

Ensemble Empirical Mode Decomposition and a Long Short-Term Memory Neural Network for Surface Water Quality Prediction of the Xiaofu River, China

Abstract
:
1. Introduction
2. Study Area and Data
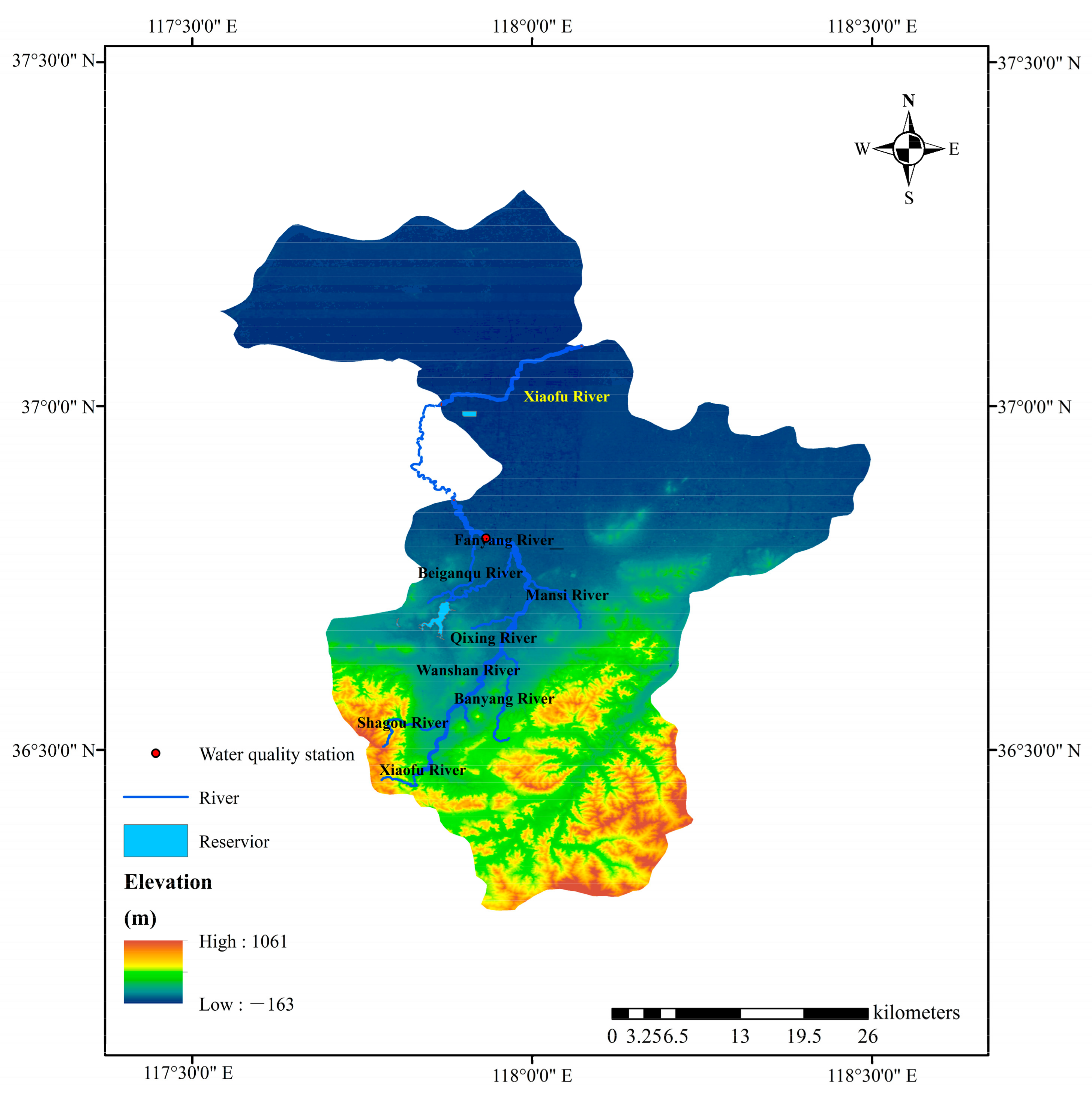
2.1. Study Area
2.2. Data Sources
3. Method
3.1. Ensemble Empirical Mode Decomposition (EEMD)
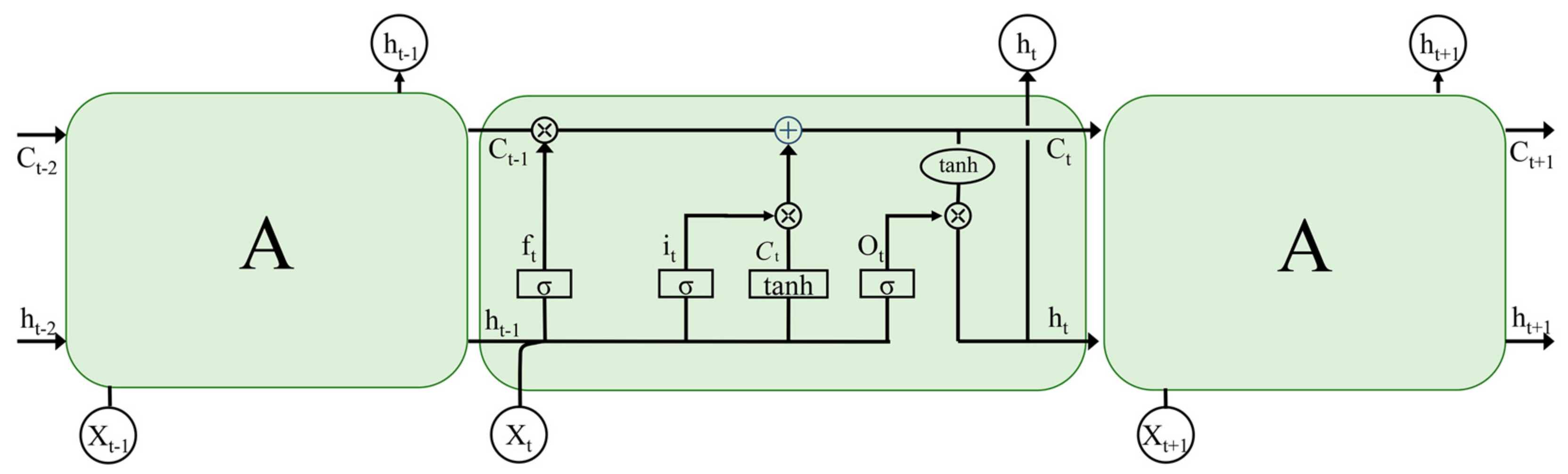
3.2. Long Short-Term Memory (LSTM)
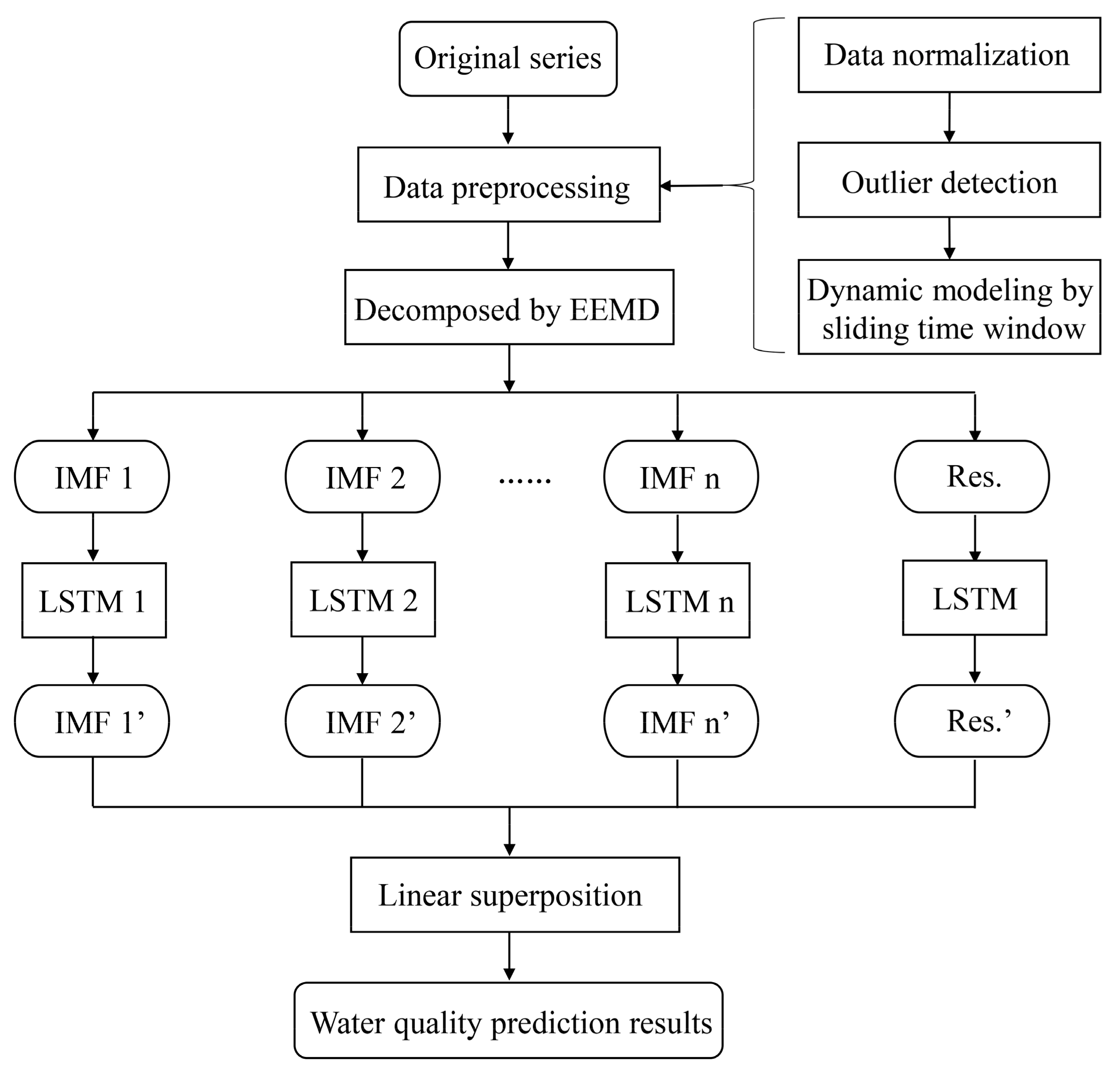
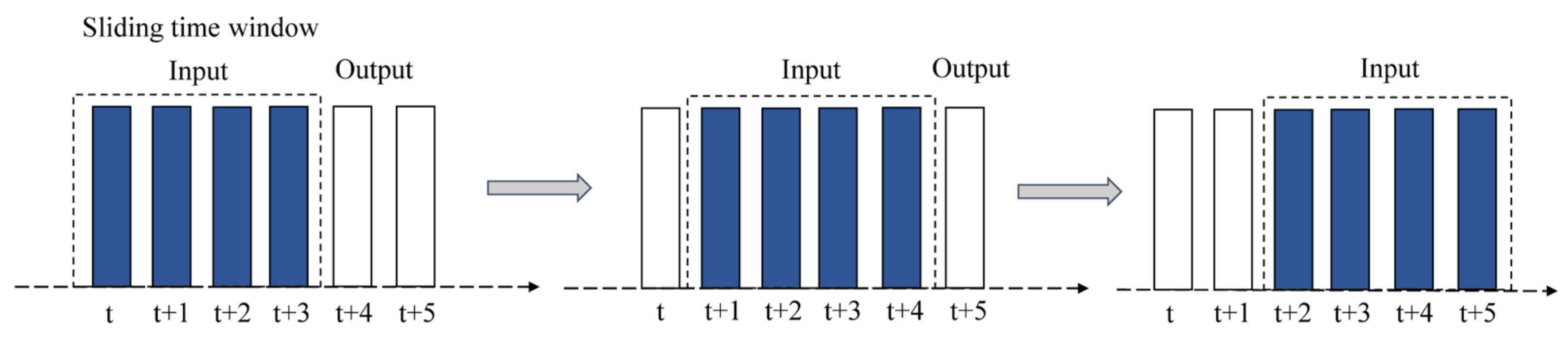
3.3. Data Preprocessing
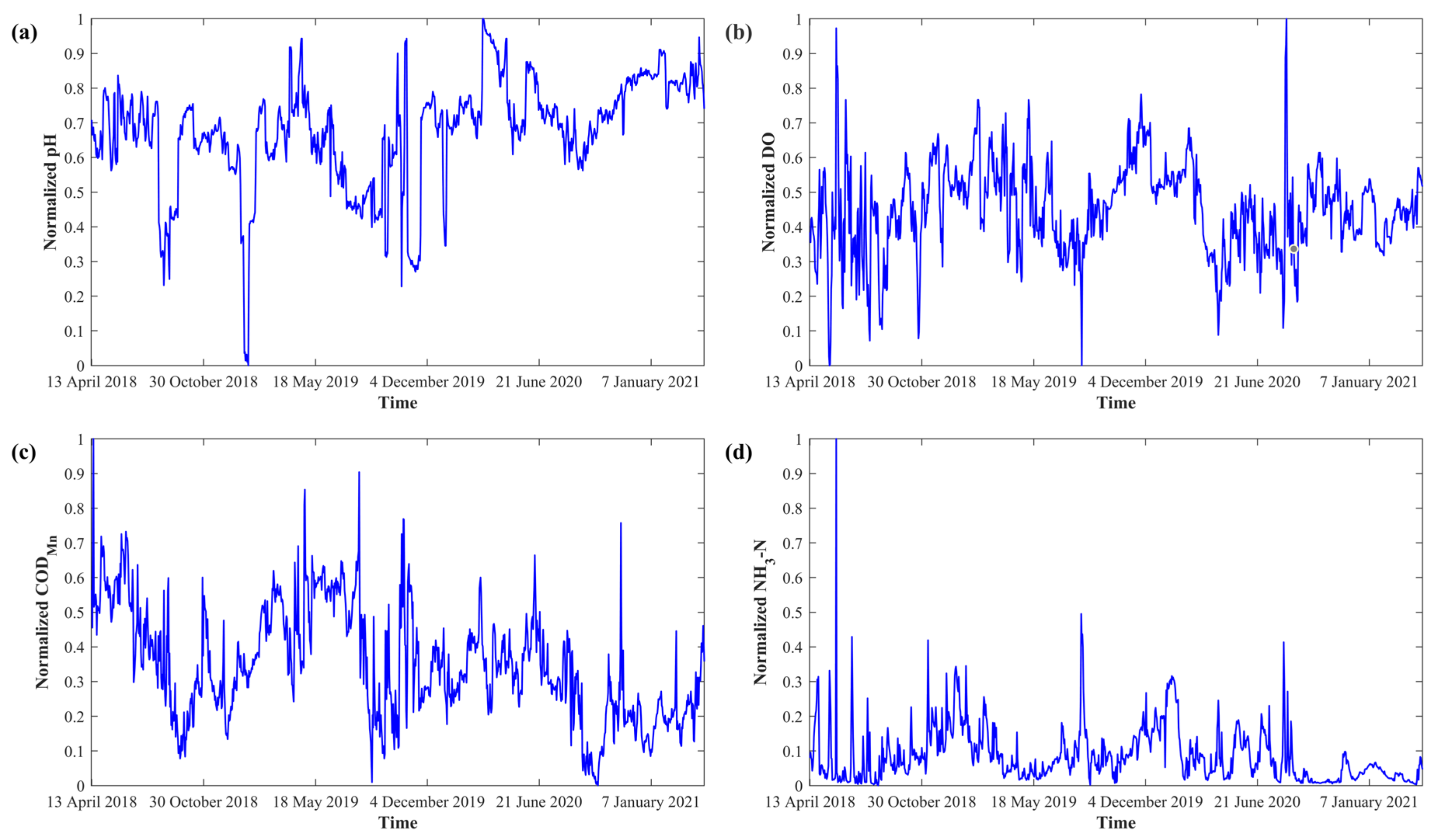
3.3.1. Data Normalization
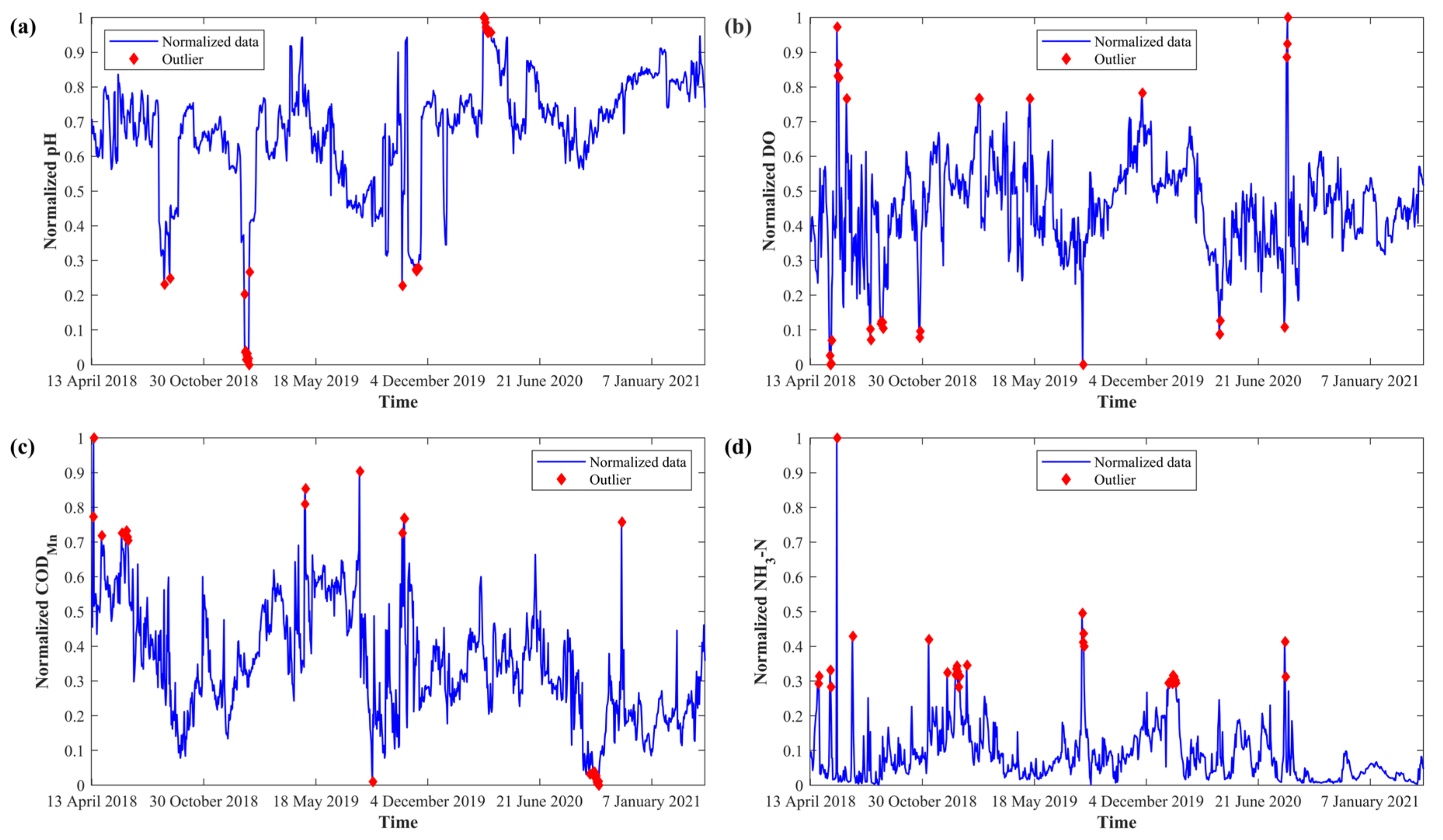
3.3.2. Outlier Detection
- (1)
- If the anomaly score is very close to 1, then the data are definitely anomalies.
- (2)
- If the anomaly score is much smaller than 0.5, then it is safe to regard the data as normal instances.
- (3)
- If all the anomaly scores are approximately 0.5, then there are no distinct outliers in the sample.
3.4. Performance Evaluation
4. Results
4.1. Data Preprocessing
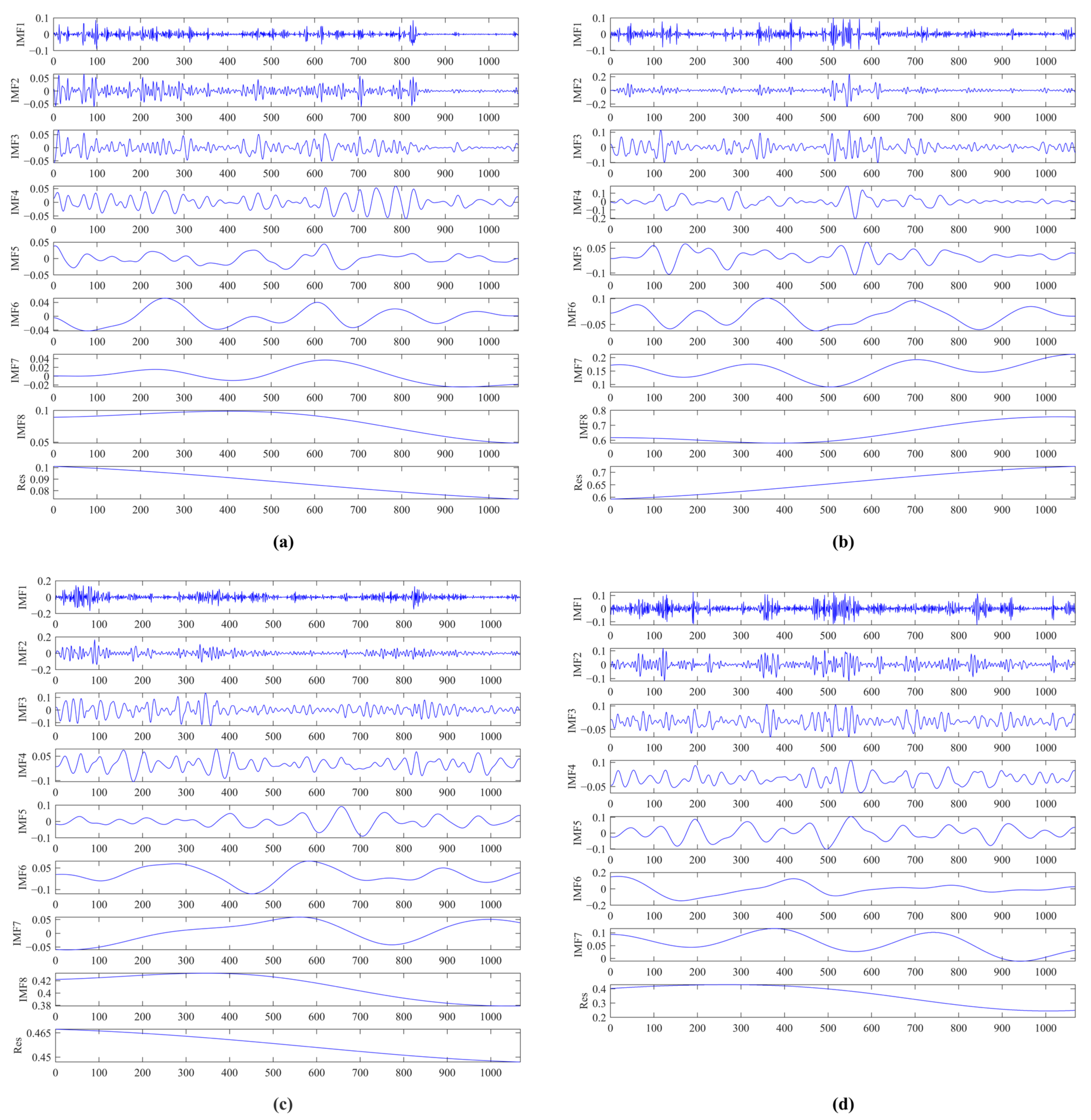
4.2. EEMD Decomposition Results
4.3. Model Training and Parameter Optimization
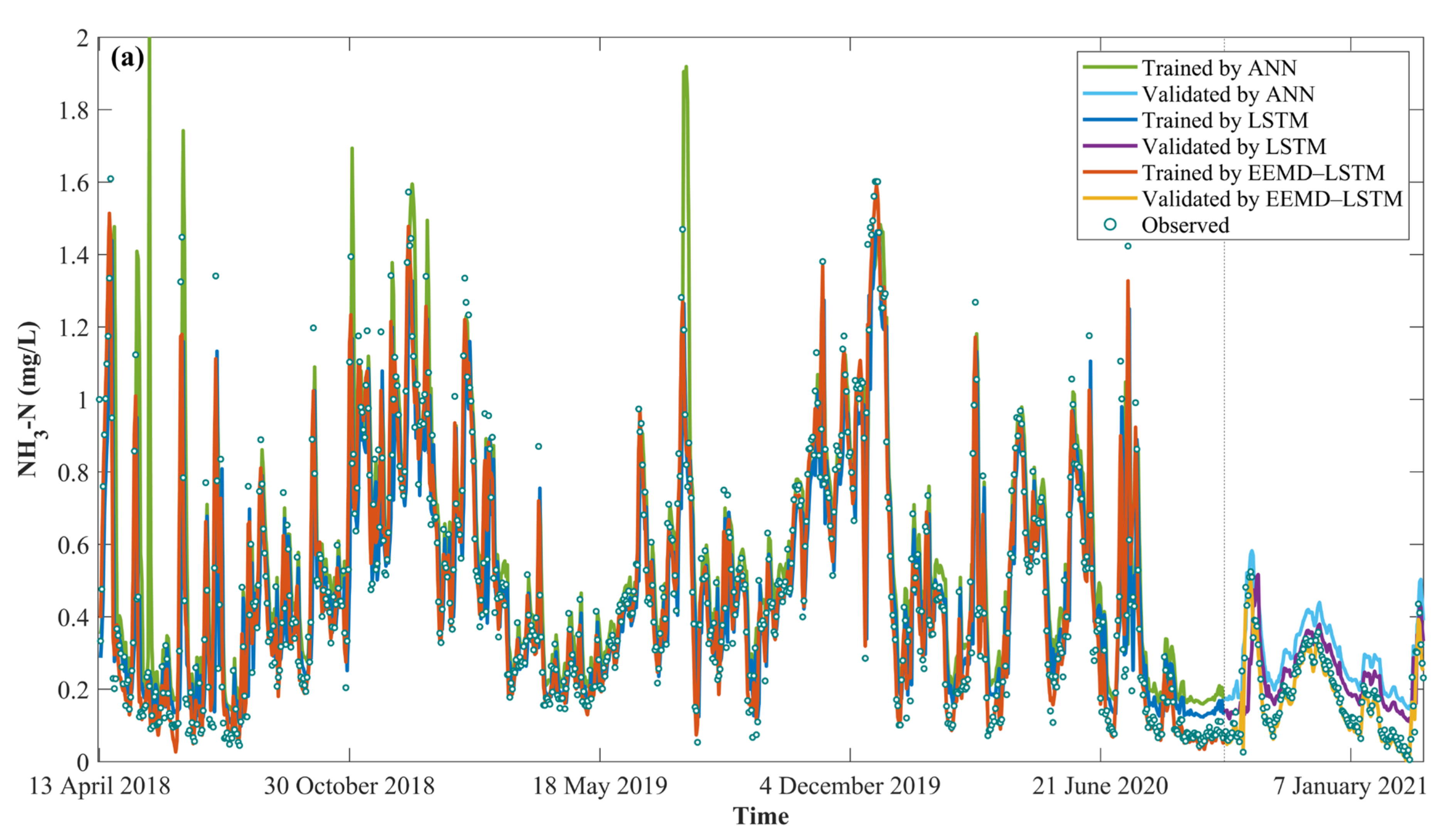
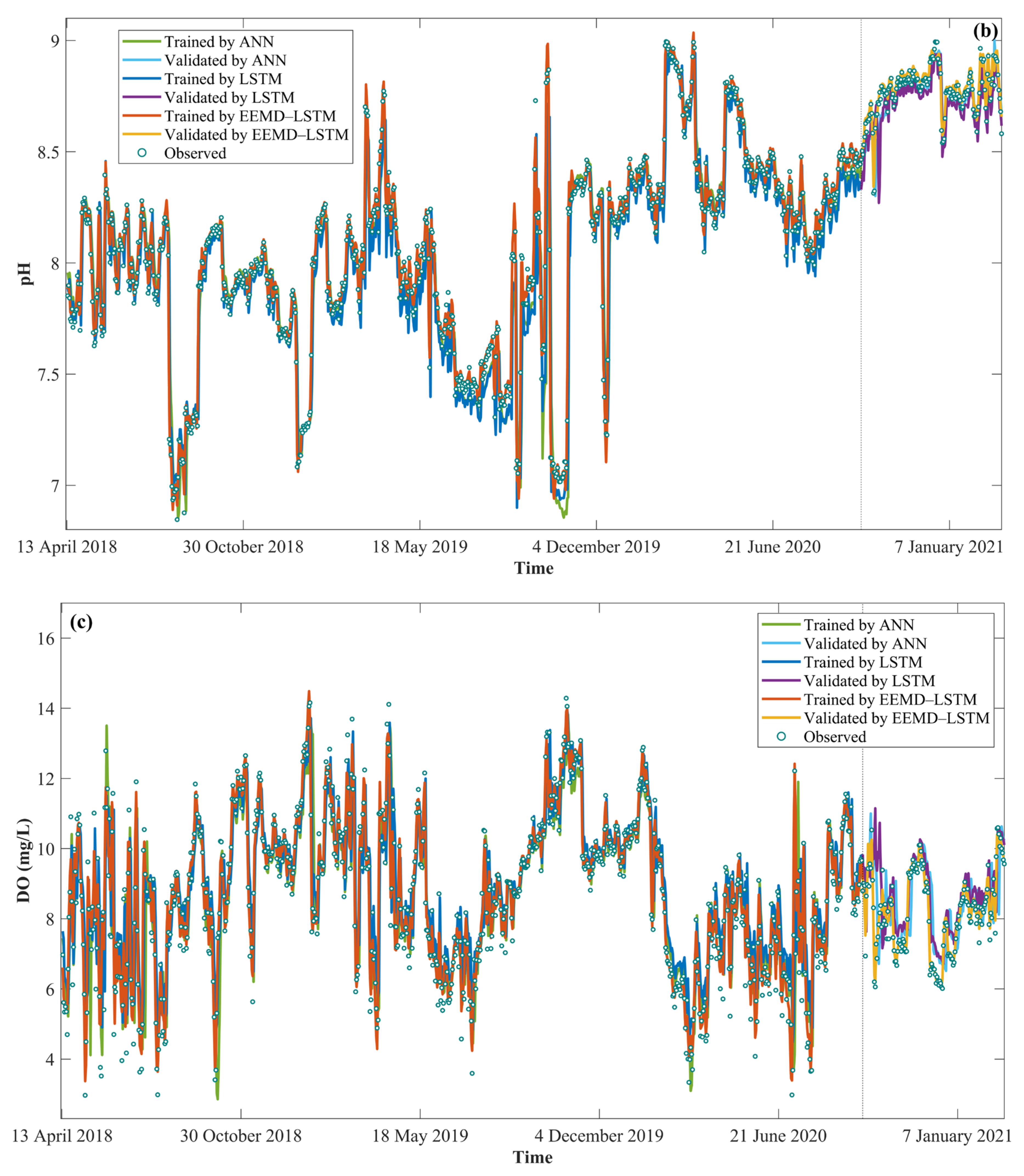
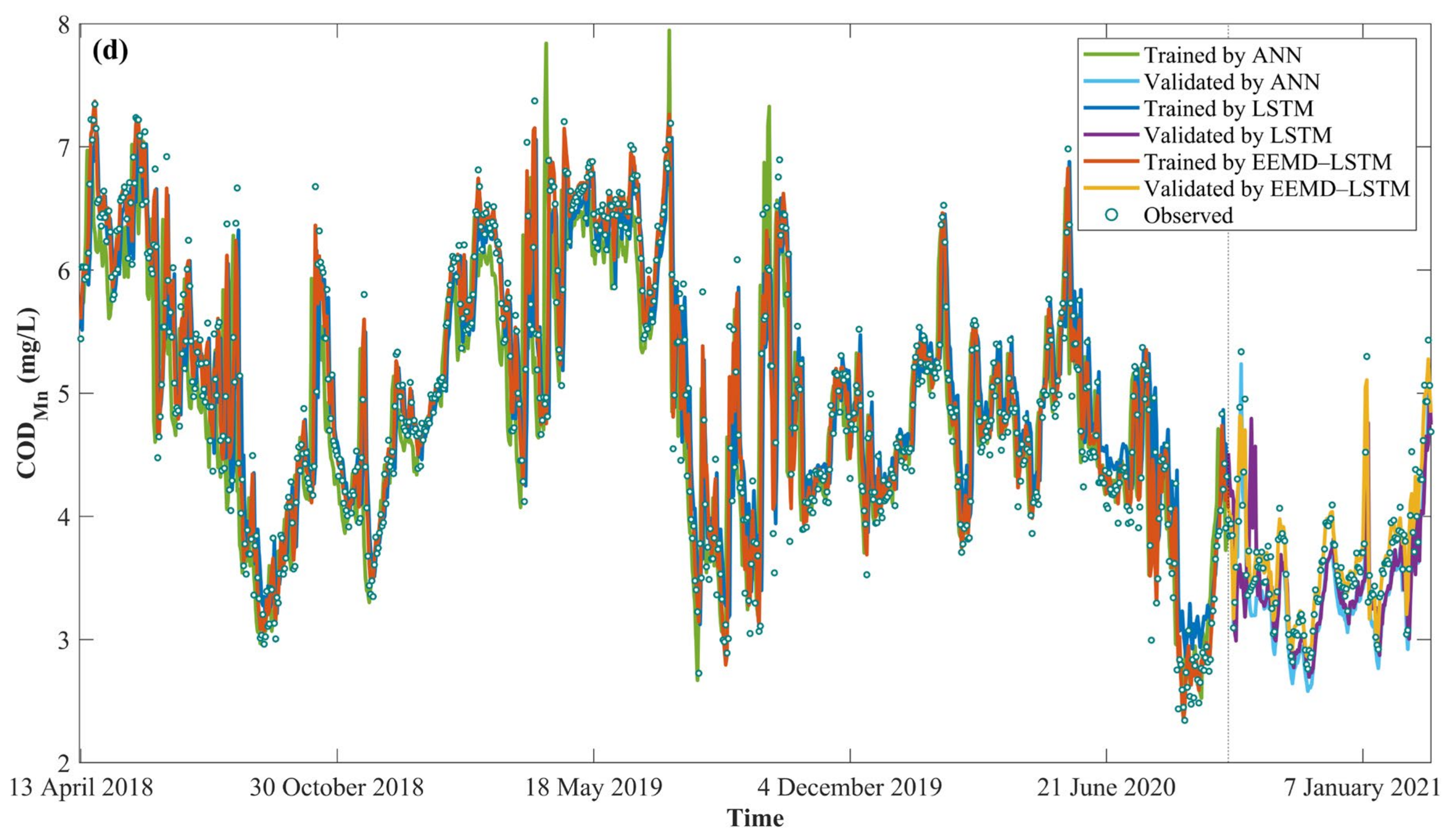
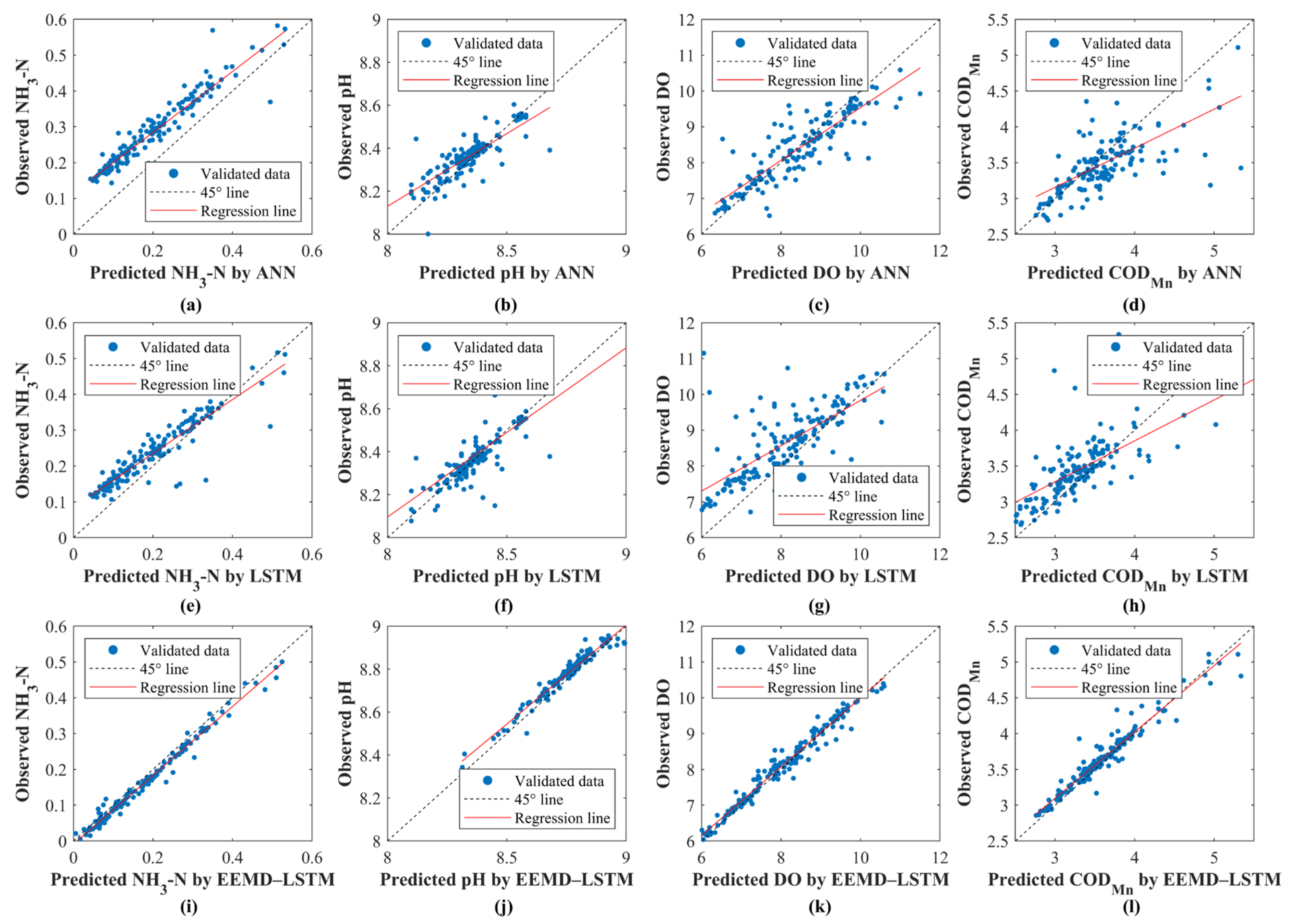
4.4. Water Quality Prediction by EEMD–LSTM
5. Discussion
6. Conclusions
- (1)
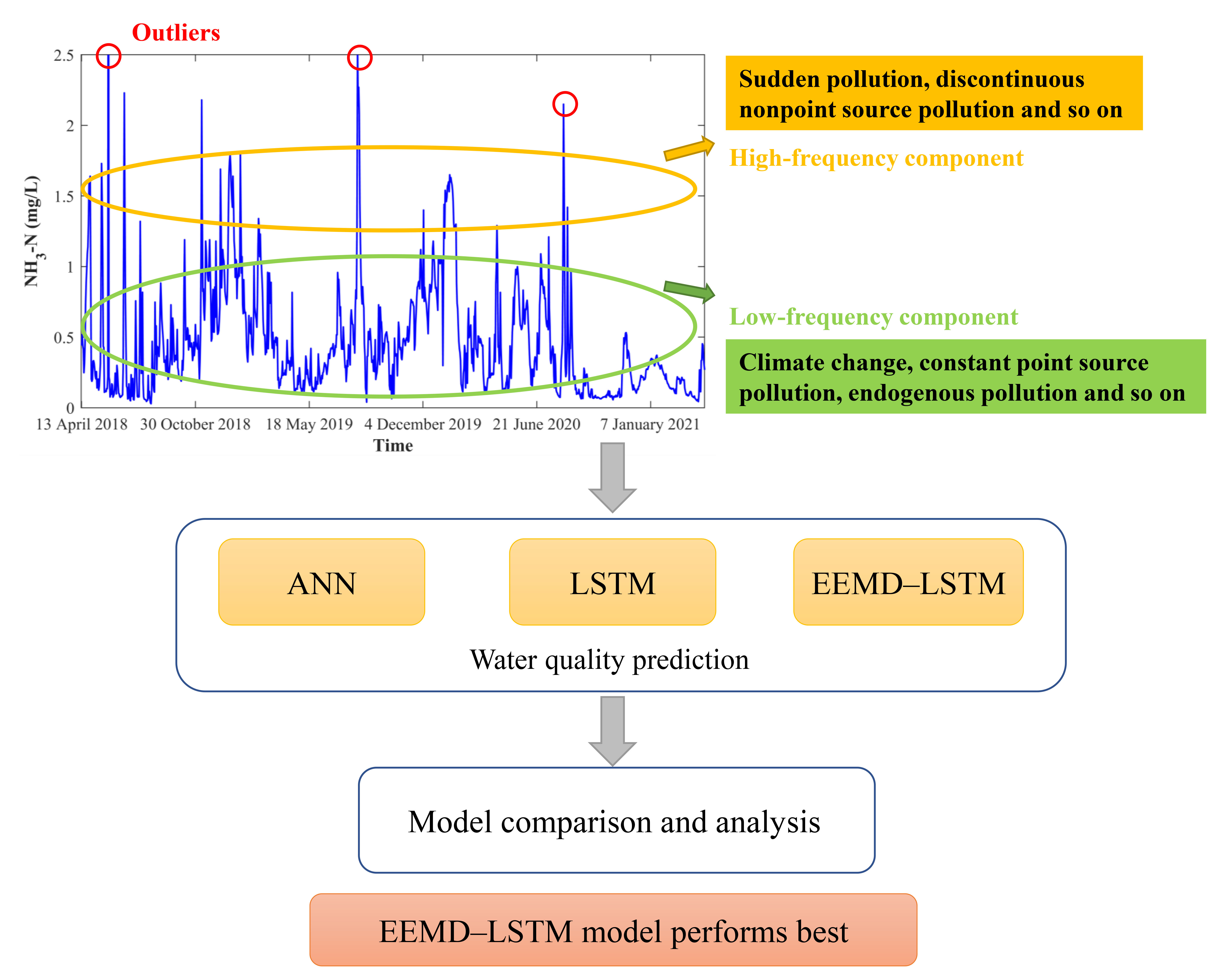
- The EEMD method can decompose time series into components arranged from high frequency to low frequency. In this study, it is used to decompose the water quality time series to obtain several single-period components, which can effectively reduce the complexity and nonlinearity of the original time series. Among all components, the high-frequency components have the greatest impact on the accuracy of water quality prediction. Predicting the high-frequency components and the low-frequency components separately when using LSTM can significantly improve model accuracy.
- (2)
