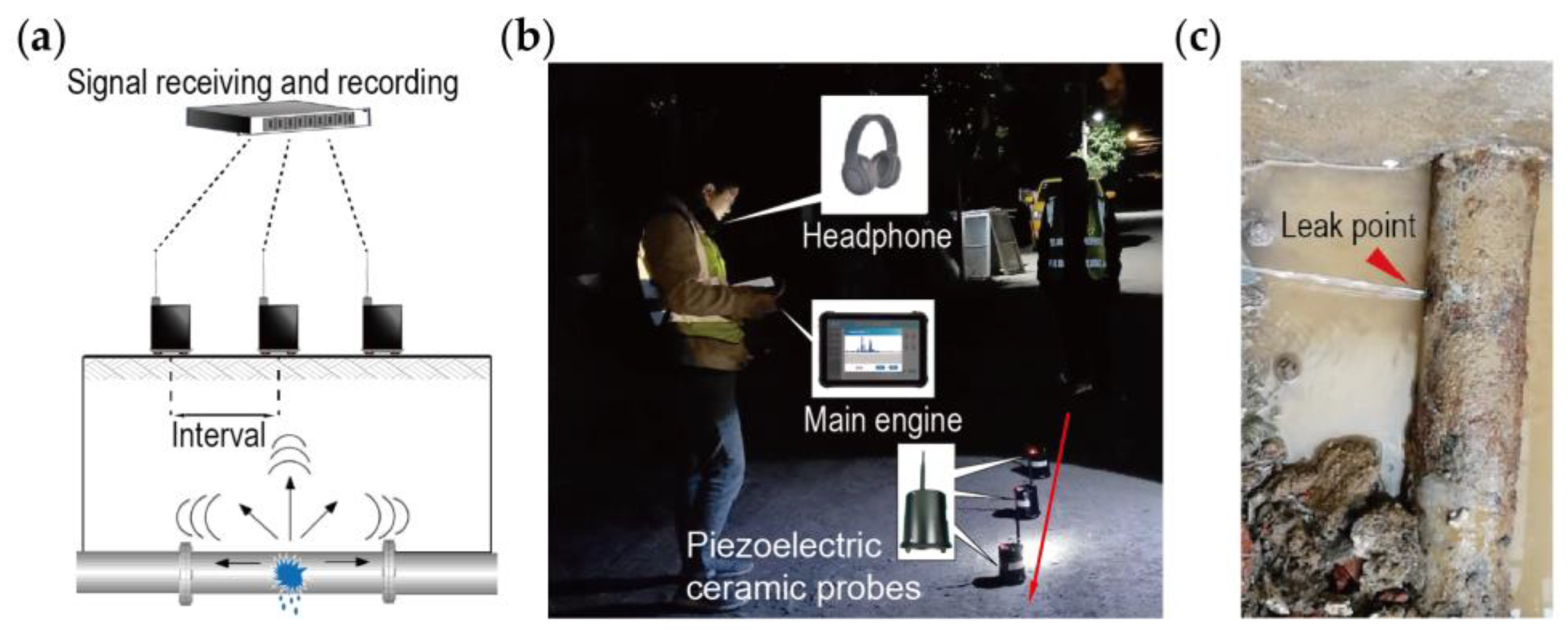
2.4.1. Case Study and Data Set
2.4.2. Evaluation Metrics
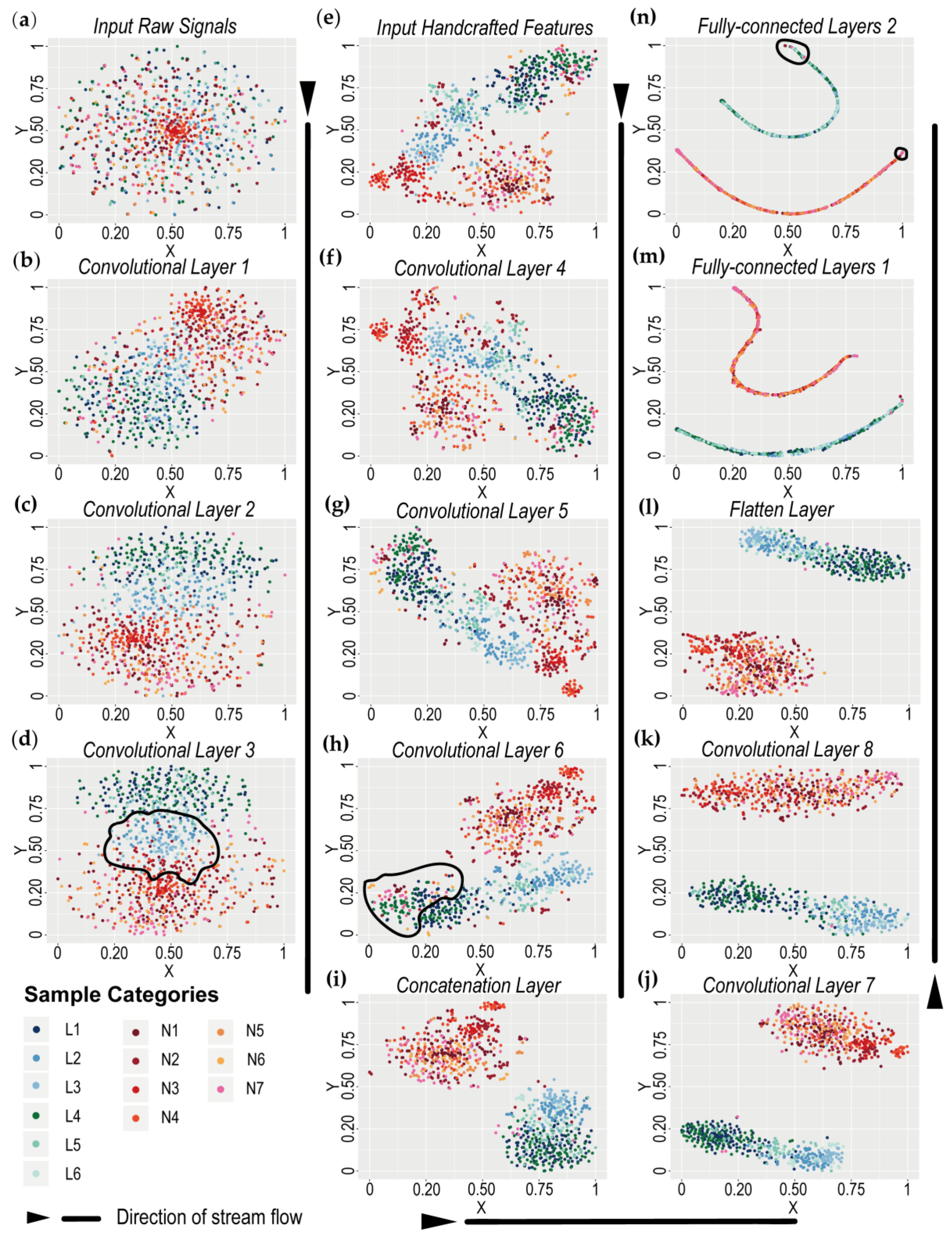
2.5. Model Visualization and Interpretation Method
2.5.1. T-SNE for Model Visualization
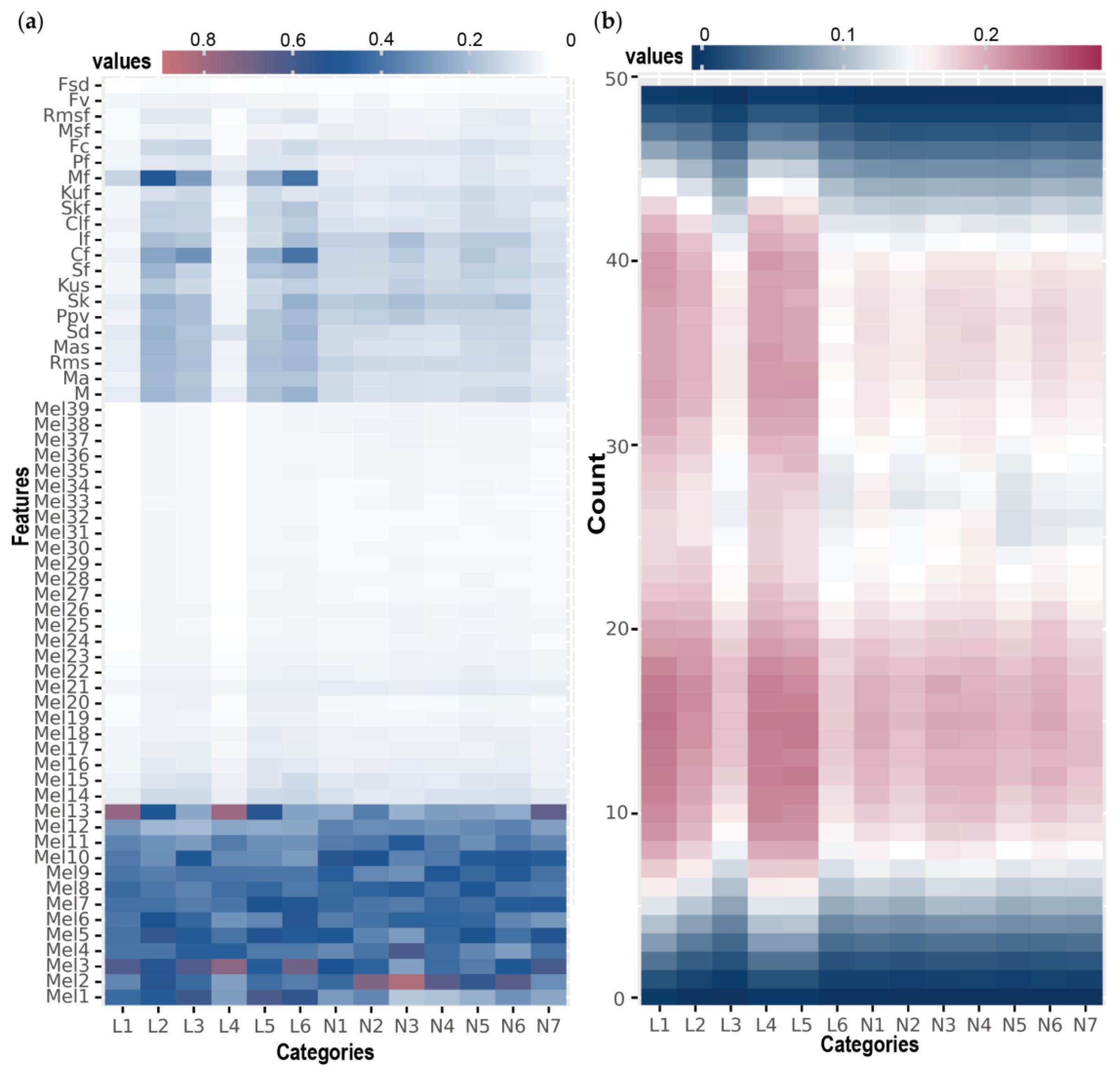
2.5.2. Saliency Map Based on Vanilla Gradient
3. Results and Discussion
3.1. Architectures and Hyperparameters Optimization
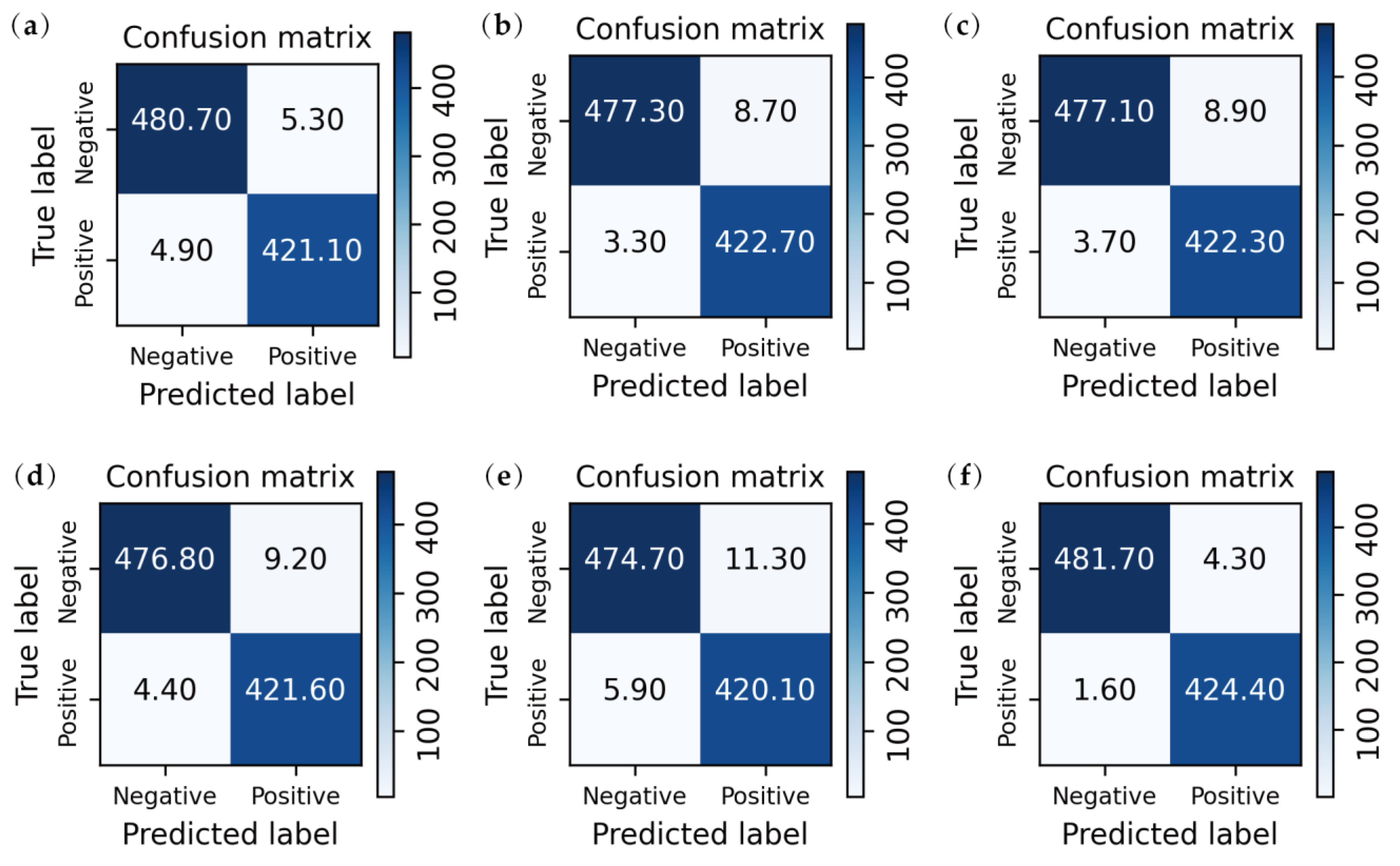
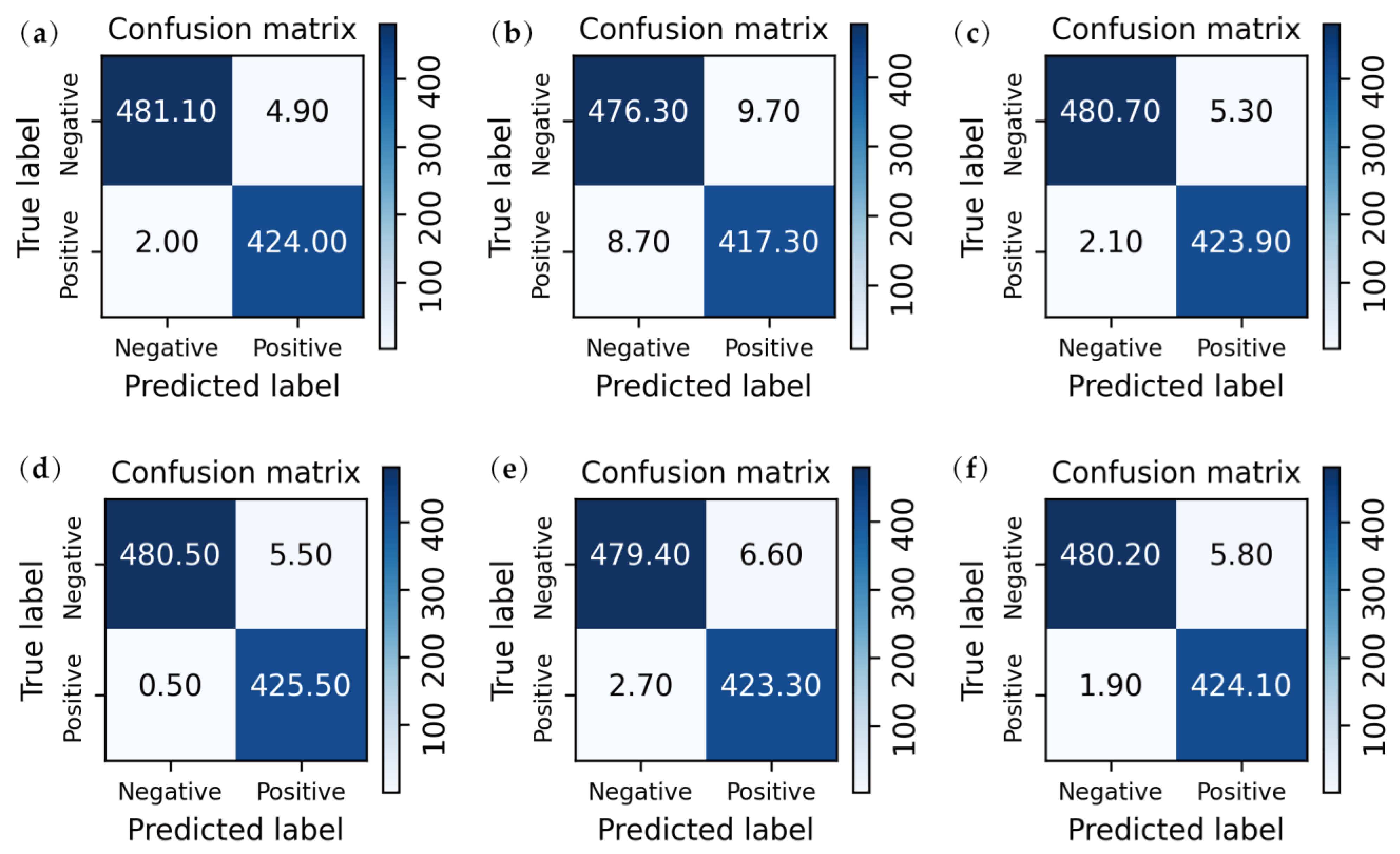
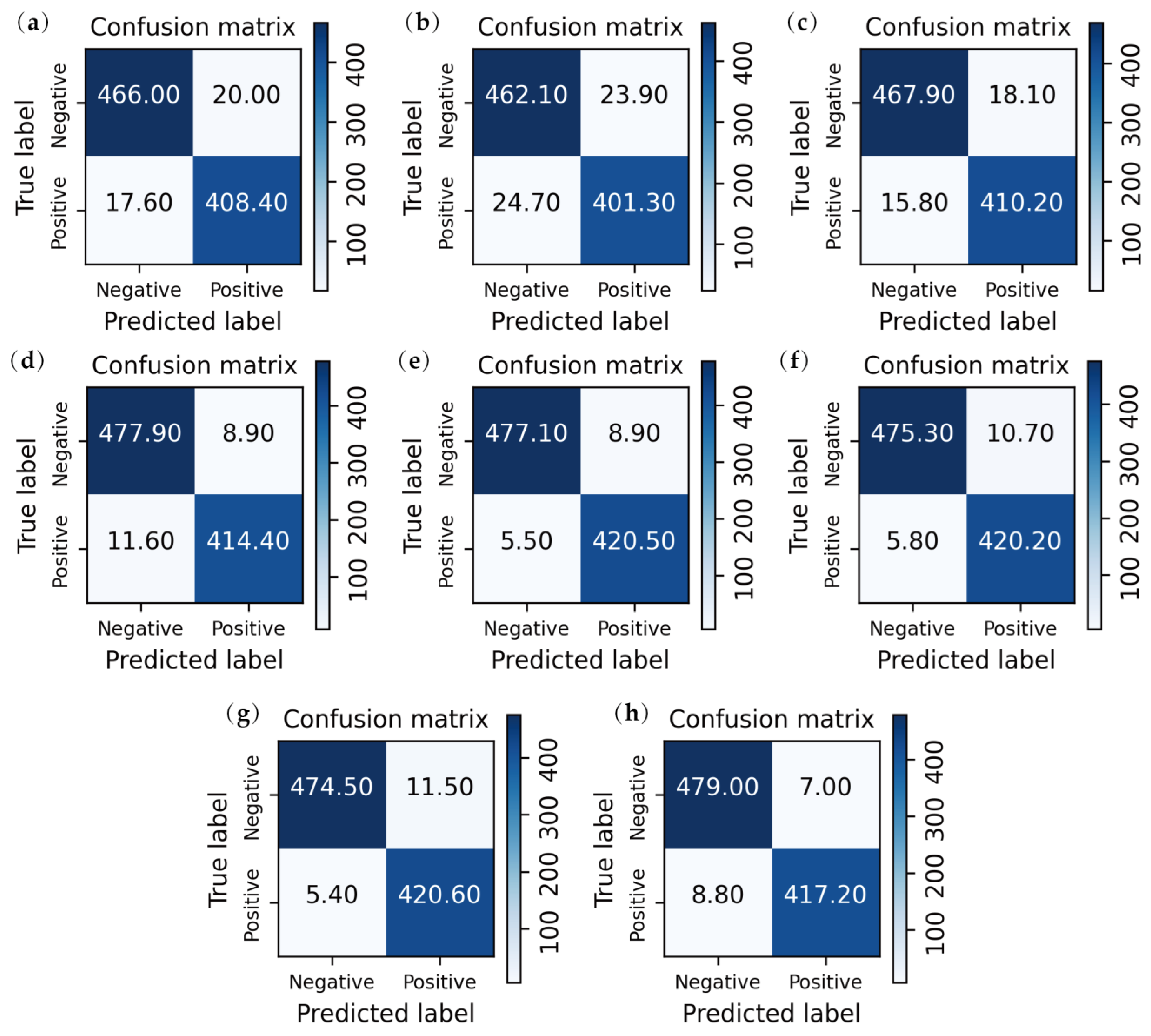
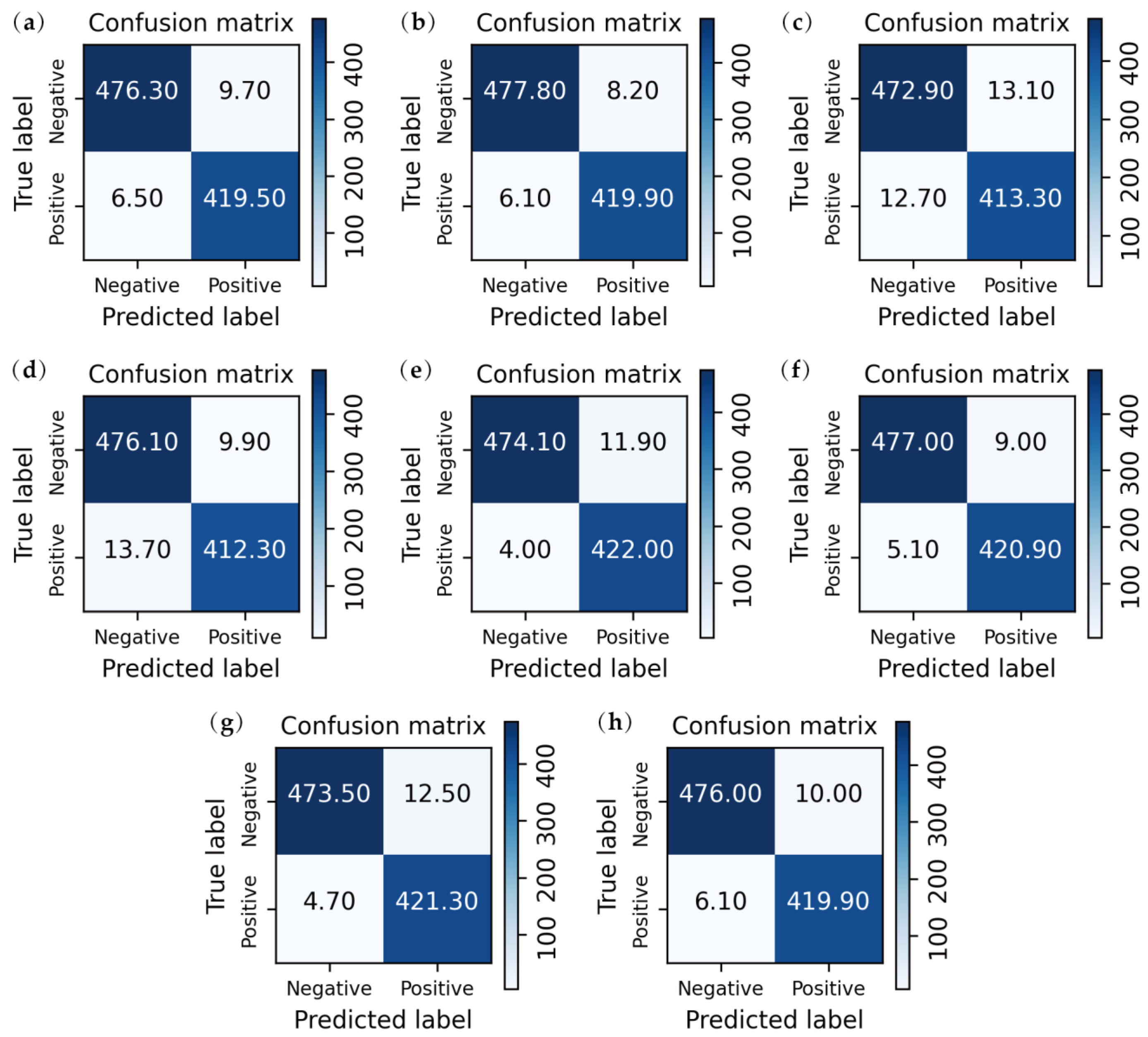
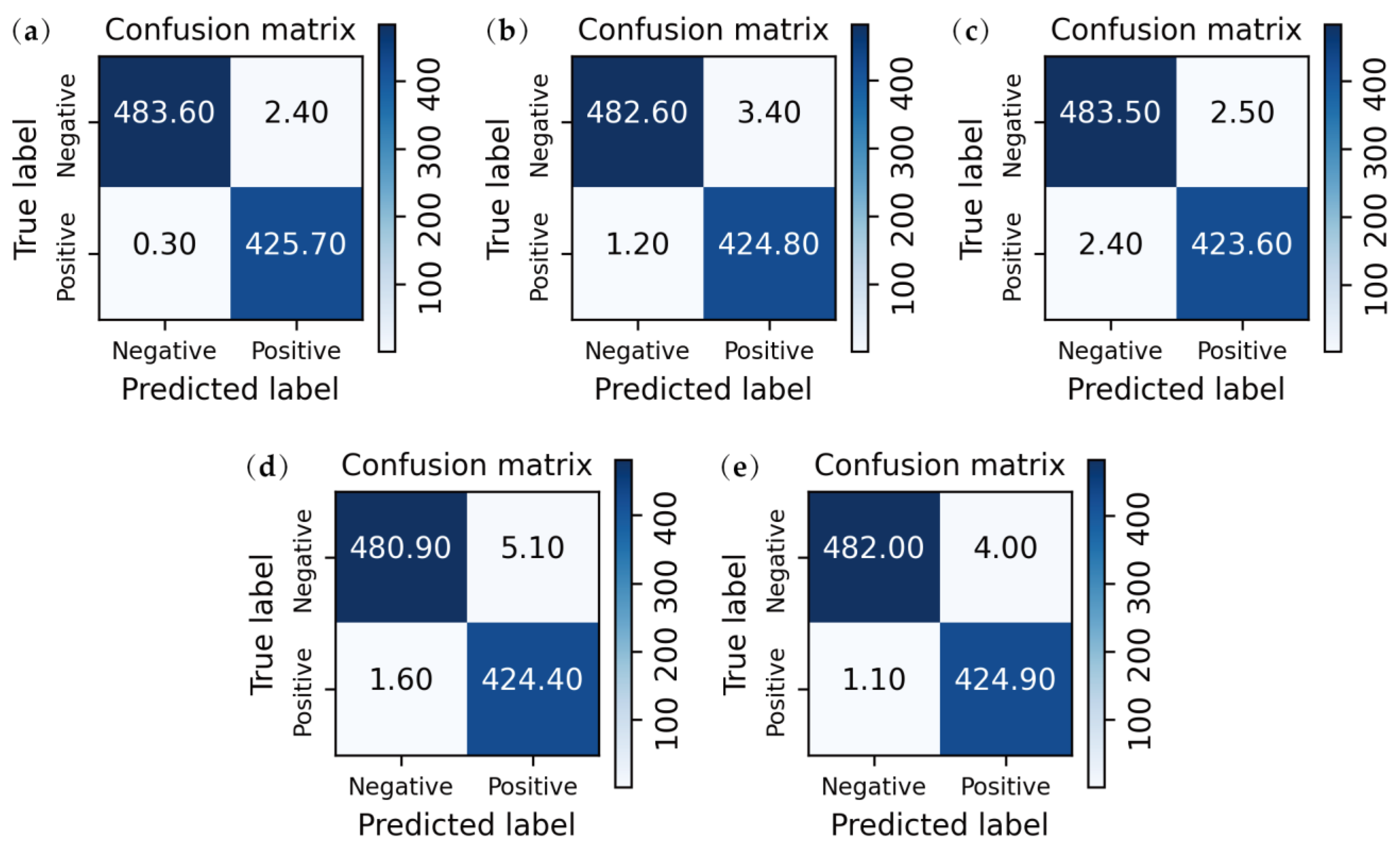
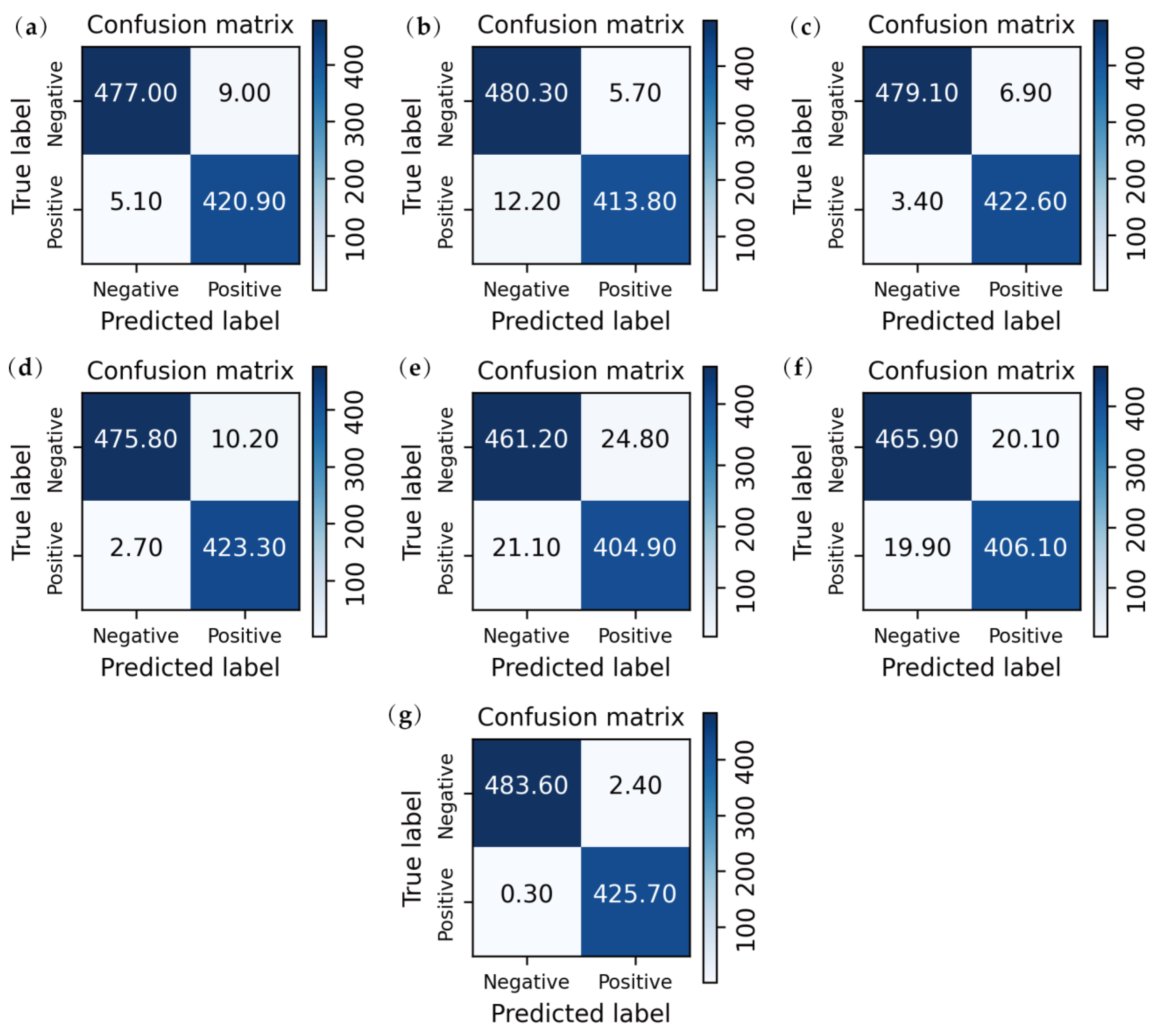
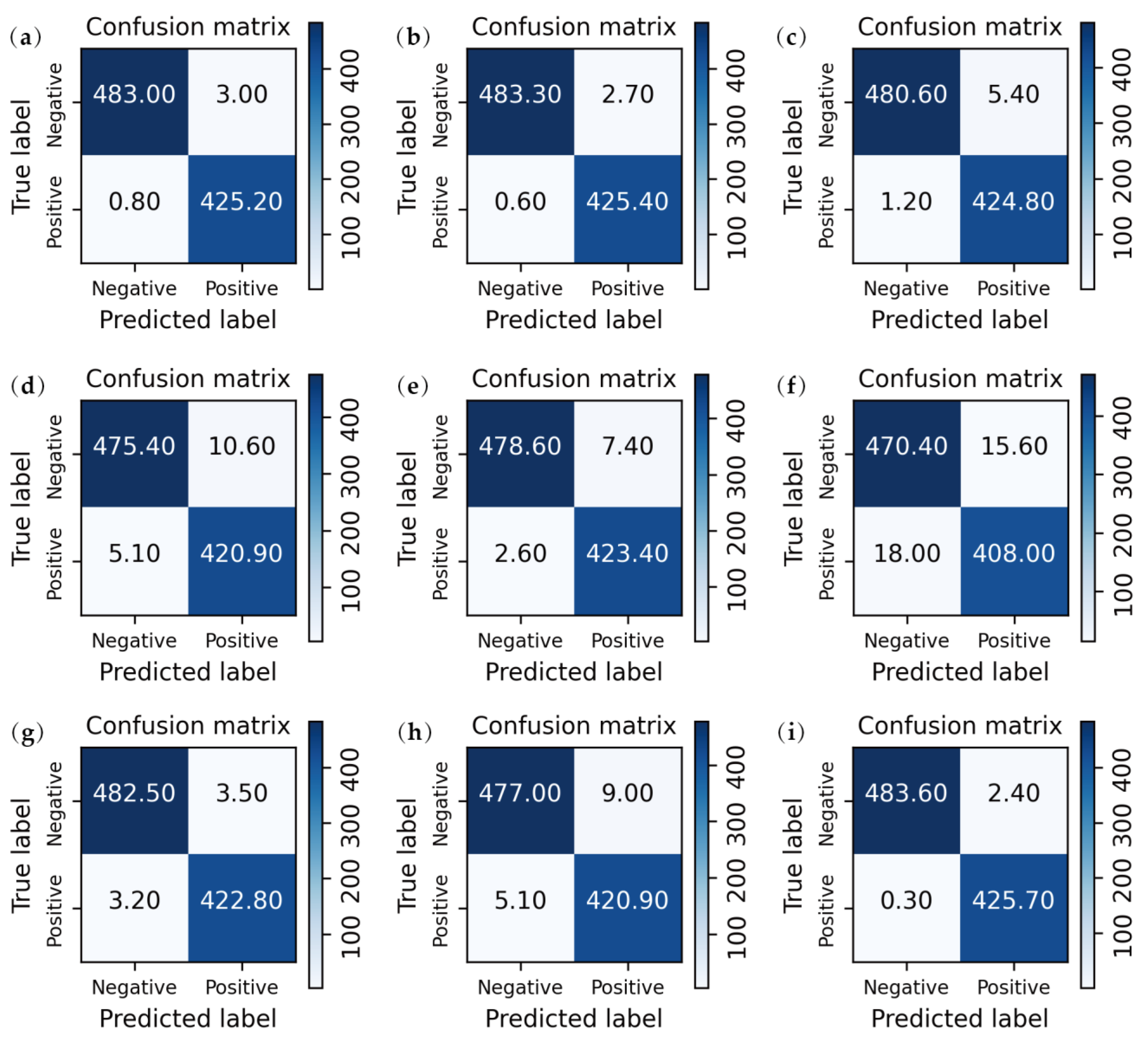
3.2. Performance Comparison
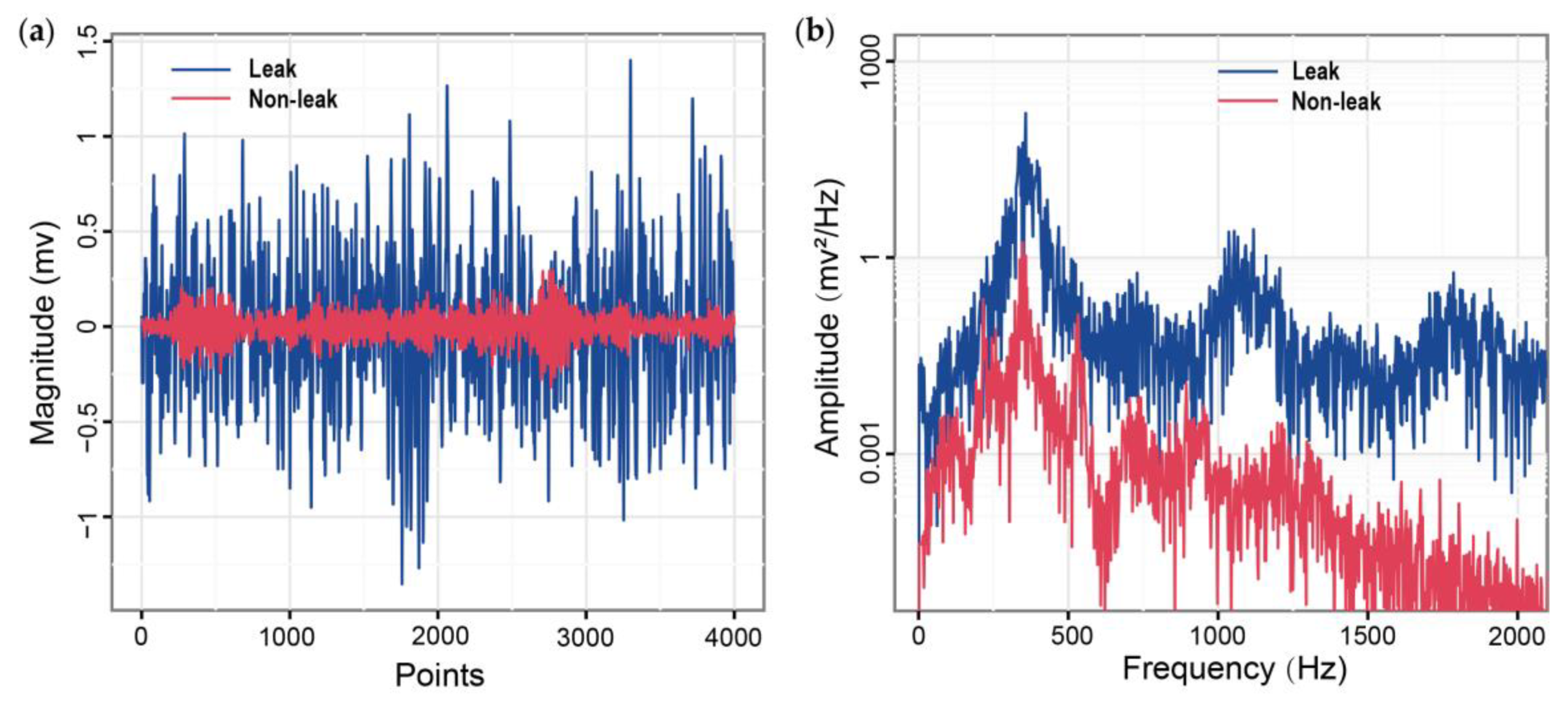
3.3. Quantitative Analysis
3.4. Model Visualization
3.5. Interpretability Analysis
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mekonnen, M.M.; Hoekstra, A.Y. Four billion people facing severe water scarcity. Sci. Adv. 2016, 2, e1500323. [Google Scholar]
- Lai, W.W.L.; Chang, R.K.W.; Sham, J.F.C.; Pang, K. Perturbation mapping of water leak in buried water pipes via laboratory validation experiments with high-frequency ground penetrating radar (GPR). Tunn. Undergr. Space Technol. 2016, 52, 157–167. [Google Scholar]
- Fahmy, M.; Moselhi, O. Automated Detection and Location of Leaks in Water Mains Using Infrared Photography. J. Perform. Constr. Facil. 2010, 24, 242–248. [Google Scholar]
- Hu, Z.; Chen, B.; Chen, W.; Tan, D.; Shen, D. Review of model-based and data-driven approaches for leak detection and location in water distribution systems. Water Supply 2021, 21, 3282–3306. [Google Scholar]
- Li, R.; Huang, H.; Xin, K.; Tao, T. A review of methods for burst/leakage detection and location in water distribution systems. Water Supply 2015, 15, 429–441. [Google Scholar]
- Fan, H.; Tariq, S.; Zayed, T. Acoustic leak detection approaches for water pipelines. Autom. Constr. 2022, 138, 104226. [Google Scholar]
- Hamilton, S.; Charalambous, B. Leak Detection: Technology and Implementation; IWA Publishing: London, UK, 2013. [Google Scholar] [CrossRef]
- Butterfield, J.D.; Collins, R.P.; Beck, S.B. Influence of pipe material on the transmission of vibroacoustic leak signals in real complex water distribution systems: Case study. J. Pipeline Syst. Eng. 2018, 9, 05018003. [Google Scholar]
- Xu, Y.; He, Q.; Liu, C.; Huangfu, X. Are micro-or nanoplastics leached from drinking water distribution systems? Environ. Sci. Technol. 2019, 53, 9339–9340. [Google Scholar] [PubMed] [Green Version]
- Butterfield, J.D.; Meruane, V.; Collins, R.P.; Meyers, G.; Beck, S.B. Prediction of leak flow rate in plastic water distribution pipes using vibro-acoustic measurements. Struct. Health Monit. 2018, 17, 959–970. [Google Scholar]
- Quy, T.B.; Muhammad, S.; Kim, J. A Reliable Acoustic EMISSION Based Technique for the Detection of a Small Leak in a Pipeline System. Energies 2019, 12, 1472. [Google Scholar]
- Sato, T.; Mita, A. Leak detection using the pattern of sound signals in water supply systems. In Proceedings of the Sensors and Smart Structures Technologies for Civil, Mechanical, and Aerospace Systems 2007, San Diego, CA, USA, 19–22 March 2007; Volume 6529, pp. 816–824. [Google Scholar]
- Stoianov, I.; Nachman, L.; Madden, S.; Tokmouline, T. Pipeneta wireless sensor network for pipeline monitoring. In Proceedings of the 6th International Conference on Information Processing in Sensor Networks, Cambridge, MA, USA, 22–24 April 2007; pp. 264–273. [Google Scholar]
- Tariq, S.; Bakhtawar, B.; Zayed, T. Data-driven application of MEMS-based accelerometers for leak detection in water distribution networks. Sci. Total Environ. 2022, 809, 151110. [Google Scholar]
- Terao, Y.; Mita, A. Robust water leakage detection approach using the sound signals and pattern recognition. In Proceedings of the Sensors and Smart Structures Technologies for Civil, Mechanical, and Aerospace Systems, San Diego, CA, USA, 10–13 March 2008; Volume 6932, pp. 697–705. [Google Scholar]