- Compared with LSTM, EEMD–LSTM significantly improves the accuracy of water quality prediction and greatly improves the model performance in terms of the hysteresis problem. During the validation period, the RMSE, MAE, MAPE and R2 of EEMD–LSTM for NH3-N were 0.022 mg/L, 0.019 mg/L, 3.150% and 0.924, respectively. The RMSE, MAE, MAPE and R2 of EEMD-LSTM for pH were 0.035 mg/L, 0.029 mg/L, 0.273% and 0.965, respectively. The RMSE, MAE, MAPE and R2 of EEMD-LSTM for DO were 0.224 mg/L, 0.161 mg/L, 0.994% and 0.961, respectively. The RMSE, MAE, MAPE and R2 of the EEMD-LSTM for CODMn were 0.133 mg/L, 0.085 mg/L, 2.219% and 0.936, respectively. This shows that EEMD–LSTM has high prediction accuracy and strong generalization ability. In addition, the predicted values of EEMD–LSTM are closer to the observed values in the extreme value prediction.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tang, W.; Pei, Y.; Zheng, H.; Zhao, Y.; Shu, L.; Zhang, H. Twenty years of China's water pollution control: Experiences and challenges. Chemosphere 2022, 295, 133875. [Google Scholar] [CrossRef] [PubMed]
- Xiong, Y.; Ran, Y.; Zhao, S.; Zhao, H.; Tian, Q. Remotely assessing and monitoring coastal and inland water quality in China: Progress, challenges and outlook. Crit. Rev. Environ. Sci. Technol. 2020, 50, 1266–1302. [Google Scholar] [CrossRef]
- Liang, Z.; Zou, R.; Chen, X.; Ren, T.; Su, H.; Liu, Y. Simulate the forecast capacity of a complicated water quality model using the long short-term memory approach. J. Hydrol. 2022, 581, 124432. [Google Scholar] [CrossRef]
- Yu, J.; Kim, J.; Li, X.; Jong, Y.; Kim, K.; Ryang, G. Water quality forecasting based on data decomposition, fuzzy clustering and deep learning neural network. Environ. Pollut. 2022, 303, 119136. [Google Scholar] [CrossRef]
- Bui, H.H.; Ha, N.H.; Nguyen, T.N.D.; Nguyen, A.T.; Pham, T.T.H.; Kandasamy, J.; Tien, V.N. Integration of SWAT and QUAL2K for water quality modeling in a data scarce basin of Cau River basin in Vietnam. Ecohydrol. Hydrobiol. 2019, 19, 210–223. [Google Scholar] [CrossRef]
- Bai, J.; Zhao, J.; Zhang, Z.; Tian, Z. Assessment and a review of research on surface water quality modeling. Ecol. Model. 2022, 466, 109888. [Google Scholar] [CrossRef]
- Qin, Z.; He, Z.; Wu, G.; Tang, G.; Wang, Q. Developing Water-Quality Model for Jingpo Lake Based on EFDC. Water 2022, 14, 2596. [Google Scholar] [CrossRef]
- Kang, M.; Tian, Y.; Zhang, H.; Wan, C. Effect of hydrodynamic conditions on the water quality in urban landscape water. Water Supply 2021, 22, 309–320. [Google Scholar] [CrossRef]
- Samaneh, A.; Sedghi, H.; Hassonizadeh, H.; Babazadeh, H. Application of Water Quality Index and Water Quality Model QUAL2K for Evaluation of Pollutants in Dez River, Iran. Water Resour. 2021, 47, 892–903. [Google Scholar] [CrossRef]
- Obin, N.; Tao, H.; Ge, F.; Liu, X. Research on Water Quality Simulation and Water Environmental Capacity in Lushui River Based on WASP Model. Water 2021, 13, 2819. [Google Scholar] [CrossRef]
- Shabani, A.; Zhang, X.; Chu, X.; Zheng, H. Automatic calibration for CE-QUAL-W2 model using improved global-best harmony search algorithm. Water 2021, 13, 2308. [Google Scholar] [CrossRef]
- Mendes, J.; Ruela, R.; Picado, A.; Pinheiro, J.P.; Ribeiro, A.S.; Pereira, H.; Dias, J.M. Modeling dynamic processes of Mondego Estuary and Oacute, Bidos Lagoon using Delft3D. J. Mar. Sci. Technol. 2021, 9, 91. [Google Scholar] [CrossRef]
- Da Silva Burigato Costa, C.M.; Leite, I.R.; Almeida, A.K.; de Almeida, I.K. Choosing an appropriate water quality model-a review. Environ. Monit. Assess. 2021, 193, 38. [Google Scholar] [CrossRef] [PubMed]
- Ejigu, M.T. Overview of water quality modeling. Cogent Eng. 2021, 8, 1891711. [Google Scholar] [CrossRef]
- Achite, M.; Farzin, S.; Elshaboury, N.; Valikhan Anaraki, M.; Amamra, M.; Toubal, A.K. Modeling the optimal dosage of coagulants in water treatment plants using various machine learning models. Environ. Dev. Sustain. 2022, 1–27. [Google Scholar] [CrossRef]
- Farzin, S.; Anaraki, M.V.; Naeimi, M.; Zandifar, S. Prediction of groundwater table and drought analysis; a new hybridization strategy based on bi-directional long short-term model and the Harris hawk optimization algorithm. J. Water Clim. Chang. 2022, 13, 2233–2254. [Google Scholar] [CrossRef]