- Li, S.; Song, Y.; Zhou, G. Leak detection of water distribution pipeline subject to failure of socket joint based on acoustic emission and pattern recognition. Measurement 2018, 115, 39–44. [Google Scholar]
- Lim, J. Underground pipeline leak detection using acoustic emission and crest factor technique. In Advances in Acoustic Emission Technology; Springer: New York, NY, USA, 2015; pp. 445–450. [Google Scholar]
- Kang, J.; Park, Y.; Lee, J.; Wang, S.; Eom, D. Novel Leakage Detection by Ensemble CNN-SVM and Graph-Based Localization in Water Distribution Systems. IEEE Trans. Ind. Electron. 2018, 65, 4279–4289. [Google Scholar]
- Da Cruz, R.P.; Da Silva, F.V.; Fileti, A.M.F. Machine learning and acoustic method applied to leak detection and location in low-pressure gas pipelines. Clean Technol. Environ. Policy 2020, 22, 627–638. [Google Scholar]
- Imah, E.M.; Afif, F.A.; Fanany, M.I.; Jatmiko, W.; Basaruddin, T. A comparative study on Daubechies Wavelet Transformation, Kernel PCA and PCA as feature extractors for arrhythmia detection using SVM. In Proceedings of the TENCON 2011—2011 IEEE Region 10 Conference, Bali, Indonesia, 21–24 November 2011; pp. 5–9. [Google Scholar]
- Jin, H.; Zhang, L.; Liang, W.; Ding, Q. Integrated leakage detection and localization model for gas pipelines based on the acoustic wave method. J. Loss Prev. Process Ind. 2014, 27, 74–88. [Google Scholar]
- Meng, L.; Li, Y.; Wang, W.; Fu, J. Experimental study on leak detection and location for gas pipeline based on acoustic method. J. Loss Prev. Process Ind. 2012, 25, 90–102. [Google Scholar]
- Guo, G.; Yu, X.; Liu, S.; Ma, Z.; Wu, Y.; Xu, X.; Wang, X.; Smith, K.; Wu, X. Leakage Detection in Water Distribution Systems Based on Time–Frequency Convolutional Neural Network. J. Water Resour. Plan. Manag.-ASCE 2021, 147, 04020101. [Google Scholar]
- Shukla, H.; Piratla, K. Leakage detection in water pipelines using supervised classification of acceleration signals. Autom. Constr. 2020, 117, 103256. [Google Scholar]
- Spandonidis, C.; Theodoropoulos, P.; Giannopoulos, F.; Galiatsatos, N.; Petsa, A. Evaluation of deep learning approaches for oil & gas pipeline leak detection using wireless sensor networks. Eng. Appl. Artif. Intell. 2022, 113, 104890. [Google Scholar]
- Li, Q.; Shi, Y.; Lin, R.; Qiao, W.; Ba, W. A novel oil pipeline leakage detection method based on the sparrow search algorithm and CNN. Measurement 2022, 204, 112122. [Google Scholar]
- Spandonidis, C.; Theodoropoulos, P.; Giannopoulos, F. A Combined Semi-Supervised Deep Learning Method for Oil Leak Detection in Pipelines Using IIoT at the Edge. Sensors 2022, 22, 4105. [Google Scholar]
- Zha, W.; Liu, Y.; Wan, Y.; Luo, R.; Li, D.; Yang, S.; Xu, Y. Forecasting monthly gas field production based on the CNN-LSTM model. Energy 2022, 260, 124889. [Google Scholar]
- Loddo, A.; Di Ruberto, C. On the Efficacy of Handcrafted and Deep Features for Seed Image Classification. J. Imaging. 2021, 7, 171. [Google Scholar] [PubMed]
- Bento, N.; Rebelo, J.; Barandas, M.; Carreiro, A.V.; Campagner, A.; Cabitza, F.; Gamboa, H. Comparing Handcrafted Features and Deep Neural Representations for Domain Generalization in Human Activity Recognition. Sensors 2022, 22, 7324. [Google Scholar] [PubMed]
- Lin, W.; Hasenstab, K.; Moura Cunha, G.; Schwartzman, A. Comparison of handcrafted features and convolutional neural networks for liver MR image adequacy assessment. Sci. Rep. 2020, 10, 20336. [Google Scholar]
- Galaz, Z.; Drotar, P.; Mekyska, J.; Gazda, M.; Mucha, J.; Zvoncak, V.; Smekal, Z.; Faundez-Zanuy, M.; Castrillon, R.; Orozco-Arroyave, J.R.; et al. Comparison of CNN-Learned vs. Handcrafted Features for Detection of Parkinson’s Disease Dysgraphia in a Multilingual Dataset. Front. Neuroinform. 2022, 16, 877139. [Google Scholar]
- Hughes, L.H.; Schmitt, M.; Mou, L.; Wang, Y.; Zhu, X.X. Identifying Corresponding Patches in SAR and Optical Images With a Pseudo-Siamese CNN. IEEE Geosci. Remote Sens. Lett. 2018, 15, 784–788. [Google Scholar]