- Valikhan Anaraki, M.; Mahmoudian, F.; Nabizadeh Chianeh, F.; Farzin, S. Dye Pollutant Removal from Synthetic Wastewater: A New Modeling and Predicting Approach Based on Experimental Data Analysis, Kriging Interpolation Method, and Computational Intelligence Techniques. J. Environ. Inform. 2022, 40, 84–94. [Google Scholar] [CrossRef]
- Kourgialas, N.N.; Dokou, Z.; Karatzas, G.P. Statistical analysis and ANN modeling for predicting hydrological extremes under climate change scenarios: The example of a small mediterranean agro-watershed. J. Environ. Manag. 2015, 154, 86–101. [Google Scholar] [CrossRef]
- Yang, S.; Yang, D.; Chen, J.; Santisirisomboon, J.; Lu, W.; Zhao, B. A physical process and machine learning combined hydrological model for daily streamflow simulations of large watersheds with limited observation data. J. Hydrol. 2020, 590, 125206. [Google Scholar] [CrossRef]
- Zema, D.A.; Lucas-Borja, M.E.; Fotia, L.; Rosaci, D.; Sarne, G.M.L.; Zimbone, S.M. Predicting the hydrological response of a forest after wildfire and soil treatments using an Artificial Neural Network. Comput. Electron. Agric. 2020, 170, 105280. [Google Scholar] [CrossRef]
- Lee, J.H.; Lee, J.Y.; Lee, M.H.; Lee, M.Y.; Kim, Y.W.; Hyung, J.S.; Kim, K.B.; Cha, Y.K.; Koo, J.Y. Development of a short-term water quality prediction model for urban rivers using real-time water quality data. Water Supply 2022, 22, 4082–4097. [Google Scholar] [CrossRef]
- Seo, I.W.; Yun, S.H.; Choi, S.Y. Forecasting water quality parameters by ANN model using pre-processing technique at the downstream of Cheongpyeong Dam. Procedia Eng. 2016, 154, 1110–1115. [Google Scholar] [CrossRef]
- An, L.; Hao, Y.; Yeh, T.J.; Liu, Y.; Liu, W.; Zhang, B. Simulation of karst spring discharge using a combination of time-frequency analysis methods and long short-term memory neural networks. J. Hydrol. 2020, 589, 125320. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Zheng, L.; Wang, H.; Liu, C.; Zhang, S.; Ding, A.; Xie, E.; Li, J.; Wang, S. Prediction of harmful algal blooms in large water bodies using the combined EFDC and LSTM models. J. Environ. Manag. 2021, 295, 113060. [Google Scholar] [CrossRef] [PubMed]
- Eze, E.; Halse, S.; Ajmal, T. Developing a novel water quality prediction model for a South African aquaculture farm. Water 2021, 13, 1782. [Google Scholar] [CrossRef]
- Zhou, J.; Wang, J.; Chen, Y.; Li, X.; Xie, Y. Water quality prediction method based on multi-source transfer learning for water environmental IoT system. Sensors 2021, 21, 7271. [Google Scholar] [CrossRef]
- Tant, C.J.; Rosemond, A.D.; Helton, A.M.; First, M.R. Nutrient enrichment alters the magnitude and timing of fungal, bacterial, and detritivore contributions to litter breakdown. Freshw. Sci. 2015, 34, 1259–1271. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.; Shih, H.H.; Zheng, Q.N.; Yen, N.C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. London. Ser. A Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Zhaohua, W.U.; Norden, E.H. Ensemble empirical mode decomposition: A noise-assisted data analysis method. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Wang, J.; Wang, X.; Lei, X.H.; Wang, H.; Zhang, X.H.; You, J.J.; Tan, Q.F.; Liu, X.L. Teleconnection analysis of monthly streamflow using ensemble empirical mode decomposition. J. Hydrol. 2020, 582, 124411. [Google Scholar] [CrossRef]
- Niu, W.; Feng, Z.; Zeng, M.; Feng, B.; Min, Y.; Cheng, C.; Zhou, J. Forecasting reservoir monthly runoff via ensemble empirical mode decomposition and extreme learning machine optimized by an improved gravitational search algorithm. Appl. Soft Comput. 2019, 82, 105589. [Google Scholar] [CrossRef]
- Huan, J.; Cao, W.; Qin, Y. Prediction of dissolved oxygen in aquaculture based on EEMD and LSSVM optimized by the Bayesian evidence framework. Comput. Electron. Agric. 2018, 150, 257–265. [Google Scholar] [CrossRef]
- Qingmei, M.; Min, L.; Aiju, L. Spatial variation and contamination assessment of heavy metals in surface sediments of Xiaofu River. Health Environ. Res. 2013, 6, 785–790. [Google Scholar] [CrossRef]
- Ding, S.; Wang, F.; Sun, X.; Ding, J.; Lu, J. Water environmental functional zoning at county level and environmental contamination carrying capacity accounting in the mainstream of Xiaofu River. Water 2022, 14, 615. [Google Scholar] [CrossRef]