- Li, W.; Yang, C.; Peng, Y.; Du, J. A Pseudo-Siamese Deep Convolutional Neural Network for Spatiotemporal Satellite Image Fusion. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2022, 15, 1205–1220. [Google Scholar]
- Gao, J.; Xiao, C.; Glass, L.M.; Sun, J. COMPOSE: Cross-modal pseudo-siamese network for patient trial matching. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 6–10 July 2020; pp. 803–812. [Google Scholar]
- Fan, J.; Yang, X.; Lu, R.; Xie, X.; Wang, S. Psiamrml: Target Recognition and Matching Integrated Localization Algorithm Based on Pseudo-Siamese Network. SSRN Electron. J. 2022. [Google Scholar] [CrossRef]
- Li, Z.; Chen, H.; Ma, X.; Chen, H.; Ma, Z. Triple Pseudo-Siamese network with hybrid attention mechanism for welding defect detection. Mater. Des. 2022, 217, 110645. [Google Scholar]
- Muda, L.; Begam, M.; Elamvazuthi, I. Voice recognition algorithms using mel frequency cepstral coefficient (MFCCs) and dynamic time warping (DTW) techniques. arXiv 2010, arXiv:1003.4083. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar]
- Xia, M.; Li, T.; Xu, L.; Liu, L.; de Silva, C.W. Fault Diagnosis for Rotating Machinery Using Multiple Sensors and Convolutional Neural Networks. IEEE/ASME Trans. Mechatron. 2018, 23, 101–110. [Google Scholar]
- Zhang, W.; Li, C.; Peng, G.; Chen, Y.; Zhang, Z. A deep convolutional neural network with new training methods for bearing fault diagnosis under noisy environment and different working load. Mech. Syst. Signal Proc. 2018, 100, 439–453. [Google Scholar]
- Sahidullah, M.; Saha, G. Design, analysis and experimental evaluation of block based transformation in MFCCs computation for speaker recognition. Speech Commun. 2012, 54, 543–565. [Google Scholar]
- Arunsuriyasak, P.; Boonme, P.; Phasukkit, P. Investigation of deep learning optimizer for water pipe leaking detection. In Proceedings of the 2019 16th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Pattaya, Thailand, 10–13 July 2019; pp. 85–88. [Google Scholar]