- Zhang, J.L.; Tang, M.G.; Liu, F.; Zhong, Z.S. Vulnerability analysis of groundwater pollution by mining drainage in Zibo coal mine, Shandong Province, China. In International Symposium on Hydrogeology and the Environment; International Atomic Energy Agency: Vienna, Austria, 2000; pp. 157–162. [Google Scholar]
- Singh, D.; Singh, B. Investigating the impact of data normalization on classification performance. Appl. Soft Comput. 2020, 97, 105524. [Google Scholar] [CrossRef]
- Guia, S.S.; Espirito-Santo, A.; Paciello, V.; Abate, F.; Pietrosanto, A. A comparison between FFT and MCT for period measurement with an ARM Microcontroller. In Proceedings of the 2015 IEEE International Instrumentation and Measurement Technology Conference, Pisa, Italy, 11–14 May 2015; pp. 1938–1942. [Google Scholar] [CrossRef]
- ArunKumar, K.E.; Kalaga, D.V.; Kumar, C.M.S.; Kawaji, M.; Brenza, T.M. Forecasting of COVID-19 using deep layer Recurrent Neural Networks (RNNs) with Gated Recurrent Units (GRUs) and Long Short-Term Memory (LSTM) cells. Chaos Solitons Fractals 2021, 146, 110861. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z. Isolation forest. In Proceedings of the 2008 Eighth Ieee International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar] [CrossRef]
- Ren, Y.; Suganthan, P.N.; Srikanth, N. A comparative study of empirical mode decomposition-based short-term wind speed forecasting methods. IEEE Trans. Sustain. Energy 2015, 6, 236–244. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, Y.; Zhang, Q. Comparison of EEMD-ARIMA, EEMD-BP and EEMD-SVM algorithms for predicting the hourly urban water consumption. J. Hydroinform. 2022, 24, 535–558. [Google Scholar] [CrossRef]
- Diederik, P.K.; Jimmy, B. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Xiang, Z.; Yan, J.; Demir, I. A rainfall-runoff model with LSTM-based sequence-to-sequence learning. Water Resour. Res. 2020, 56, e2019WR025326. [Google Scholar] [CrossRef]