- Chuang, W.; Tsai, Y.; Wang, L. Leak detection in water distribution pipes based on CNN with mel frequency cepstral coefficients. In Proceedings of the 2019 3rd International Conference on Innovation in Artificial Intelligence, Suzhou, China, 15–18 March 2019; pp. 83–86. [Google Scholar]
- Xu, T.; Zeng, Z.; Huang, X.; Li, J.; Feng, H. Pipeline leak detection based on variational mode decomposition and support vector machine using an interior spherical detector. Process Saf. Environ. Protect. 2021, 153, 167–177. [Google Scholar]
- Kopparapu, S.K.; Laxminarayana, M. Choice of Mel filter bank in computing MFCCs of a resampled speech. In Proceedings of the 10th International Conference on Information Science, Signal Processing and Their Applications (ISSPA 2010), Kuala Lumpur, Malaysia, 10–13 May 2010; pp. 121–124. [Google Scholar]
- Rao, K.S.; Manjunath, K.E. Speech Recognition Using Articulatory and Excitation Source Features; Springer: New York, NY, USA, 2017. [Google Scholar]
- Zhang, P.; He, J.; Huang, W.; Yuan, Y.; Wu, C.; Zhang, J.; Yuan, Y.; Wang, P.; Yang, B.; Cheng, K.; et al. Ground vibration analysis of leak signals from buried liquid-filled pipes: An experimental investigation. Appl. Acoust. 2022, 200, 109054. [Google Scholar]
- Song, Y.; Li, S. Gas leak detection in galvanised steel pipe with internal flow noise using convolutional neural network. Process Saf. Environ. Protect. 2021, 146, 736–744. [Google Scholar]
- Ding, X.; Zhang, X.; Zhou, Y.; Han, J.; Ding, G.; Sun, J. Scaling up your kernels to 31 × 31: Revisiting large kernel design in cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11963–11975. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Dozat, T. Incorporating Nesterov Momentum into Adam. ICLR 2016 workshop submission. OpenReview.net. 2016. Available online: https://openreview.net/forum?id=OM0jvwB8jIp57ZJjtNEZ (accessed on 1 February 2023).