- Li, X.J.; Cheng, Z.W.; Yu, Q.B.; Bai, Y.; Li, C. Water-quality prediction using multimodal support vector regression: Case study of Jialing River, China. J. Environ. Eng. 2017, 143, 04017070. [Google Scholar] [CrossRef]
- Ma, L.; Liu, L.; Song, L.L.; Yan, W.M. A study on water pollutant degradation capability affected by water diversion. J. Environ. Prot. Ecol. 2014, 15, 39–47. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Name | Description | Average | Standard Deviation | Maximum Value | Minimum Value | Number of Missing Data |
|---|---|---|---|---|---|---|
| pH | Pondus hydrogenii | 7.912 | 0.437 | 8.83 | 6.02 | 0 |
| DO | Dissolved oxygen (mg/L) | 8.779 | 2.379 | 18.9 | 0.5 | 0 |
| CODMn | Permanganate index (mg/L) | 4.327 | 1.149 | 9 | 1.82 | 1 |
| NH3-N | Ammonia nitrogen (mg/L) | 0.472 | 0.415 | 5.16 | 0.028 | 1 |
| Variable Name | Period (Day) | |||||||
|---|---|---|---|---|---|---|---|---|
| IMF1 | IMF2 | IMF3 | IMF4 | IMF5 | IMF6 | IMF7 | IMF8 | |
| NH3-N | 3 | 7 | 38 | 41 | 152 | 356 | 534 | 534 |
| pH | 3 | 7 | 22 | 53 | 89 | 356 | 534 | 534 |
| DO | 5 | 9 | 20 | 42 | 97 | 356 | 356 | 534 |
| CODMn | 4 | 8 | 12 | 59 | 66 | 356 | 356 | - |
| Parameter Name | Number |
|---|---|
| epochs | 100 |
| batch size | 16 |
| number of LSTM layers | 1 |
| number of neurons in the input layer | 1 |
| number of neurons in the hidden layer | 50 |
| number of neurons in the output layer | 1 |
| Water Quality Indicator | Sliding Time Window Width | RMSE (mg/L) | MAE (mg/L) | MAPE (%) | R2 |
|---|---|---|---|---|---|
| NH3-N | 4 | 0.096 | 0.071 | 67.387 | 0.423 |
| 5 | 0.089 | 0.057 | 31.901 | 0.783 | |
| 6 | 0.089 | 0.060 | 42.082 | 0.727 | |
| 7 | 0.089 | 0.059 | 39.477 | 0.746 | |
| 8 | 0.093 | 0.067 | 60.726 | 0.545 | |
| pH | 4 | 0.080 | 0.049 | 1.787 | 0.656 |
| 5 | 0.078 | 0.045 | 1.425 | 0.741 | |
| 6 | 0.078 | 0.046 | 1.521 | 0.722 | |
| 7 | 0.078 | 0.046 | 1.558 | 0.721 | |
| 8 | 0.087 | 0.059 | 1.908 | 0.656 | |
| DO | 4 | 0.590 | 0.420 | 7.831 | 0.769 |
| 5 | 0.587 | 0.424 | 7.600 | 0.772 | |
| 6 | 0.594 | 0.434 | 7.741 | 0.763 | |
| 7 | 0.591 | 0.429 | 7.630 | 0.769 | |
| 8 | 0.588 | 0.422 | 7.628 | 0.777 | |
| CODMn | 4 | 0.246 | 0.167 | 11.041 | 0.748 |