- Li, L.; Xu, W.; Yu, H. Character-level neural network model based on Nadam optimization and its application in clinical concept extraction. Neurocomputing 2020, 414, 182–190. [Google Scholar]
- Fushiki, T. Estimation of prediction error by using K-fold cross-validation. Stat. Comput. 2011, 21, 137–146. [Google Scholar]
- Krug, A.; Ebrahimzadeh, M.; Alemann, J.; Johannsmeier, J.; Stober, S. Analyzing and Visualizing Deep Neural Networks for Speech Recognition with Saliency-Adjusted Neuron Activation Profiles. Electronics 2021, 10, 1350. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 11. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. arXiv 2013, arXiv:1312.6034. [Google Scholar]
- Arora, S.; Hu, W.; Kothari, P.K. An analysis of the t-sne algorithm for data visualization. In Proceedings of the Conference on Learning Theory, Stockholm, Sweden, 5–9 July 2018; pp. 1455–1462. [Google Scholar]
- Cai, T.T.; Ma, R. Theoretical Foundations of t-SNE for Visualizing High-Dimensional Clustered Data. arXiv 2021, arXiv:2105.07536. [Google Scholar]
- Gong, W.; Chen, H.; Zhang, Z.; Zhang, M.; Wang, R.; Guan, C.; Wang, Q. A Novel Deep Learning Method for Intelligent Fault Diagnosis of Rotating Machinery Based on Improved CNN-SVM and Multichannel Data Fusion. Sensors 2019, 19, 1693. [Google Scholar] [CrossRef] [Green Version]
- Yang, D.; Hou, N.; Lu, J.; Ji, D. Novel leakage detection by ensemble 1DCNN-VAPSO-SVM in oil and gas pipeline systems. Appl. Soft. Comput. 2022, 115, 108212. [Google Scholar]
- Hanin, B.; Sellke, M. Approximating continuous functions by relu nets of minimal width. arXiv 2017, arXiv:1710.11278. [Google Scholar]
- Zhang, W.; Peng, G.; Li, C.; Chen, Y.; Zhang, Z. A New Deep Learning Model for Fault Diagnosis with Good Anti-Noise and Domain Adaptation Ability on Raw Vibration Signals. Sensors 2017, 17, 425. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xie, Y.; Xiao, Y.; Liu, X.; Liu, G.; Jiang, W.; Qin, J. Time-Frequency Distribution Map-Based Convolutional Neural Network (CNN) Model for Underwater Pipeline Leakage Detection Using Acoustic Signals. Sensors 2020, 20, 5040. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, H.; Tan, D.; Chen, X.; Lei, H. A novel acoustic emission detection module for leakage recognition in a gas pipeline valve. Process Saf. Environ. Protect. 2017, 105, 32–40. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Li, Z.; Ji, Z.; Bi, Z. Intelligent leak level recognition of gas pipeline valve using wavelet packet energy and support vector machine model. Insight-Non-Destr. Test. Cond. Monit. 2013, 55, 670–674. [Google Scholar] [CrossRef]
- Papastefanou, A.S.; Joseph, P.F.; Brennan, M.J. Experimental Investigation into the Characteristics of In-Pipe Leak Noise in Plastic Water Filled Pipes. Acta Acust. United Acust. 2012, 98, 847–856. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Features | Definition | No. | Features | Definition |
|---|---|---|---|---|---|
| 1 | Peak frequency | 4 | Root mean square frequency | ||
| 2 | Frequency center | 5 | Frequency variance | ||
| 3 | Mean square frequency | 6 | Frequency standard deviation |
| No. | Features | Definition | No. | Features | Definition |
|---|---|---|---|---|---|
| 1 | Mean value | 9 | Shape factor | ||
| 2 | Mean absolute value | 10 | Crest factor | ||
| 3 | Root mean square | 11 | Impulse factor | ||
| 4 | Maximum absolute value | 12 | Clearance factor | ||
| 5 | Standard deviation | 13 | Skewness factor | ||
| 6 | Peak-peak value | 14 | Kurtosis factor | ||
| 7 | Skewness | 15 | Margin factor | ||
| 8 | Kurtosis |
| State | Categories | Materials | Burial Depth (m) | Case Number |
|---|---|---|---|---|
| Leak | L1 | Plastic | 0.6~1.2 | 40 |
| L2 | Plastic | 1.2~1.8 | 27 | |
| L3 | Plastic | 1.8~2.4 | 17 | |
| L4 | Metal | 0.6~1.2 | 28 | |
| L5 | Metal | 1.2~1.8 | 21 | |
| L6 | Metal | 1.8~2.4 | 9 | |
| Non-leak | N1 | Plastic | 0.6~1.2 | 40 |
| N2 | Plastic | 1.2~1.8 | 27 | |
| N3 | Plastic | 1.8~2.4 | 17 | |
| N4 | Metal | 0.6~1.2 | 28 | |
| N5 | Metal | 1.2~1.8 | 21 | |
| N6 | Metal | 1.8~2.4 | 9 | |
| N7 (Noise) | / | / | 20 |
| No. | Layers | Kernel Size | Filters Number | Evaluation Criteria (%) | Para. Count | |||
|---|---|---|---|---|---|---|---|---|
| Acc | Sen | Spe | F1-Score | |||||
| 1 | 3 | 7-3-3 | 8-16-32 | 98.88 ± 0.46 | 98.85 ± 0.52 | 98.91 ± 0.64 | 98.88 ± 0.47 | 11,166 |
| 2 | 3 | 5-3-3 | 8-16-32 | 98.68 ± 0.29 | 99.23 ± 0.36 | 98.21 ± 0.57 | 98.65 ± 0.30 | 11,150 |
| 3 | 3 | 9-3-3 | 8-16-32 | 98.62 ± 0.35 | 99.13 ± 0.30 | 98.17 ± 0.59 | 98.58 ± 0.36 | 10,542 |
| 4 | 3 | 11-3-3 | 8-16-32 | 98.51 ± 0.65 | 98.97 ± 0.32 | 98.11 ± 1.12 | 98.47 ± 0.68 | 10,558 |
| 5 | 3 | 15-3-3 | 8-16-32 | 98.11 ± 0.85 | 98.62 ± 0.87 | 97.67 ± 1.11 | 98.07 ± 0.87 | 9950 |
| 6 | 3 | 7-3-3 | 16-32-64 | 99.35 ± 0.17 | 99.62 ± 0.24 | 99.12 ± 0.34 | 99.33 ± 0.17 | 26,110 |
| 7 | 3 | 7-3-3 | 32-64-128 | 99.24 ± 0.20 | 99.53 ± 0.26 | 98.99 ± 0.36 | 99.22± 0.21 | 67,518 |
| 8 | 2 | 7-3 | 16-32 | 97.98 ± 0.84 | 97.96 ± 0.99 | 98.00 ± 0.99 | 97.97 ± 0.85 | 19,774 |
| 9 | 5 | 7-3-3-3-3 | 16-32-64-64-64 | 99.19 ± 0.26 | 99.51 ± 0.34 | 98.91 ± 0.45 | 99.16 ± 0.29 | 51,070 |
| 10 | 5 * | 7-3-3-3-3 | 16-32-64-64-64 | 99.34 ± 0.29 | 99.88 ± 0.12 | 98.87 ± 0.55 | 99.31 ± 0.31 | 51,070 |
| 11 | 7 | 7-3-3-3-3-3-3 | 16-32-64-64-64-64-64 | 98.98 ± 0.60 | 99.37 ± 0.55 | 98.64 ± 0.80 | 98.95 ± 0.62 | 76,030 |
| 12 | 7 * | 7-3-3-3-3-3-3 | 16-32-64-64-64-64-64 | 99.16 ± 0.36 | 99.55 ± 0.19 | 98.81 ± 0.66 | 99.13 ± 0.38 | 76,030 |
| No. | Layers | Kernel Size | Filters Number | Evaluation Criteria (%) | Para. Count | |||
|---|---|---|---|---|---|---|---|---|
| Acc | Sen | Spe | F1-Score | |||||
| 1 | 3 | 50-10-3 | 16-32-64 | 95.88 ± 1.36 | 95.87 ± 2.02 | 95.88 ± 1.60 | 95.86 ± 1.36 | 71,342 |
| 2 | 3 | 30-10-3 | 16-32-64 | 94.67 ± 1.74 | 94.20 ± 2.97 | 95.08 ± 2.04 | 94.68 ± 1.71 | 71,022 |
| 3 | 3 | 100-10-3 | 16-32-64 | 96.28 ± 1.02 | 96.29 ± 1.04 | 96.28 ± 1.40 | 96.26 ± 1.03 | 72,142 |
| 4 | 3 | 200-10-3 | 16-32-64 | 97.84 ± 0.82 | 97.28 ± 0.95 | 98.33 ± 1.18 | 97.86 ± 0.84 | 71,182 |
| 5 | 3 | 500-10-3 | 16-32-64 | 98.42 ± 0.56 | 98.71 ± 0.59 | 98.17 ± 0.79 | 98.39 ± 0.58 | 72,142 |
| 6 | 3 | 1000-10-3 | 16-32-64 | 98.19 ± 0.60 | 98.64 ± 0.81 | 97.80 ± 0.80 | 98.15 ± 0.61 | 71,182 |
| 7 | 3 | 500-3-3 | 16-32-64 | 98.15 ± 0.67 | 98.73 ± 0.85 | 97.63 ± 0.65 | 98.10 ± 0.66 | 72,398 |
| 8 | 3 | 500-5-3 | 16-32-64 | 98.27 ± 0.34 | 97.93 ± 0.65 | 98.56 ± 0.64 | 98.28 ± 0.35 | 72,142 |
| 9 | 3 | 500-20-3 | 16-32-64 | 98.22 ± 0.80 | 98.47 ± 0.41 | 98.00 ± 1.46 | 98.20 ± 0.83 | 70,862 |
| 10 | 3 | 500-10-3 | 32-64-128 | 98.43 ± 0.41 | 98.57 ± 0.88 | 98.31 ± 0.52 | 98.41 ± 0.40 | 166,750 |
| 11 | 3 | 500-10-3 | 8-16-32 | 97.17 ± 0.84 | 97.02 ± 1.54 | 97.30 ± 0.96 | 97.16 ± 0.83 | 33,286 |
| 12 | 2 | 500-10 | 16-32 | 97.41 ± 0.98 | 96.78 ± 1.92 | 97.96 ± 1.21 | 97.44 ± 0.96 | 65,806 |
| 13 | 5 | 500-10-3-3-3 | 16-32-64-64-64 | 98.26 ± 0.39 | 99.06 ± 0.47 | 97.55 ± 0.78 | 98.20 ± 0.41 | 97,102 |
| 14 | 5 * | 500-10-3-3-3 | 16-32-64-64-64 | 98.45 ± 0.61 | 98.80 ± 0.66 | 98.15 ± 0.76 | 98.42 ± 0.61 | 97,102 |
| 15 | 7 | 500-10-3-3-3-3-3 | 16-32-64-64-64-64-64 | 98.11 ± 0.62 | 98.90 ± 0.42 | 97.43 ± 1.09 | 98.06 ± 0.64 | 122,062 |
| 16 | 7* | 500-10-3-3-3-3-3 | 16-32-64-64-64-64-64 | 98.23 ± 0.54 | 98.57 ± 0.41 | 97.94 ± 1.02 | 98.21 ± 0.57 | 122,062 |
| No. | Layers | Residual Connection | Evaluation Criteria (%) | Para. Count | |||
|---|---|---|---|---|---|---|---|
| Acc | Sen | Spe | F1-Score | ||||
| 1 | 2 | Yes | 99.70 ± 0.12 | 99.93 ± 0.15 | 99.51 ± 0.21 | 99.69 ± 0.13 | 123,150 |
| 2 | 2 | No | 99.50 ± 0.17 | 99.72 ± 0.18 | 99.30 ± 0.25 | 99.48 ± 0.18 | 123,150 |
| 3 | 4 | Yes | 99.46 ± 0.20 | 99.44 ± 0.22 | 99.49 ± 0.31 | 99.46 ± 0.21 | 148,110 |
| 4 | 4 | No | 99.27 ± 0.27 | 99.62 ± 0.11 | 98.95 ± 0.47 | 99.24 ± 0.28 | 148,110 |
| 5 | 6 | Yes | 99.44 ± 0.22 | 99.74 ± 0.16 | 99.18 ± 0.40 | 99.42 ± 0.23 | 173,070 |
| Input | Method | Evaluation Criteria (%) | |||
|---|---|---|---|---|---|
| Acc | Sen | Spe | F1-Score | ||
| Raw signals | CNN [49] | 98.45 ± 0.61 | 98.80 ± 0.66 | 98.15 ± 0.76 | 98.42 ± 0.61 |
| Raw signals | EEMD+CNN [64] | 98.04 ± 0.56 | 97.14 ± 1.07 | 98.83 ± 0.40 | 98.08 ± 0.53 |
| Raw signals | Ensemble 1D-CNN-SVM [18] | 98.87 ± 0.26 | 99.20 ± 0.35 | 98.58 ± 0.46 | 98.84± 0.26 |
| 2D MFCCs | CNN [44] | 98.59 ± 0.49 | 99.37 ± 0.26 | 97.90 ± 0.82 | 98.54 ± 0.51 |
| TFD features | KPCA-SVM [65] | 94.97 ± 1.70 | 95.05 ± 2.24 | 94.90 ± 2.31 | 94.94 ± 1.71 |
| Wavelet features | SVM [66] | 95.61 ± 1.44 | 95.33 ± 1.66 | 95.86 ± 2.02 | 95.61 ± 1.47 |
| MFCCs + TFD features + Raw signals | PCNN | 99.70 ± 0.12 | 99.93 ± 0.15 | 99.51 ± 0.21 | 99.69 ± 0.13 |
| Method | Evaluation Criteria (%) | |||
|---|---|---|---|---|
| Acc | Sen | Spe | F1-Score | |
| PCNN-MLP | 99.58 ± 0.19 | 99.81 ± 0.14 | 99.38 ± 0.31 | 99.57 ± 0.20 |
| PCNN-MFCCs&Raw | 99.64 ± 0.20 | 99.86 ± 0.11 | 99.44 ± 0.29 | 99.62 ± 0.20 |
| PCNN-TFD&Raw | 99.28 ± 0.23 | 99.72 ± 0.20 | 98.89 ± 0.33 | 99.25 ± 0.23 |
| PCNN-Raw&Raw | 98.28 ± 0.63 | 98.80 ± 0.60 | 97.82 ± 0.53 | 98.24 ± 0.64 |
| CNN-MFCCs | 98.90 ± 0.40 | 99.39 ± 0.26 | 98.48 ± 0.67 | 98.87 ± 0.42 |
| CNN-TFD | 94.32 ± 0.76 | 95.77 ± 1.46 | 96.79 ± 1.21 | 96.33 ± 0.76 |
| CNN-MFCCs&TFD | 99.27 ± 0.27 | 99.25 ± 0.40 | 99.28 ± 0.36 | 99.26 ± 0.28 |
| CNN-Raw | 98.45 ± 0.61 | 98.80 ± 0.66 | 98.15 ± 0.76 | 98.42 ± 0.61 |
| PCNN | 99.70 ± 0.12 | 99.93 ± 0.15 | 99.51 ± 0.21 | 99.69 ± 0.13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, P.; He, J.; Huang, W.; Zhang, J.; Yuan, Y.; Chen, B.; Yang, Z.; Xiao, Y.; Yuan, Y.; Wu, C.; et al. Water Pipeline Leak Detection Based on a Pseudo-Siamese Convolutional Neural Network: Integrating Handcrafted Features and Deep Representations. Water 2023, 15, 1088. https://doi.org/10.3390/w15061088
Zhang P, He J, Huang W, Zhang J, Yuan Y, Chen B, Yang Z, Xiao Y, Yuan Y, Wu C, et al. Water Pipeline Leak Detection Based on a Pseudo-Siamese Convolutional Neural Network: Integrating Handcrafted Features and Deep Representations. Water. 2023; 15(6):1088. https://doi.org/10.3390/w15061088
Chicago/Turabian StyleZhang, Peng, Junguo He, Wanyi Huang, Jie Zhang, Yongqin Yuan, Bo Chen, Zhui Yang, Yuefei Xiao, Yixing Yuan, Chenguang Wu, and et al. 2023. "Water Pipeline Leak Detection Based on a Pseudo-Siamese Convolutional Neural Network: Integrating Handcrafted Features and Deep Representations" Water 15, no. 6: 1088. https://doi.org/10.3390/w15061088