| 5 | 0.247 | 0.168 | 12.646 | 0.724 | |
| 6 | 0.244 | 0.165 | 11.538 | 0.743 | |
| 7 | 0.249 | 0.170 | 10.615 | 0.752 | |
| 8 | 0.243 | 0.165 | 11.701 | 0.744 |
| Model | Water Quality Indicator | Training | Validation | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RMSE (mg/L) | MAE (mg/L) | MAPE (%) | R2 | RMSE (mg/L) | MAE (mg/L) | MAPE (%) | R2 | ||
| ANN | NH3-N | 0.268 | 0.148 | 51.028 | 0.615 | 0.018 | 0.017 | 89.344 | 0.315 |
| pH | 0.167 | 0.107 | 1.393 | 0.851 | 0.026 | 0.017 | 2.106 | 0.627 | |
| DO | 1.311 | 0.889 | 13.245 | 0.713 | 0.031 | 0.022 | 5.022 | 0.757 | |
| CODMn | 0.587 | 0.426 | 8.835 | 0.703 | 0.062 | 0.039 | 19.208 | 0.462 | |
| LSTM | NH3-N | 0.169 | 0.111 | 37.694 | 0.754 | 0.110 | 0.109 | 50.381 | 0.567 |
| pH | 0.136 | 0.080 | 1.032 | 0.872 | 0.122 | 0.113 | 1.554 | 0.657 | |
| DO | 1.151 | 0.826 | 10.807 | 0.733 | 1.027 | 0.820 | 4.685 | 0.817 | |
| CODMn | 0.457 | 0.314 | 7.239 | 0.811 | 0.440 | 0.326 | 13.990 | 0.693 | |
| EEMD–LSTM | NH3-N | 0.077 | 0.050 | 5.419 | 0.950 | 0.022 | 0.019 | 3.150 | 0.924 |
| pH | 0.047 | 0.032 | 0.321 | 0.988 | 0.035 | 0.029 | 0.273 | 0.965 | |
| DO | 0.531 | 0.355 | 2.245 | 0.945 | 0.224 | 0.161 | 0.994 | 0.961 | |
| CODMn | 0.189 | 0.131 | 2.756 | 0.969 | 0.133 | 0.085 | 2.219 | 0.936 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, L.; Zhang, Y.; Dong, W.; Zhang, J.; Zhang, L. Ensemble Empirical Mode Decomposition and a Long Short-Term Memory Neural Network for Surface Water Quality Prediction of the Xiaofu River, China. Water 2023, 15, 1625. https://doi.org/10.3390/w15081625
Luo L, Zhang Y, Dong W, Zhang J, Zhang L. Ensemble Empirical Mode Decomposition and a Long Short-Term Memory Neural Network for Surface Water Quality Prediction of the Xiaofu River, China. Water. 2023; 15(8):1625. https://doi.org/10.3390/w15081625
Chicago/Turabian StyleLuo, Lan, Yanjun Zhang, Wenxun Dong, Jinglin Zhang, and Liping Zhang. 2023. "Ensemble Empirical Mode Decomposition and a Long Short-Term Memory Neural Network for Surface Water Quality Prediction of the Xiaofu River, China" Water 15, no. 8: 1625. https://doi.org/10.3390/w15081625